








论文进行详细阅读后,现在结合代码再次进行学习,加深对模型的理解,方便进一步的调试模型。
首先是模型的介绍
位置在
SparseDrive-main/projects/configs/sparsedrive_small_stage1.py
task_config = dict(
with_det=True, #检测任务
with_map=True, #地图任务
with_motion_plan=False, #运动规划任务
)
stage的任务类型,激活两个,代表stage1不尽兴motion plan的相关训练‘
基础设置
type="SparseDrive",
use_grid_mask=True,
use_deformable_func=use_deformable_func,
img_backbone=dict( #深度卷积神经网络 图像特征提取模块
type="ResNet", #网络模型为PyTorch的ResNet-50,代表深度是50层
depth=50,
num_stages=4, #代表ResNet包含四个阶段
frozen_stages=-1, #-1表示不冻结任何阶段,所有层都是可训练的。
norm_eval=False, #normalization_evaluate 评估时是否使用归一化参数
style="pytorch",
with_cp=True, #Checkpointing是一种优化技术,通过在计算图中插入检查点来减少显存使用。
out_indices=(0, 1, 2, 3),
norm_cfg=dict(type="BN", requires_grad=True), #norm_cfg归一化配置 Batch Normalization(BN)归一化,并且允许梯度更新
# pretrained="ckpt/resnet50-19c8e357.pth",
pretrained="/media/lxt/Netac/ssd/SparseDrive-main/ckpt/resnet50-19c8e357.pth", #预训练模型权重
),
img_neck=dict( #用于多尺度图像特征提取的模块
type="FPN", #特征金字塔网络FPN
num_outs=num_levels, #金字塔层数即输出特征图的个数
start_level=0,
out_channels=embed_dims, #输出特征图的通道数
add_extra_convs="on_output", #是否添加额外的卷积层
relu_before_extra_convs=True, #是否在额外的卷积层之前添加ReLU激活函数
in_channels=[256, 512, 1024, 2048], #输入特征图的通道数
),
depth_branch=dict( # for auxiliary supervision only辅助监督。深度分支通常用于生成深度图(depth map)或深度估计。
type="DenseDepthNet", #深度估计网络
embed_dims=embed_dims,
num_depth_layers=num_depth_layers,
loss_weight=0.2, #损失权重loss_weight 的值需要根据具体任务和数据集进行调整,以平衡深度分支和其他分支的损失贡献。
),
1、ResNet-50
深度残差网络RestNet(deep residual network)是一个经典的特征提取网络结构,ResNet主要解决深度卷积网络在深度加深时候的“退化”问题。整个模块除了正常的卷积层输出外,还有个分支把输入直接连到输出上,该分支输出和卷积的输出做算术相加得到最终的输出。
残差结构人为制造了恒等映射,就能让整个结构朝着恒等映射的方向去收敛,确保最终的错误率不会因为深度的变大而越来越差。
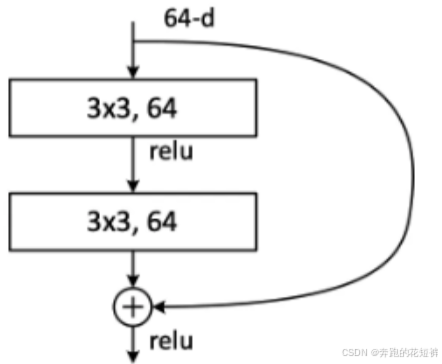
2、FPN
卷积网络中,随着网络深度的增加,特征图的尺寸越来越小,语义信息也越来越抽象。浅层特征图的语义信息较少,目标位置相对比较准确,深层特征图的语义信息比较丰富,目标位置则比较粗略,导致小物体容易检测不到。
FPN构建一个特征金字塔,功能可以说是融合了浅层到深层的特征图 ,从而充分利用各个层次的特征。
FPN学习
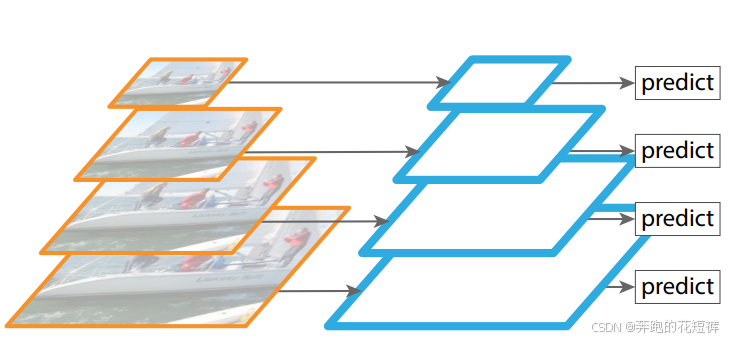
3、DenseDepth
DenseDepth 的核心是其创新的深度学习模型,它采用了两阶段的处理方式。
首先,利用一个轻量级的预训练网络进行粗略的深度估计,这一步骤快速而有效。
然后,通过一个更复杂的网络对这些初步的结果进行精细化处理,以获取更高分辨率和精度的深度图。
这一设计结合了速度与准确性,使得 DenseDepth 在实时性能和结果质量之间找到了很好的平衡。
该模型主要用于自动驾驶:深度信息对于感知周围环境至关重要,帮助车辆确定障碍物的距离并做出决策。
det_head=dict( #task 01 检测头部模块,处理数据集的检测任务
type="Sparse4DHead",
cls_threshold_to_reg=0.05, #分类阈值,论文中的T_threshold
decouple_attn=decouple_attn, #是否使用分离注意力机制True
instance_bank=dict( # 实例库配置
type="InstanceBank",
num_anchor=900,
embed_dims=embed_dims,
anchor="data/kmeans/kmeans_det_900.npy", #聚类中心,使用kmeans聚类得到
anchor_handler=dict(type="SparseBox3DKeyPointsGenerator"), #锚点生成器,用于生成锚点
