







【CVPR 2023的AIGC应用汇总(1)】图像转换/翻译,基于GAN生成对抗/diffusion扩散模型方法
【CVPR 2023的AIGC应用汇总(2)】可控文生图,基于diffusion扩散模型/GAN生成对抗方法
1、CoralStyleCLIP: Co-optimized Region and Layer Selection for Image Editing
高保真编辑(Edit fidelity)是开放可控生成图像编辑中的一个重要问题。最近,基于clip的方法通过在StyleGAN的一个精心挑选的层中引入空间注意力来进行优化改进。
本文提出CoralStyleCLIP,它在StyleGAN2的特征空间中融合了多层注意力引导的混合策略,以获得高保真的编辑。提出了多种形式的共同区域优化和层选择策略,以展示时间复杂性随不同架构复杂性的编辑质量的变化,同时保持简单性。
进行了广泛的实验分析,并将方法与最先进的基于clip的方法进行了比较。研究结果表明,在保持易用性的同时,CoralStyleCLIP可以产生高质量的编辑。

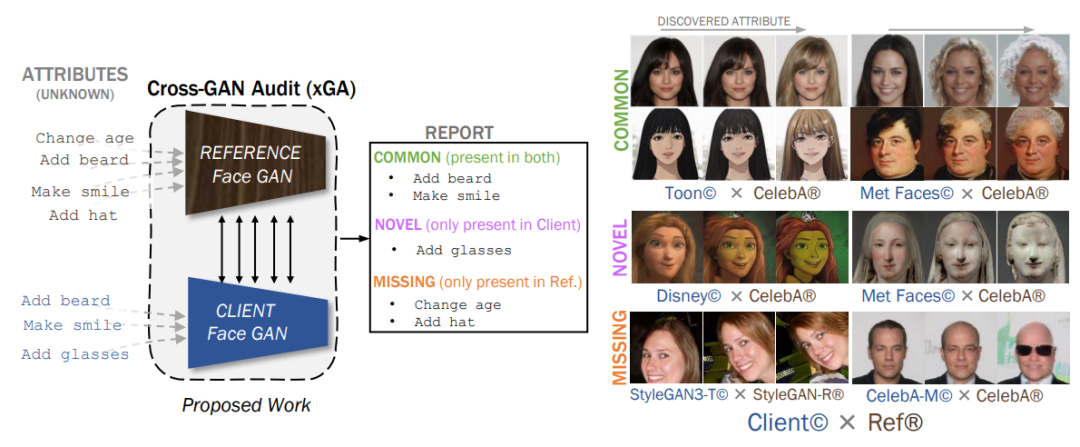
2、Cross-GAN Auditing: Unsupervised Identification of Attribute Level Similarities and Differences between Pretrained Generative Models
生成对抗网络(GAN)在训练复杂分布和数据量有限的情况下尤其难以训练。这促使需要一些工具以人类可读的格式审核已训练的网络,例如识别偏见或确保公平性。现有的GAN审核工具(GAN audit tools)仅限于基于总结统计量(如FID或召回率)的粗粒度模型数据比较。
本文提出了一种替代方法,即将新开发的GAN与之前的基线进行比较。为此,引入了跨GAN审核(Cross-GAN Auditing,xGA),给定一个已建立的“参考”GAN和一个新提出的“客户端”GAN,共同识别可理解的属性(intelligible attributes),这些属性在两个GAN中是相同的、客户端GAN中是新的、或缺少于客户端GAN中。
这为用户和模型开发人员提供了GAN之间相似性和差异的直观评估。引入新的指标来评估基于属性的GAN审核方法,并使用这些指标定量地证明xGA优于基线方法。还包括定性结果,展示了xGA从各种图像数据集上训练的GAN中识别出的常见、新颖和缺失属性。
3、Efficient Scale-Invariant Generator with Column-Row Entangled Pixel Synthesis
任意尺寸图像生成(Any-scale image synthesis)提供了一种高效和可扩展的解决方案,可以在任何比例下合成逼真的图像,甚至超过2K分辨率。然而,现有的基于GAN的解决方案过度依赖卷积和分层架构,在缩放输出分辨率时会导致不一致和“纹理粘合”问题。
从另一个角度来看,基于INR的生成器从设计上具有尺度等变性,但它们巨大的内存占用和慢速推断阻碍了这些网络在大规模或实时系统中的采用。这项工作提出了列行耦合的像素生成(Column-Row Entangled Pixel Synthesis,CREPS),一种既高效又具有尺度等变性的新型生成模型,而不使用任何空间卷积或粗到细的设计。为了节省内存占用并使系统可扩展,采用了一种新的双线表示方法(bi-line representation),将层内特征映射分解为单独的“厚”列和行编码。
在各种数据集上的实验,包括FFHQ、LSUNChurch、MetFaces和Flickr-Scenery,证实了CREPS具有在任意任意分辨率下合成尺度一致图像的能力。代码在https://github.com/VinAIResearch/CREPS

