







1、One-Shot Face Video Re-enactment using Hybrid Latent Spaces of StyleGAN2
StyleGAN的高保真人像生成,已逐渐克服了单样本面部视频驱动重现的低分辨率限制,但这些方法至少依赖于以下其中之一:明确的2D/3D先验,基于光流作为运动描述,现成的编码器等,这限制了它们的性能(例如,不一致的预测,无法捕捉精细的面部细节和饰品,糟糕的通化,伪影)。
本文提出了一个端到端框架,同时支持面部属性编辑,面部运动和变形,以及视频生成的面部身份控制。它使用了一种混合潜空间,分别在StyleGAN2的W+和SS空间中将给定的帧编码。
模型支持使用其他潜在的语义编辑(例如,胡子、年龄、化妆等)生成真实的重演驱动视频。定性和定量分析进行了先进的方法,证明了所提出的方法的优越性。
项目页面位于:https://trevineoorloff.github.io/FaceVideoReenactment_HybridLatents.io/

2、DiffFace: Diffusion-based Face Swapping with Facial Guidance
本文提出一种新的基于扩散模型的人脸交换框架,称为 DiffFace,由训练 ID 条件 DDPM、面部引导采样和目标保留混合组成。
具体而言,在训练过程中,ID 条件 DDPM 被训练生成具有所需身份的面部图像。在采样过程中,使用现成的人脸模型,使模型在忠实保留目标属性的同时传递源身份。在此过程中,为了保留目标图像的背景,额外提出了一种目标保留混合策略。它有助于模型 在传输源面部身份的同时保持目标面部的属性不受噪声影响。此外,无需任何重新训练,模型可以灵活地应用额外的面部引导并自适应地控制 ID 属性权衡以达到预期的结果。
本文声称,这是第一种将扩散模型应用于换脸任务的方法。与之前基于 GAN 的方法相比,通过利用扩散模型进行换脸任务,DiffFace 在训练稳定性、高保真度和可控性等方面取得了更好的优势。大量实验表明, DiffFace 与标准人脸交换基准上的最先进方法相当或优于最先进的方法。
项目页面:https://hxngiee.github.io/DiffFace/
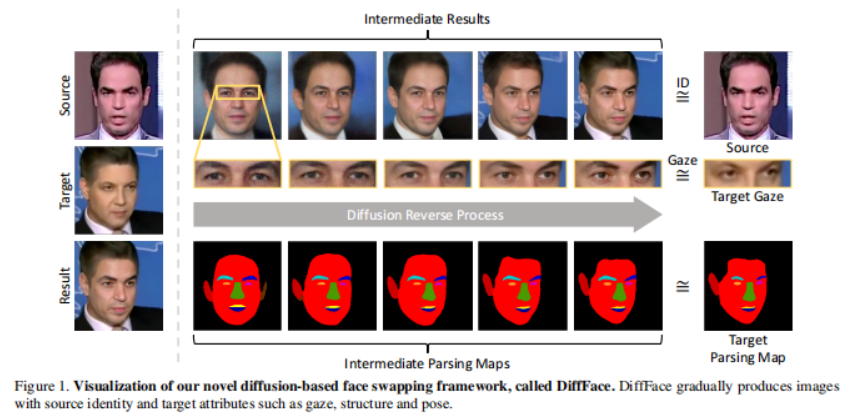
3、FlowFace: Semantic Flow-guided Shape-aware Face Swapping
这项工作提出一个用于形状感知人脸交换的语义流引导的两阶段框架,即 FlowFace。与以前的大多数专注于迁移源内部面部特征而忽略面部轮廓的方法不同,FlowFace 可以将它们都迁移到目标面部,达到更逼真的人脸交换效果。
具体来说,FlowFace 由面部重塑网络和面部交换网络组成。人脸重塑网络解决了源人脸和目标人脸之间的形状轮廓差异。它首先估计源和目标人脸之间的语义流(即面部形状差异),然后使用估计的语义流显式扭曲适应目标面部形状。重塑后,面部交换网络生成内部面部特征,展示源面部的身份。使用预训练的面部掩码自动编码器 (MAE) 从源面部和目标面部中提取面部特征。与之前使用身份嵌入来保存身份信息的方法相比,编码器提取的特征可以更好地捕获面部外观和身份信息。
还开发了一个交叉注意力融合模块,自适应地将源面部的内部面部特征与目标面部属性融合,从而更好地保持身份。大量定量和定性实验表明, FlowFace 优于最先进的技术。
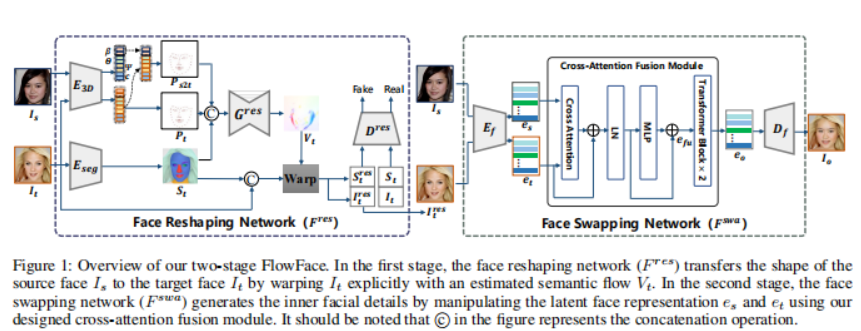
4、Landmark Enforcement and Style Manipulation for Generative Morphing
使用生成对抗网络 (GAN) 的变形生成(Morph generation)可产生不受基于关键点的方法造成的空间伪影影响的高质量变形,但使用常规的基于 GAN 的变形方法会明显丧失身份特征。
本文提出一种新的 StyleGAN 变形生成技术,通过引入关键点执行方法来解决这个问题。使用主成分分析 (PCA) 对模型的潜在空间进行探索,并通过潜在域平均解决身份丢失问题。此外,为了改善变形中的高频重建,研究了 StyleGAN2 模型的噪声输入的可训练性。

