






 本文介绍了一种新型的文本检测工具Fast-DetectGPT,它利用条件概率曲率实现无监督的高精度检测,速度提升340倍,准确率超越GPTZero,适用于检测不同模型生成的文本。
本文介绍了一种新型的文本检测工具Fast-DetectGPT,它利用条件概率曲率实现无监督的高精度检测,速度提升340倍,准确率超越GPTZero,适用于检测不同模型生成的文本。
本文提出了一种新的文本检测方法 ——Fast-DetectGPT,无需训练,直接使用开源小语言模型检测各种大语言模型,如GPT等生成的文本内容。
Fast-DetectGPT 将检测速度提高了 340 倍,将检测准确率相对提升了 75%,超过商用系统 GPTZero 的准确率,成为新的 SOTA。
论文题目:
Fast-DetectGPT: Efficient Zero-Shot Detection of Machine-Generated Text via Conditional Probability Curvature
论文链接:
https://openreview.net/forum?id=Bpcgcr8E8Z
代码链接:
https://github.com/baoguangsheng/fast-detect-gpt
现有的检测器主要分为两类:有监督分类器和零样本分类器。虽然有监督分类器在其特定训练领域表现出色,但在面对来自不同领域或不熟悉模型生成的文本时,其表现会变差。
零样本分类器则能够免疫领域特定的退化,并且在检测精度上可以与有监督分类器相媲美。
然而,典型的零样本分类器,如 DetectGPT,需要执行大约一百次模型调用或与 OpenAI API 等服务交互来创建扰动文本,这导致了过高的计算成本和较长的计算时间。同时它需要用生成文本的源语言模型来进行检测的计算,使得该方法不能用于检测由未知模型生成的文本。
作者认为,人类和机器在给定上下文的情况下选择词汇存在明显的差异,而机器和机器之间的差异不明显。利用这种差异,可用一套模型和方法检测不同模型生成的文本内容。即在大规模语料库上预训练的 LLM 反映的是人类的集体写作行为,而非个体的写作行为,这导致它们在给定上下文时的词汇选择存在差异。
这些观察结果表明,机器生成的文本通常具有比人类写作的文本有更高的统计概率(或更低的困惑度)。
进一步假设,在条件概率函数中,机器生成的文本周围的局部空间存在一个正曲率。作者提出条件概率曲率指标,用以区分机器生成文本和人类撰写文本。
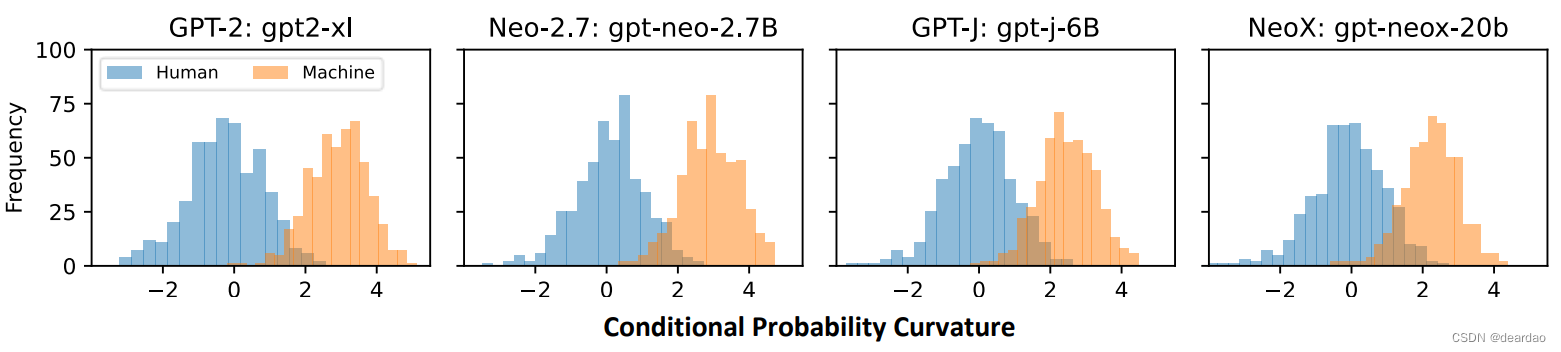
在四个不同开源模型上,人类撰写文本的条件概率曲率近似一个均值为 0 的正态分布,而机器生成文本的条件概率曲率近似一个均值为 3 的正态分布,这两个分布只有少量的重叠。
根据这种分布上的特点,可以选择一个阈值,大于这个阈值判断为机器生成文本,小于则为人类撰写,从而获得一个检测器。















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