4、Fix the Noise: Disentangling Source Feature for Transfer Learning of StyleGAN
最近,StyleGAN的迁移学习已经展示出解决不同任务的潜力,特别是在领域转换方面。以前的方法在迁移学习过程中利用源模型通过权重交换或冻结来进行,然而它们在视觉质量和控制源特征方面存在局限性。换句话说,它们需要额外的模型,这些模型计算量巨大并且具有限制的控制步骤,这阻止了平滑的过渡。
本文提出了一种新的方法来克服这些限制。引入了一种简单的特征匹配损失来提高生成质量,而不是交换或冻结。此外,为了控制源特征的程度,使用所提出的策略“FixNoise”训练目标模型,仅在目标特征空间的一个分离子空间中保留源特征。由于这个分离特征空间,方法可以在一个单一模型中平滑地控制源特征的程度。广泛的实验表明,提出的方法可以比以前的方法生成更加一致和逼真的图像。

5、Improving GAN Training via Feature Space Shrinkage
由于出色的数据生成能力,生成对抗网络(GAN)在无监督学习中引起了相当大的关注。然而,训练 GAN 很困难,因为训练分布对于鉴别器是动态的,导致图像表示不稳定。
本文从一个新的角度解决训练 GAN 的问题,即稳健的图像分类。受鲁棒图像表示研究的启发,提出了一个简单而有效的模块,即 AdaptiveMix,用于 GAN,它缩小了鉴别器图像表示空间中训练数据的区域。考虑到直接绑定特征空间是棘手的,提出构造hard sample并缩小难样本和易样本之间的特征距离。hard sample是通过混合训练图像对来构建的。
使用广泛使用的最先进的 GAN 架构评估 AdaptiveMix 的有效性。评估结果表明,AdaptiveMix 可以促进 GAN 的训练,并有效提高生成样本的图像质量。还表明 AdaptiveMix 可以通过配备最先进的方法进一步应用于图像分类和分布外 (OOD) 检测任务。在七个公开可用的数据集上进行的大量实验表明,方法有效地提高了基线的性能。
代码 https://github.com/WentianZhangML/AdaptiveMix