5、SimSwap: An Efficient Framework For High Fidelity Face Swapping
本文提出了一个高效的方法,称为SimSwap,旨在实现广义和高保真人脸交换。与之前的方法要么缺乏泛化到任意身份的能力,要么无法保留面部表情和注视方向等属性,本文方法能够将任意源人脸的身份转换为任意目标人脸,同时保留人脸的属性。
首先,提出了 ID 注入模块 (IIM),它在特征级别将源人脸的身份信息迁移到目标人脸。通过使用这个模块,将身份特定的人脸交换算法的架构扩展为任意人脸交换的框架。
其次,提出了弱特征匹配损失,它有效地帮助方法以隐式方式保留面部属性。实验表明, SimSwap 能够实现具有竞争力的身份性能,同时比以前的最先进方法更好地保留属性。
代码:https://github.com/neuralchen/SimSwap

6、FaceDancer: Pose- and Occlusion-Aware High Fidelity Face Swapping
这项工作提出了一种新的单阶段方法,用于与身份无关的换脸和身份变换,名为 FaceDancer。两个主要贡献:自适应特征融合注意(AFFA)和解释特征相似性正则化(IFSR)。
AFFA 模块嵌入在解码器中,并自适应地学习融合属性特征和以身份信息为条件的特征,而无需任何额外的面部分割过程。
IFSR 利用身份编码器中的中间特征来保留目标人脸中的重要属性,例如头部姿势、面部表情、光照和遮挡,同时仍然以高保真度传输源人脸的身份。
对各种数据集进行了广泛的定量和定性实验,并表明所提出的 FaceDancer 在身份变换方面优于其他最先进的网络,同时比以前的大多数方法具有更好的姿势保存。