num_temp_instances=600 if temporal else -1, # 时间序列实例数量,如果temporal为True,则使用600个时间序列实例,否则使用-1
confidence_decay=0.6, # 置信度衰减率,用于更新时间序列实例的置信度
feat_grad=False, # 是否使用特征梯度,用于更新时间序列实例的特征
),
anchor_encoder=dict( # 锚点编码器配置
type="SparseBox3DEncoder",
vel_dims=3, # 速度维度,用于编码速度信息
embed_dims=[128, 32, 32, 64] if decouple_attn else 256,
mode="cat" if decouple_attn else "add", # 编码模式,cat表示拼接,add表示相加
output_fc=not decouple_attn, # 是否输出全连接层,如果decouple_attn为False,则输出全连接层
in_loops=1, # 输入循环次数
out_loops=4 if decouple_attn else 2, # 输出循环次数
),
num_single_frame_decoder=num_single_frame_decoder, # 单帧解码器数量
operation_order=( #算子操作顺序
[
"gnn", # 图神经网络
"norm", # 归一化
"deformable", # 可变形注意力机制
"ffn", #前馈神经网络
"norm",
"refine", # 精修提炼
]
* num_single_frame_decoder
+ [
"temp_gnn", # 临时图神经网络
"gnn", # 图神经网络
"norm", # 归一化
"deformable", # 可变形
"ffn", # 前馈神经网络
"norm", # 归一化
"refine", # 优化
]
* (num_decoder - num_single_frame_decoder) #列表操作算子的重复次数
)[2:],
temp_graph_model=dict(
type="MultiheadFlashAttention",
embed_dims=embed_dims if not decouple_attn else embed_dims * 2, # 如果解耦,则embed_dims为256,否则为 512
num_heads=num_groups, #Multihead num
batch_first=True, #表示输入和输出的第一个维度是批次大小
dropout=drop_out, #防止过拟合
)
if temporal
else None,
graph_model=dict(
type="MultiheadFlashAttention",
embed_dims=embed_dims if not decouple_attn else embed_dims * 2, # 如果解耦,则embed_dims为256,否则为 512
num_heads=num_groups,
batch_first=True,
dropout=drop_out,
),
norm_layer=dict(type="LN", normalized_shape=embed_dims), # 定义norm_layer的参数,类型为LN,normalized_shape为embed_dims
ffn=dict(
type="AsymmetricFFN", # 类型为AsymmetricFFN
in_channels=embed_dims * 2, # 输入通道为512
pre_norm=dict(type="LN"), # pre_norm的类型为LN
embed_dims=embed_dims, # embed_dims为embed_dims
feedforward_channels=embed_dims * 4, #前馈网络通道中间层纬度为1024
num_fcs=2, # 层数为2
ffn_drop=drop_out, # 退火率
act_cfg=dict(type="ReLU", inplace=True), # 激活函数的类型为ReLU,inplace为True
),
deformable_model=dict(
type="DeformableFeatureAggregation", #DFA算子
embed_dims=embed_dims,
num_groups=num_groups,
num_levels=num_levels,
num_cams=6, # 6个相机
attn_drop=0.15, # 退火率
use_deformable_func=use_deformable_func,
use_camera_embed=True,
residual_mode="cat", # 残差连接模式为cat
kps_generator=dict(
type="SparseBox3DKeyPointsGenerator", # 生成关键点的类型为SparseBox3DKeyPointsGenerator
num_learnable_pts=6, # 可学习的点数为6
fix_scale=[ # 关键点固定尺度
[0, 0, 0],
[0.45, 0, 0],
[-0.45, 0, 0],
[0, 0.45, 0],
[0, -0.45, 0],
[0, 0, 0.45],
[0, 0, -0.45],
],
),
),
refine_layer=dict( # 精炼层 对稀疏的3D边界框进行精炼,比如调整位置、大小、方向等。
type="SparseBox3DRefinementModule",
embed_dims=embed_dims,