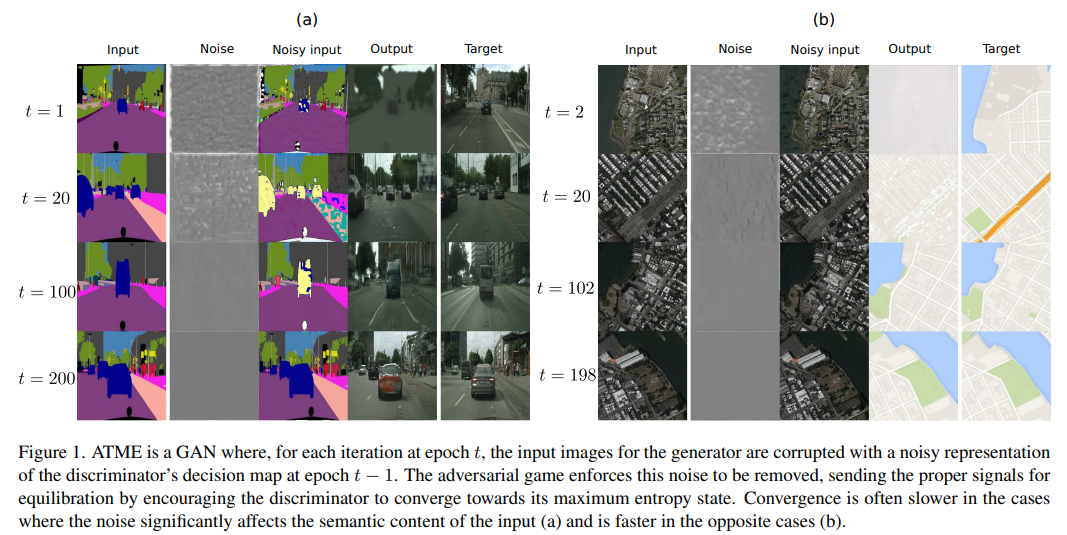
6、Look ATME: The Discriminator Mean Entropy Needs Attention
生成对抗网络(GANs)已经成功用于图像生成,但在训练过程中面临不稳定性的问题。概率扩散模型(DMs)稳定且生成高质量的图像,但采样过程代价昂贵。本文提出了一种简单的方法,将GANs与DMs的去噪机制结合起来,使GANs能够稳定地收敛到其理论最优解。这些模型被结合成一个更简单的模型(a simpler model,ATME),只需要前向传递即可进行预测。
ATME打破了大多数GAN模型存在的信息不对称,其中鉴别器具有生成器失败的空间知识。为了恢复信息对称性,生成器被赋予鉴别器的熵状态的知识,该知识被利用以使对抗游戏收敛于平衡。在几个图像到图像转换任务中展示了方法的优势,显示出比最先进的方法更好的性能,而成本更低。
代码https://github.com/DLR-MI/atme
7、NoisyTwins: Class-Consistent and Diverse Image Generation through StyleGANs
StyleGAN是可控图像生成的前沿技术,因为它生成了一个语义上解耦的潜在空间,适用于图像编辑和操作。然而,当通过对大规模长尾数据集进行类别条件训练时,StyleGAN的性能严重降低。导致性能下降的一个原因是W潜在空间中每个类别的潜变量崩溃。
本文提出NoisyTwins,首先引入了一种有效且廉价的类嵌入增强策略,然后基于W空间的自监督进行潜变量去相关。这种去相关缓解了崩溃,确保方法在图像生成中保持类内多样性和类一致性。
在ImageNet-LT和iNaturalist 2019这些大规模现实世界长尾数据集上展示了方法的有效性,其中在FID上比其他方法提高了约19%,创造了新的最优结果。

8、DeltaEdit: Exploring Text-free Training for Text-Driven Image Manipulation
文本驱动的图像编辑,在训练或推理灵活性方面仍然具有挑战性。条件生成模型在很大程度上依赖于昂贵的带标注训练数据。同时,利用预训练视觉语言模型的最新框架时,受到每个文本提示优化或推理时间超参数调整的限制。
这项工作提出DeltaEdit 来解决这些问题。关键思想是识别一个空间,即两图像的 CLIP 视觉特征差异、源文本和目标文本的 CLIP 文本嵌入差异,在它们之间具有良好对齐分布的 delta 图像和文本空间。基于 CLIP delta 空间,DeltaEdit 网络被设计为在训练阶段将 CLIP 视觉特征差异映射到 StyleGAN 的编辑方向。然后,在推理阶段,DeltaEdit 根据 CLIP 文本特征的差异预测 StyleGAN 的编辑方向。通过这种方式,DeltaEdit 以无文本的方式进行训练。经过训练后,它可以很好地泛化到各种文本提示,以进行零样本推理。
代码:https://github.com/Yueming6568/DeltaEdit