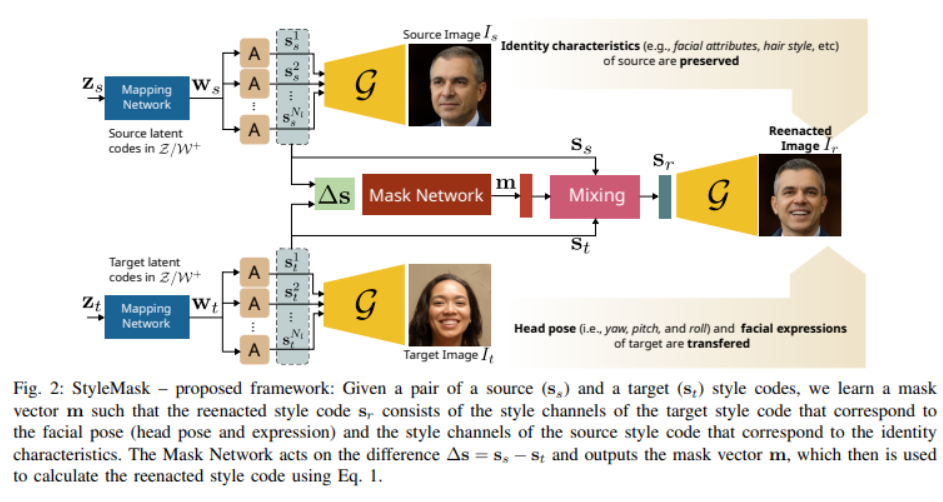
7、StyleMask: Disentangling the Style Space of StyleGAN2 for Neural
Face Reenactment
本文解决人脸再现/重演(face reenactment)问题,该任务里,给定一对源和目标面部图像,需要将目标的姿势(定义为头部姿势及其面部表情)转移到源图像,通过同时保留源的身份特征(例如,面部形状、发型等),即使在源脸和目标脸属于不同身份的具有挑战性的情况下也是如此。在这样做的过程中,本文解决了最先进方法的一些局限性,即,a)它们依赖于成对的训练数据(即源和目标人脸具有相同的身份),b)它们依赖在推理过程中标记数据上,以及 c)它们在头部姿势的大变化中不保留身份。
本文方法使用未配对的随机生成的面部图像,通过结合 StyleGAN2最近引入的风格空间 S 来学习将面部的身份特征与其姿势分开,这是一个潜在的表示空间,具有一定的解缠结特性。通过利用这一点,使用 3D 模型的监督成功地混合一对源风格码和目标风格码。生成的潜码随后用于重演,由仅与目标的面部姿势相对应的潜在单元和仅与源的身份相对应的单元组成,与最近的状态相比,重演性能明显提高。
定量和定性地表明,即使在极端姿势变化下,所提出的方法也能产生更高质量的结果。代码和预训练模型:https://github.com/StelaBou/StyleMask
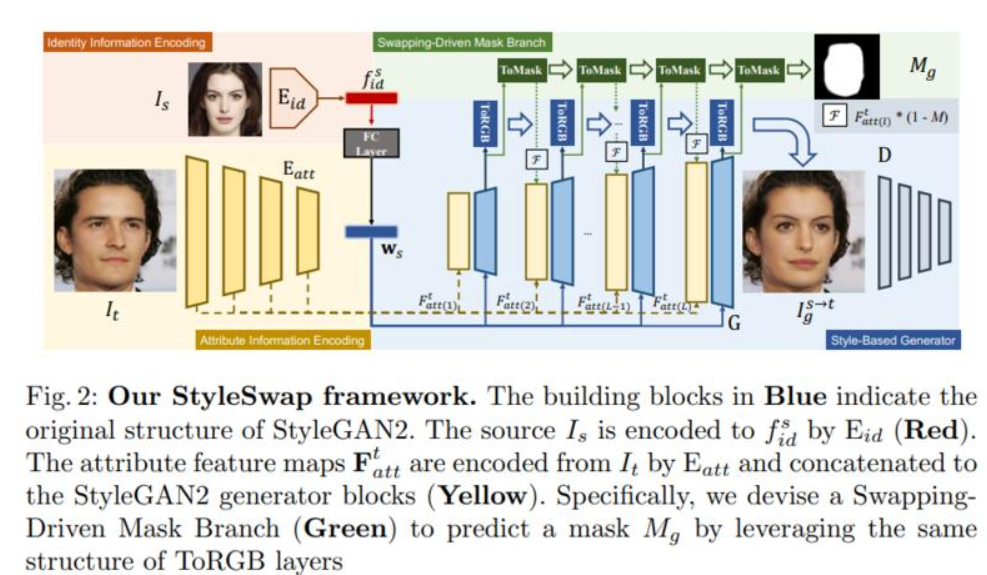
8、StyleSwap: Style-Based Generator Empowers Robust Face Swapping
鉴于其广泛的应用,已经对换脸任务进行了许多尝试工作。虽然现有的方法大多依赖于繁琐的网络模型和损失设计,但它们仍然在源和目标人脸之间的信息平衡方面存在困难,并且往往会产生可见的伪影。
这项工作介绍了一个简洁有效的框架 StyleSwap,核心思想是利用基于风格的生成器来实现高保真和鲁棒的人脸交换,从而可以利用生成器的优势来优化身份相似度。只需进行最少的修改,StyleGAN2 架构就可以成功处理来自源和目标的所需信息。此外,受 ToRGB 层的启发,进一步设计了交换驱动掩码分支以改进信息混合。此外,可以采用 StyleGAN 逆映射的优势。特别是,提出了一种交换引导的 ID 映射策略来优化身份相似性。
大量实验验证了方法产生了高质量的人脸交换结果,在质量和数量上都优于最先进的方法。视频、代码和模型在:https://hangz-nju-cuhk.github.io/projects/StyleSwap
9、Region-Aware Face Swapping
本文提出一种新的区域感知换脸 (Region-Aware Face Swapping,RAFSwap) 网络,以局部-全局方式实现身份一致的合理高分辨率人脸生成:1) 局部人脸区域感知 (FRA) 分支通过以下方式增强身份相关特征,引入 Transformer 来有效地模拟错位的跨尺度语义交互。2)全局源特征自适应(SFA)分支进一步补充了全局身份相关线索,用于生成身份一致的换脸效果。
此外,提出了一个与 StyleGAN2 结合的人脸mask掩膜预测器 (FMP) 模块,以无监督方式预测身份相关的软mask,这对于生成和谐的高分辨率人脸更实用。大量实验定性和定量地证明了方法在生成更多身份一致的高分辨率换脸方面优于 SOTA 方法。