num_cls=num_classes,
refine_yaw=True, # 是否精炼yaw角
with_quality_estimation=with_quality_estimation, # 是否进行质量估计
),
sampler=dict(
type="SparseBox3DTarget", # 3D目标box采样器 用于障碍物检测和跟踪 类型为SparseBox3DTarget
num_dn_groups=0,
num_temp_dn_groups=0,
dn_noise_scale=[2.0] * 3 + [0.5] * 7, # 噪声尺度
max_dn_gt=32, # 最大动态噪声真值数
add_neg_dn=True,
cls_weight=2.0, # 类别损失函数权重
box_weight=0.25, # 边界框损失函数权重
reg_weights=[2.0] * 3 + [0.5] * 3 + [0.0] * 4, # 残差权重
cls_wise_reg_weights={ # 类别感知的残差权重 每个class对应一个weight
class_names.index("traffic_cone"): [
2.0,
2.0,
2.0,
1.0,
1.0,
1.0,
0.0,
0.0,
1.0,
1.0,
],
},
),
loss_cls=dict( #分类损失函数
type="FocalLoss",
use_sigmoid=True, # 是否使用sigmoid
gamma=2.0,
alpha=0.25, #损失函数权重参数
loss_weight=2.0,
),
loss_reg=dict( #回归损失函数
type="SparseBox3DLoss", #回归损失函数类型为SparseBox3DLoss
loss_box=dict(type="L1Loss", loss_weight=0.25), # 边界框损失函数类型为L1Loss
loss_centerness=dict(type="CrossEntropyLoss", use_sigmoid=True), # 中心损失函数类型为CrossEntropyLoss
loss_yawness=dict(type="GaussianFocalLoss"), # 方向损失函数类型为GaussianFocalLoss
cls_allow_reverse=[class_names.index("barrier")], # 允许反向的类别
),
decoder=dict(type="SparseBox3DDecoder"),
reg_weights=[2.0] * 3 + [1.0] * 7,
),
AsymmetricFFN
该模块提供了一种高效、可配置的方式将 FFN 融入更大的模型中,尤其适用于需要残差连接的结构。该模块支持灵活的激活函数、可选的丢弃层和自定义的维度,非常适合不同模型的需求。
Layer Normalization LN
的目标是在神经网络的每一层中,对该层所有神经元的激活值进行归一化。具体来说,LayerNorm 将每一层的激活值转换为均值为 0、标准差为 1 的分布,然后对结果进行缩放和偏移。
Dropout率
Dropout率和正规化的关系主要体现在对过拟合的预防和模型泛化能力的提升上。Dropout率越高,意味着更多神经元是激活的,正规化程度越低。这有助于减少过拟合现象,提高模型的泛化能力。12
DFA算子
DFA算子将原始的3D关键点:固定关键点和可学习关键点,与图像特征对齐,从而提取有效的图像特征
DFA算子实现流程:
第一步:首先,将900个query instance 的 13(6KFP+7KLP)个3D关键点全部投影current timestamp的FeatureMap上,接下来通过双线性插值方法在MultiView FeatureMap上进行特征采样;
第二步:紧接着,在MultiView的不同的MultiScale层(即不同分辨率的特征图层)上重复执行双线性插值操作,以捕获从粗粒度到细粒度的特征特区,这有助于模型在不同尺度上理解物体的结构和细节;
第三步:最后,网络会使用预测的权重(通过线性层计算得到)进行加权,完成特征的聚合。这确保算法具备了:根据检测任务的贡献大小,对不同视角和尺度的特征进行合适的特征融合;
P.S.其中KFP为固定关键点,KLP为可学习关键点,文中DeformableAttention Aggr,DeformableFeatureAggregation, DFA都指的同一个自定义算子
Focal loss
Focal loss的思路是通过在标准交叉熵损失的基础上新增一个系数因子,从而减弱对容易样本的学习和加强对困难样本的学习,提高模型的分类能力。
HungarianLinesAssigner
sampler=dict(
type="SparsePoint3DTarget",
assigner=dict(
type='HungarianLinesAssigner', #这是一个基于匈牙利算法的线分配器,用于将预测的线与真实线进行匹配。
cost=dict(
type='MapQueriesCost', # 这是一个用于计算线分配成本的函数,它考虑了线的类别和位置信息。
cls_cost=dict(type='FocalLossCost', weight=1.0), # 类别成本
reg_cost=dict(type='LinesL1Cost', weight=10.0, beta=0.01, permute=True), # 位置成本
),
),
num_cls=num_map_classes,
num_sample=num_sample,
roi_size=roi_size,
),
map_head大体和det相同,因此不再单独展示;
motion_plan_head=dict(