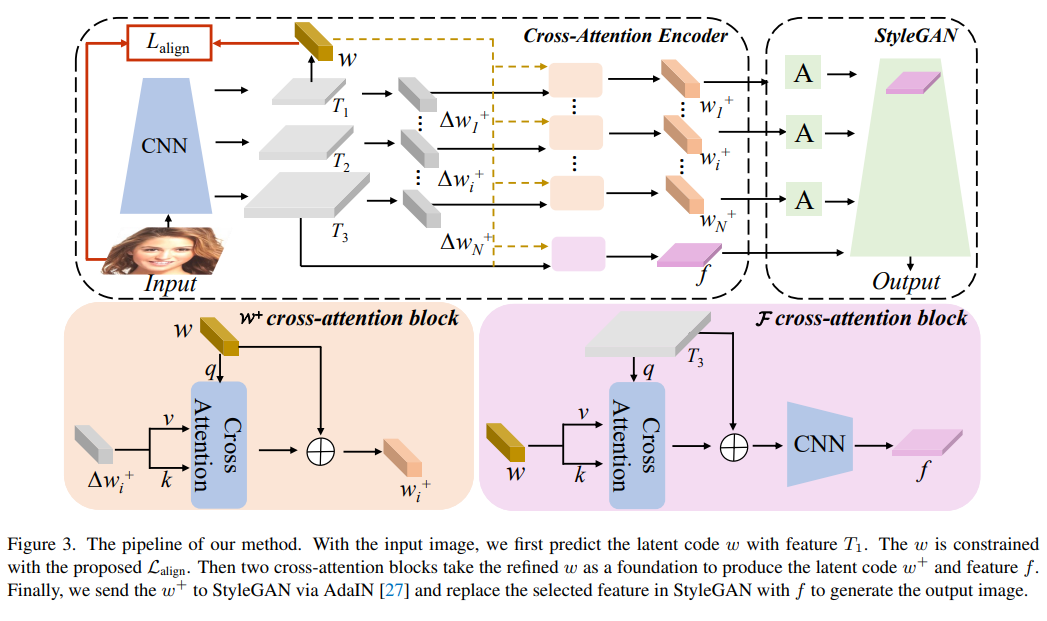
9、Delving StyleGAN Inversion for Image Editing: A Foundation Latent Space Viewpoint
通过StyleGAN的逆映射inversion和编辑,可以将输入图像映射到嵌入空间(W、W+和F),同时保持图像保真度和有意义的操作。从潜在空间W到扩展潜在空间W+再到特征空间F,GAN逆映射的可编辑性降低了,虽然重构质量可以提高。
最近的GAN逆映射方法通常探索W+和F而不是W。由于W+和F是从W中衍生出来的,而W实质上是StyleGAN的基础潜在空间,这些inversion方法集中于W+和F空间,可以通过回到W进行改进。这项工作首先在基础潜在空间W中获得适当的潜变量编码。引入对比学习来对齐W和图像空间,以便发现适当的潜变量编码。然后,利用交叉注意力编码器将在W中获得的潜变量编码相应地转换为W+和F。
实验表明,对基础潜在空间W的探索提高了W+中的潜变量编码和F中的特征的表示能力,从而在标准基准测试中产生了最先进的重构保真度和可编辑性结果。项目页面:https://kumapowerliu.github.io/CLCAE
10、SIEDOB: Semantic Image Editing by Disentangling Object and Background
语义图像编辑为用户提供了一种灵活的工具,可以通过相应的分割图指导修改给定图像。在这个任务中,前景对象和背景的特征非常不同。然而,所有之前的方法都使用单一模型处理背景和对象。因此,它们在处理内容丰富的图像时仍存在限制,并且容易生成不真实的对象和纹理不一致的背景。
为了解决这个问题,提出了一种新的范式,通过分解对象和背景进行语义图像编辑(SIEDOB),其核心思想是明确利用几个异构子网络来处理对象和背景。首先,SIEDOB将编辑输入分解成背景区域和实例级对象。然后,将它们送到专门的生成器中。最后,所有合成部分都嵌入到它们原始的位置,并利用融合网络获得协调的结果。此外,为了生成高质量的编辑图像,提出了一些创新设计,包括语义感知自传播模块、边界锚定局部块级别的鉴别器和样式多样性对象生成器,并将它们集成到SIEDOB中。
在Cityscapes和ADE20K-Room数据集上进行了大量实验,并展示了方法在合成真实和多样化的对象以及纹理一致的背景方面明显优于基线方法。
代码在 https://github.com/WuyangLuo/SIEDOB

猜您喜欢:
深入浅出stable diffusion:AI作画技术背后的潜在扩散模型论文解读
深入浅出ControlNet,一种可控生成的AIGC绘画生成算法!

最新最全100篇汇总!生成扩散模型Diffusion Models
附下载 |《TensorFlow 2.0 深度学习算法实战》
《礼记·学记》有云:独学而无友,则孤陋而寡闻

点击 一顿午饭外卖,成为CV视觉的前沿弄潮儿!,领取优惠券,加入 AI生成创作与计算机视觉 知识星球!

















 671
671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