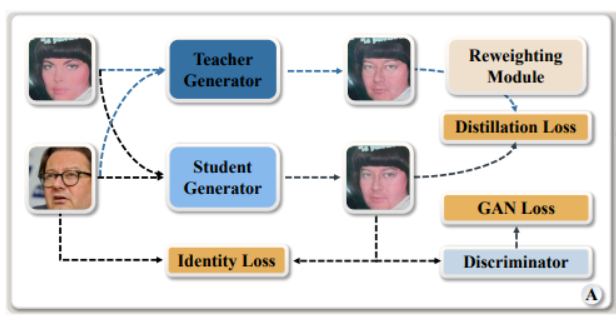
10、MobileFaceSwap: A Lightweight Framework for Video Face Swapping
先进的换脸技术取得了不错效果。但这些参数和计算量较大,将它们部署在手机等边缘设备上具有挑战性。这项工作提出一种轻量级的身份感知动态网络(IDN),根据身份信息动态调整模型参数来实现与个体无关的换脸效果。
特别是通过引入两种动态神经网络技术,包括权重预测和权重调制,设计一个高效的身份注入模块(IIM)。更新 IDN 后,可以将其应用于给定任何目标图像或视频的人脸交换。提出的 IDN 仅包含 0.50M 参数,每帧需要 0.33G FLOP,使其能够在手机上进行实时视频换脸。此外,引入一种基于知识蒸馏的稳定训练方法,并采用损失重加权模块来获得更好的综合结果。方法与教师模型和其他最先进的方法取得了可比较的结果。
猜您喜欢:
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻
欢迎加入 GAN/扩散模型 —交流微信群 !
扫描下面二维码,添加运营小妹好友,拉你进群。发送申请时,请备注,格式为:研究方向+地区+学校/公司+姓名。如 扩散模型+北京+北航+吴彦祖

请备注格式:研究方向+地区+学校/公司+姓名

点击 一顿午饭外卖,成为CV视觉的前沿弄潮儿!,领取优惠券,加入 AI生成创作与计算机视觉 知识星球!














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