type='MotionPlanningHead',
fut_ts=fut_ts, # future time steps
fut_mode=fut_mode, # f未来模式 6
ego_fut_ts=ego_fut_ts,
ego_fut_mode=ego_fut_mode, #自车的未来模式 6
motion_anchor=f'data/kmeans/kmeans_motion_{fut_mode}.npy', # 运动的锚点
plan_anchor=f'data/kmeans/kmeans_plan_{ego_fut_mode}.npy', # 规划的锚点
embed_dims=embed_dims,
decouple_attn=decouple_attn_motion, # 解耦注意力机制
instance_queue=dict(
type="InstanceQueue",
embed_dims=embed_dims,
queue_length=queue_length, # 队列长度 4
tracking_threshold=0.2, # 跟踪阈值
feature_map_scale=(input_shape[1]/strides[-1], input_shape[0]/strides[-1]), # 特征图比例
),
operation_order=(
[
"temp_gnn",
"gnn",
"norm",
"cross_gnn",
"norm",
"ffn",
"norm",
] * 3 + # 3层 再加一层提炼
[
"refine",
]
),
temp_graph_model=dict(
type="MultiheadAttention",
embed_dims=embed_dims if not decouple_attn_motion else embed_dims * 2,
num_heads=num_groups, # 8
batch_first=True, # batch优先处理
dropout=drop_out,
),
graph_model=dict(
type="MultiheadFlashAttention", #MultiheadFlashAttention 使用多头快速注意力机制处理输入数据。
embed_dims=embed_dims if not decouple_attn_motion else embed_dims * 2,
num_heads=num_groups,
batch_first=True,
dropout=drop_out,
),
cross_graph_model=dict(
type="MultiheadFlashAttention", #MultiheadFlashAttention
embed_dims=embed_dims,
num_heads=num_groups,
batch_first=True,
dropout=drop_out,
),
norm_layer=dict(type="LN", normalized_shape=embed_dims), # 归一化层
ffn=dict(
type="AsymmetricFFN", # AsymmetricFFN使用不对称的前馈神经网络。
in_channels=embed_dims,
pre_norm=dict(type="LN"),
embed_dims=embed_dims,
feedforward_channels=embed_dims * 2, # 前馈通道
num_fcs=2, # 前馈神经网络的中间层维度 2层
ffn_drop=drop_out,
act_cfg=dict(type="ReLU", inplace=True), # 激活函数配置,使用ReLU激活函数。
),
refine_layer=dict(
type="MotionPlanningRefinementModule", # MotionPlanningRefinementModule使用运动规划细化模块。
embed_dims=embed_dims,
fut_ts=fut_ts,
fut_mode=fut_mode,
ego_fut_ts=ego_fut_ts,
ego_fut_mode=ego_fut_mode,
),
motion_sampler=dict(
type="MotionTarget", # MotionTarget运动目标采样器
),
motion_loss_cls=dict(
type='FocalLoss', # FocalLoss使用焦点损失函数。
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=0.2
),
motion_loss_reg=dict(type='L1Loss', loss_weight=0.2), # L1Loss使用L1损失函数。
planning_sampler=dict(
type="PlanningTarget", # PlanningTarget规划目标采样器
ego_fut_ts=ego_fut_ts,
ego_fut_mode=ego_fut_mode,
),
plan_loss_cls=dict(
type='FocalLoss',
use_sigmoid=True,
gamma=2.0,
alpha=0.25,
loss_weight=0.5,
),
plan_loss_reg=dict(type='L1Loss', loss_weight=1.0),
plan_loss_status=dict(type='L1Loss', loss_weight=1.0),
motion_decoder=dict(type="SparseBox3DMotionDecoder"), # SparseBox3DMotionDecoder使用稀疏的三维运动解码器。
planning_decoder=dict(
type="HierarchicalPlanningDecoder", # HierarchicalPlanningDecoder使用层次化的规划解码器。
ego_fut_ts=ego_fut_ts,
ego_fut_mode=ego_fut_mode,
use_rescore=True,
),
num_det=50, # 检测数量
num_map=10, # 地图数量
),
数据配置
数据集类型和位置。
一个图像归一化配置字典,用于在图像处理和计算机视觉任务中标准化图像数据。
img_norm_cfg = dict( # 图像归一化配置
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True #mean 是图像的均值 std 是图像的标准差 to_rgb=True 表示将图像从BGR转换为RGB
)
一个训练数据处理的pipeline,将原始数据转换为模型可以接受的格式。
train_pipeline = [ # 训练数据处理的流水线(pipeline)
# 用于处理多视图图像和点云数据,以供深度学习模型训练使用。流水线中的每个步骤都对应一个数据处理操作,这些操作共同作用,将原始数据转换为模型可以接受的格式
dict(type="LoadMultiViewImageFromFiles", to_float32=True), # 从文件中加载多视图图像 并将图像转换为浮点数类型
dict(
type="LoadPointsFromFile", #从文件中加载点云数据,指定坐标类型为LIDAR,加载维度为5,使用维度为5,并使用指定的文件客户端参数
coord_type="LIDAR",
load_dim=5,
use_dim=5,
file_client_args=file_client_args,
),
dict(type="ResizeCropFlipImage"), # 调整图像大小,裁剪图像,并随机翻转图像
dict(
type="MultiScaleDepthMapGenerator", # 多尺度深度图生成器,用于生成不同尺度下的深度图 用于深度学习模型处理
downsample=strides[:num_depth_layers],
),
dict(type="BBoxRotation"), # 旋转边界框,以适应不同角度的数据。用于深度学习模型处理
dict(type="PhotoMetricDistortionMultiViewImage"), # 对多视图图像进行光度失真,以增加数据多样性。以模拟真实世界的图像变化。
dict(type="NormalizeMultiviewImage", **img_norm_cfg), # 对多视图图像进行归一化处理,以适应深度学习模型的输入要求。归一化处理将图像的像素值缩放到一个较小的范围内,以便模型可以更好地学习特征。
dict(
type="CircleObjectRangeFilter", # 圆形对象范围过滤器,用于过滤掉超出指定范围的点云数据。根据对象的分布阈值过滤掉超出范围的物体,这里使用55作为阈值
class_dist_thred=[55] * len(class_names),
),
dict(type="InstanceNameFilter", classes=class_names), # 实例名称过滤器,用于过滤掉不属于指定类别的点云数据。根据指定的类别名称过滤掉不属于指定类别的物体
dict(
type='VectorizeMap', # 将地图数据矢量化,指定ROI大小、是否简化、是否归一化、采样数量和是否置换。
roi_size=roi_size,
simplify=False,
normalize=False,
sample_num=num_sample,
permute=True,
),
dict(type="NuScenesSparse4DAdaptor"), # NuScenesSparse4DAdaptor,用于将数据适配为NuScenes数据集的格式。将数据适配为NuScenes数据集的格式,包括图像、点云、地图、边界框、标签等。
dict(
type="Collect", # 收集器,用于收集指定的数据字段。将指定的数据字段收集起来,以便后续的模型训练和评估使用。
keys=[
"img",
"timestamp",
"projection_mat", # 图像投影矩阵,用于将点云数据投影到图像平面上
"image_wh",
"gt_depth",
"focal",
"gt_bboxes_3d",
"gt_labels_3d",
'gt_map_labels',
'gt_map_pts',
'gt_agent_fut_trajs',
'gt_agent_fut_masks',
'gt_ego_fut_trajs',
'gt_ego_fut_masks',
'gt_ego_fut_cmd',
'ego_status',
],
meta_keys=["T_global", "T_global_inv", "timestamp", "instance_id"], # meta_keys指定了需要收集的元数据字段,包括全局变换矩阵、全局变换矩阵的逆矩阵、时间戳和实例ID。
),
]
test_pipeline = [
dict(type="LoadMultiViewImageFromFiles", to_float32=True), # 加载多视图图像,将图像转换为浮点数
dict(type="ResizeCropFlipImage"), # 调整图像大小、裁剪图像、翻转图像 标准化图像尺寸,以便后续的图像处理步骤能够接受相同尺寸的输入
dict(type="NormalizeMultiviewImage", **img_norm_cfg), # 对多视图图像进行归一化处理,以适应深度学习模型的输入要求。归一化处理将图像的像素值缩放到一个较小的范围内,以便模型可以更好地学习特征。
dict(type="NuScenesSparse4DAdaptor"), # NuScenesSparse4DAdaptor,用于将数据适配为NuScenes数据集的格式。将数据适配为NuScenes数据集的格式,包括图像、点云、地图、边界框、标签等。
dict(
type="Collect",
keys=[
"img",
"timestamp",
"projection_mat", # 图像投影矩阵,用于将点云数据投影到图像平面上
"image_wh",
'ego_status',
'gt_ego_fut_cmd',
],
meta_keys=["T_global", "T_global_inv", "timestamp"], # meta_keys指定了需要收集的元数据字段,包括全局变换矩阵、全局变换矩阵的逆矩阵、时间戳和实例ID。
),
]
定义了一个评估pipeline(eval_pipeline),它是一个包含多个步骤的列表,每个步骤都是一个字典,定义了不同的数据处理和过滤操作。这些步骤用于处理和过滤点云数据,以便进行后续的模型训练和评估。
eval_pipeline = [
dict(
type="CircleObjectRangeFilter", # 圆形对象范围过滤器,用于过滤掉超出指定范围的点云数据。将点云数据过滤掉,只保留在指定范围内的点云数据。
class_dist_thred=[55] * len(class_names), #列表长度等于 class_names 的长度,每个元素都是 55。这个参数用于过滤掉距离太远的对象。
),
dict(type="InstanceNameFilter", classes=class_names), # 实例名称过滤器,用于过滤掉指定类别的点云数据。将点云数据过滤掉,只保留指定类别的点云数据。
dict(
type='VectorizeMap', # 将地图数据转换为向量表示。将地图数据转换为向量表示,以便后续的模型训练和评估使用。
roi_size=roi_size,
simplify=True, # simplify 参数用于控制是否对地图数据进行简化处理。如果 simplify 为 True,则对地图数据进行简化处理,否则不进行简化处理。
normalize=False, # normalize 参数用于控制是否对地图数据进行归一化处理。如果 normalize 为 True,则对地图数据进行归一化处理,否则不进行归一化处理。
),
dict(
type='Collect',
keys=[
'vectors',
"gt_bboxes_3d",
"gt_labels_3d",
'gt_agent_fut_trajs',
'gt_agent_fut_masks',
'gt_ego_fut_trajs',
'gt_ego_fut_masks',
'gt_ego_fut_cmd',
'fut_boxes'
],
meta_keys=['token', 'timestamp'] # meta_keys指定了需要收集的元数据字段,包括 token 和时间戳。
),
]
为输入模态、数据集、评估模块的配置;
input_modality = dict( # 输入模态配置,指定了数据集中包含的模态类型,包括图像、雷达、地图和外部数据。
use_lidar=False,
use_camera=True, # use_camera 参数用于控制是否使用相机数据。
use_radar=False,
use_map=False,
use_external=False,
)
data_basic_config = dict( # 数据集的基本配置,包括数据集类型、数据集根目录、类别名称、模态类型、版本号等。
type=dataset_type,
data_root=data_root,
classes=class_names,
map_classes=map_class_names,
modality=input_modality,
version="v1.0-trainval",
)
eval_config = dict( # 评估配置,指定了评估指标和评估方式。
**data_basic_config, # 使用 data_basic_config 中的配置
ann_file=anno_root + 'nuscenes_infos_val.pkl', # 指定评估数据集的标注文件
pipeline=eval_pipeline, # 指定评估时的数据预处理流程
test_mode=True,
)
数据增强过程 以便在训练深度学习模型时使用。通过调整这些参数,可以生成更多的训练样本,从而提高模型的泛化能力和鲁棒性。
data_aug_conf = { # 数据增强配置,指定了数据增强的方式和参数。
"resize_lim": (0.40, 0.47), # resize_lim 参数用于控制图像的缩放范围。这里设置为 (0.40, 0.47),表示图像的缩放范围在 40% 到 47% 之间。
"final_dim": input_shape[::-1], # final_dim 参数用于控制图像的最终尺寸。这里设置为 input_shape[::-1],表示图像的最终尺寸为 input_shape 的逆序。
"bot_pct_lim": (0.0, 0.0), # bot_pct_lim 参数用于控制图像底部裁剪的比例范围。这里设置为 (0.0, 0.0),表示不进行底部裁剪。
"rot_lim": (-5.4, 5.4), # rot_lim 参数用于控制图像的旋转角度范围。这里设置为 (-5.4, 5.4),表示图像的旋转角度范围在 -5.4 度到 5.4 度之间。
"H": 900,
"W": 1600,
"rand_flip": True, # rand_flip 参数用于控制是否随机翻转图像。这里设置为 True,表示随机翻转图像。
"rot3d_range": [0, 0], # rot3d_range 参数用于控制 3D 旋转的角度范围。这里设置为 [0, 0],表示不进行 3D 旋转。
}
用于配置深度学习模型的数据加载和训练参数。具体来说,这段代码配置了训练、验证和测试数据集的参数,包括每个 GPU 的样本数量、数据加载线程数量、标注文件路径、数据预处理流水线、数据增强配置、是否使用序列标志、序列分割数量、是否保持一致的序列增强以及评估配置等。这些参数对于深度学习模型的训练和评估至关重要,它们决定了数据如何被加载、预处理和增强,以及模型如何被评估。
data = dict(
samples_per_gpu=batch_size, # samples_per_gpu 参数用于控制每个 GPU 的样本数量。这里设置为 batch_size,表示每个 GPU 的样本数量为 batch_size。
workers_per_gpu=batch_size, # workers_per_gpu 参数用于控制每个 GPU 的数据加载线程数量。这里设置为 batch_size,表示每个 GPU 的数据加载线程数量为 batch_size。
train=dict( # train 参数用于配置训练数据集的配置。
**data_basic_config,
ann_file=anno_root + "nuscenes_infos_train.pkl", # ann_file 参数用于指定训练数据集的标注文件。这里设置为 anno_root + "nuscenes_infos_train.pkl",表示训练数据集的标注文件为 anno_root 目录下的 nuscenes_infos_train.pkl 文件。
pipeline=train_pipeline,
test_mode=False,
data_aug_conf=data_aug_conf,
with_seq_flag=True, #表示使用序列标志,可能用于处理时间序列数据。
sequences_split_num=2,
keep_consistent_seq_aug=True, #表示保持一致的序列增强,可能用于处理时间序列数据。
),
val=dict( # val 参数用于配置验证数据集的配置。
**data_basic_config,
ann_file=anno_root + "nuscenes_infos_val.pkl",
pipeline=test_pipeline,
data_aug_conf=data_aug_conf,
test_mode=True,
eval_config=eval_config, # eval_config 参数用于配置评估配置,可能用于指定评估的方式和参数。
),
test=dict( # test 参数用于配置测试数据集的配置。
**data_basic_config,
ann_file=anno_root + "nuscenes_infos_val.pkl",
pipeline=test_pipeline,
data_aug_conf=data_aug_conf,
test_mode=True,
eval_config=eval_config,
),
)
训练
optimizer = dict(
type="AdamW", # type 参数用于指定优化器的类型。这里设置为 AdamW,表示使用 AdamW 优化器。
lr=4e-4, # lr 参数用于指定学习率。这里设置为 4e-4。
weight_decay=0.001, # weight_decay 参数用于指定权重衰减。这里设置为 0.001。
paramwise_cfg=dict( # paramwise_cfg 参数用于配置参数的权重衰减。这里设置了 img_backbone 的 lr_mult 为 0.5,表示 img_backbone 的学习率为 lr 的 0.5 倍。
custom_keys={
"img_backbone": dict(lr_mult=0.5), # lr_mult 参数用于指定学习率的倍数。这里设置为 0.5,表示 img_backbone 的学习率为 lr 的 0.5 倍。
}
),
)
optimizer_config = dict(grad_clip=dict(max_norm=25, norm_type=2)) # optimizer_config 参数用于配置优化器的配置。这里设置了 grad_clip,表示梯度裁剪,max_norm 为 25,norm_type 为 2。
lr_config = dict( # lr_config 参数用于配置学习率的配置。这里设置了 CosineAnnealing 学习率调度器,warmup_iters 为 500,warmup_ratio 为 1.0 / 3,min_lr_ratio 为 1e-3。
policy="CosineAnnealing", # policy 参数用于指定学习率调度器的类型。这里设置为 CosineAnnealing,表示使用余弦退火学习率调度器。
warmup="linear", # warmup 参数用于指定学习率预热的方式。这里设置为 linear,表示使用线性预热。
warmup_iters=500, # warmup_iters 参数用于指定学习率预热的迭代次数。这里设置为 500。
warmup_ratio=1.0 / 3, # warmup_ratio 参数用于指定学习率预热的初始学习率比例。这里设置为 1.0 / 3,表示初始学习率为 lr 的 1/3。
min_lr_ratio=1e-3, # min_lr_ratio 参数用于指定学习率的最小比例。这里设置为 1e-3,表示学习率的最小值为 lr 的 1e-3 倍。
)
runner = dict(
type="IterBasedRunner", # type 参数用于指定运行器的类型。这里设置为 IterBasedRunner,表示使用基于迭代次数的运行器。
max_iters=num_iters_per_epoch * num_epochs, # max_iters 参数用于指定最大迭代次数。这里设置为 num_iters_per_epoch * num_epochs,表示最大迭代次数为每个 epoch 的迭代次数乘以 epoch 数。
)
Adamw优化器
Adam 优化器结合了 RMSprop 和 Momentum 两种优化算法的优点,通过计算梯度的一阶矩(均值)和二阶矩(未中心化的方差)来调整每个参数的学习率。这种方法使得它特别适用于处理非稳定目标函数和非常大的数据集或参数数量。
AdamW 是一种改进的 Adam 优化算法,它对 Adam 的权重衰减组件进行了修改,使得权重衰减不再是添加到梯度上而是直接对参数进行更新。这种方法与 L2 正则化的原理更为接近,通常可以带来更好的训练稳定性和泛化性能。
使用 AdamW 优化器的训练过程与其他优化器类似,但由于其处理权重衰减的方式,它可能在需要正则化以提高模型泛化能力的任务中表现得更好。
AdamW 优化器的优点
更有效的正则化:由于其更新权重衰减的方式,AdamW 可以更有效地进行正则化,避免深度学习模型中常见的过拟合问题。
改善泛化:与传统的 Adam 相比,AdamW 在多个基准测试中显示出更好的泛化能力。
易于集成:AdamW 可以轻松替换 Adam 优化器,无需改动其他代码,提供了一种简单的提升模型性能的方式。
AdamW 适用于几乎所有使用 Adam 的场景,特别推荐在易于过拟合的大模型和复杂任务中使用。由于其改进的权重衰减机制,它特别适合需要正则化的应用,如在小数据集上训练的深度网络。在选择优化器时,如果你已经计划使用 Adam 并关注模型的泛化,不妨试试 AdamW。
CosineAnnealing
当使用梯度下降算法来优化目标函数的时候,当越来越接近Loss值的全局最小值时,学习率应该变得更小来使得模型尽可能接近这一点,而余弦退火(Cosine annealing)可以通过余弦函数来降低学习率。余弦函数中随着x的增加余弦值首先缓慢下降,然后加速下降,再次缓慢下降。这种下降模式能和学习率配合,以一种十分有效的计算方式来产生很好的效果。
带重启的随机梯度下降算法(SGDR),其中就引入了余弦退火的学习率下降方式。因为我们的目标优化函数可能是多峰的,除了全局最优解之外还有多个局部最优解,在训练时梯度下降算法可能陷入局部最小值,此时可以通过突然提高学习率,来“跳出”局部最小值并找到通向全局最小值的路径。这种方式称为带重启的随机梯度下降方法。
IterBasedRunner
Runner类是MMCV的一个核心组件,它是一个用来管理训练流程的引擎,并且支持用户用少量代码按照它提供的接口定制化修改训练流程。Runner的目的就是给用户提供统一的训练流程管理,并支持弹性、可配置的定制化修改(通过Hook实现),默认支持Epoch和Iter为基础迭代训练的EpochBasedRunner和IterBasedRunnner。
评估
stage1 不进行planning相关的操作,仅有det、tracking、map三个部分
配置eval的内容,迭代次数为总的次数
eval_mode = dict(
with_det=True, # with_det 参数用于指定是否进行目标检测评估。这里设置为 True,表示进行目标检测评估。
with_tracking=True, # with_tracking 参数用于指定是否进行跟踪评估。这里设置为 True,表示进行跟踪评估。
with_map=True, # with_map 参数用于指定是否进行地图评估。这里设置为 True,表示进行地图评估。
with_motion=False, # with_motion 参数用于指定是否进行运动评估。这里设置为 False,表示不进行运动评估。
with_planning=False, # with_planning 参数用于指定是否进行规划评估。这里设置为 False,表示不进行规划评估。
tracking_threshold=0.2,
motion_threshhold=0.2,
)
evaluation = dict( # evaluation 参数用于配置评估的配置。这里设置了 interval 为 num_iters_per_epoch * checkpoint_epoch_interval,eval_mode 为 eval_mode。
interval=num_iters_per_epoch*checkpoint_epoch_interval, # interval 参数用于指定评估的间隔。这里设置为 num_iters_per_epoch * checkpoint_epoch_interval,表示每个 checkpoint_epoch_interval 个 epoch 进行一次评估。
eval_mode=eval_mode, # eval_mode 参数用于指定评估的模式。这里设置为 eval_mode,表示使用 eval_mode 中定义的评估模式。
)
stage2
stage2与stage1大致相同
在优化的学习率和、评估的模式方面存在区别;



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









