







开场
最近chatgpt已经火爆了,几乎是家喻户晓老少皆知啊,公测推出60天后就已经是UV人数过亿,日访问量号称也是过亿。投资chatgpt研发团队的微软也是2个月内迅速推出自己的chatgpt的bing搜索,股票下载量都是暴增啊。前面文章已经介绍过chatgpt技术可能会对整个人类组织分工带来的影响以及原因,这里就不在继续歪歪了。
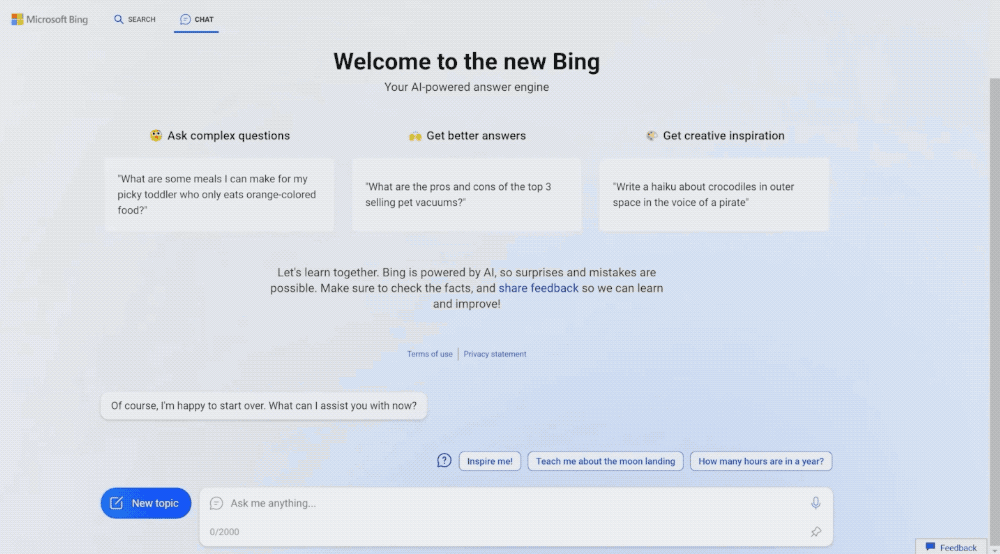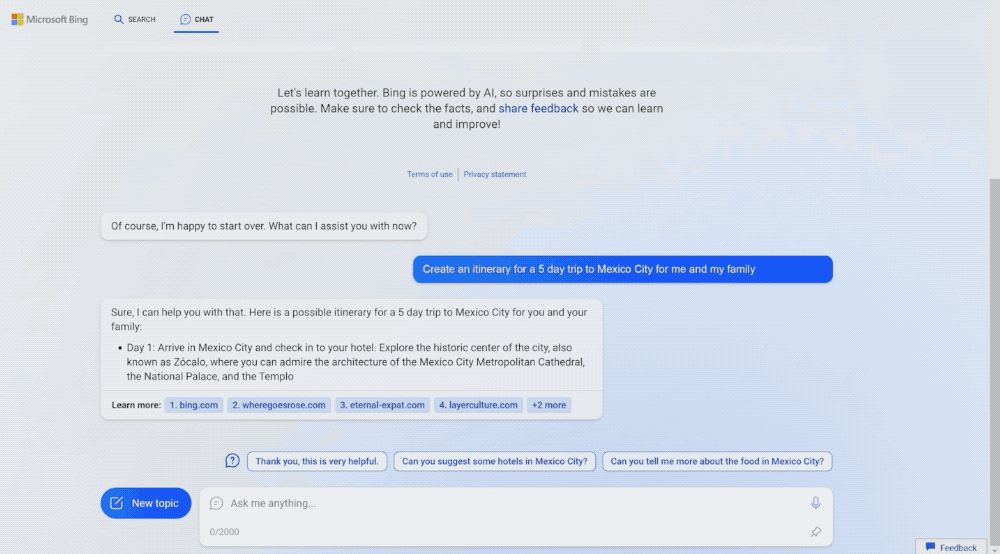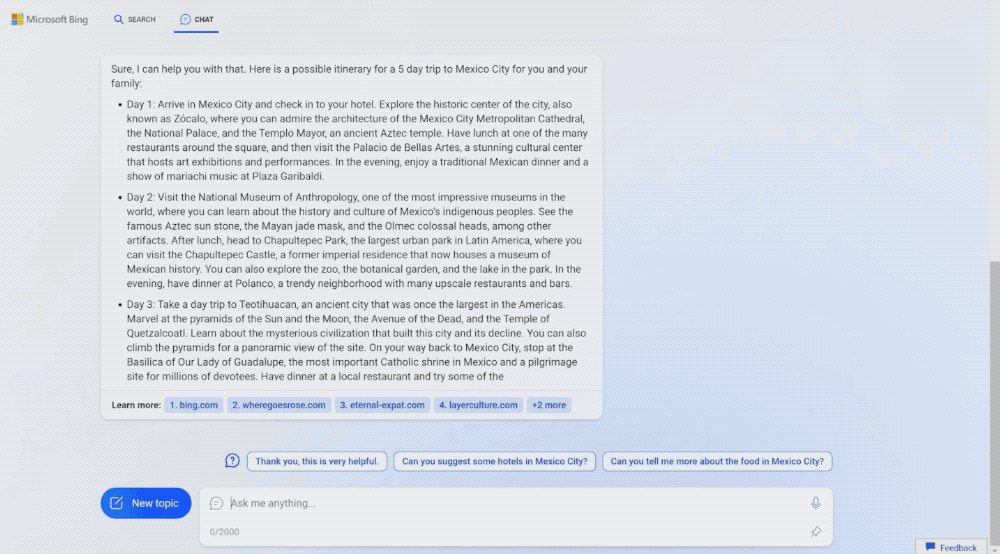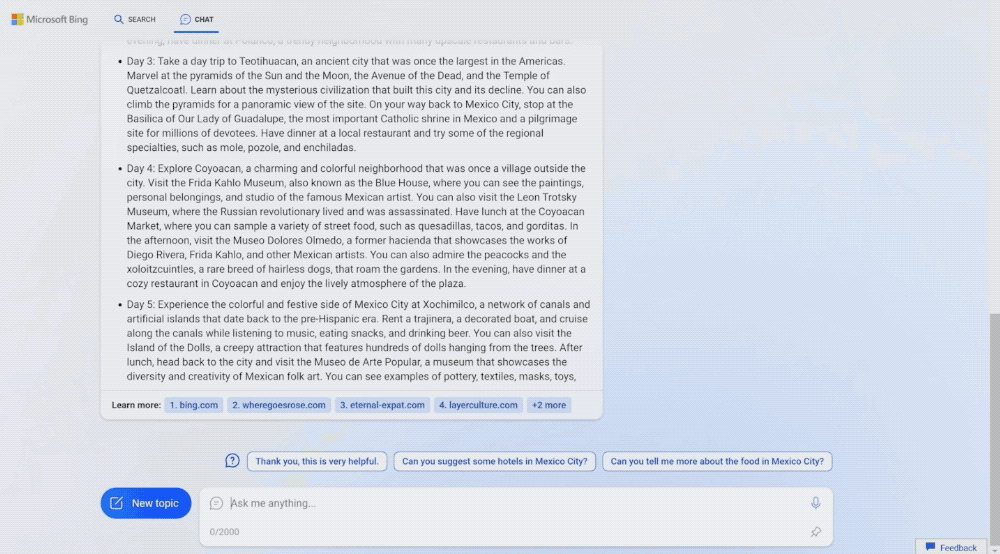
从这篇文章开始,我打算实现一个mini版本的chatgpt,把背后的原理算法、数据准备工作都会介绍到。这系列文章预计会有7-8篇,主要是讲实现,不会介绍transformer模型技术细节、ppo数学推理。
到最后大家可以收获一个问答式的文本生成工具,大家也可以根据自己需要定制训练自己的模型做自己想要做的事,比如一个跟懂自己智能助理、解读论文的神器、可以通过语音方式理解需求帮你控制智能家居、通过语音帮你画一幅你想要的画...
第一篇先介绍整个RLHF大训练框架,介绍SFT模型训练:数据、基本模型。先介绍单个模型大家先熟悉代码在自己机器上试跑训练下数据。
第二部分会对模型改造、代码封装,让代码能够在多卡多机上训练;更工业风。
第三部分把流程封装,三部分的代码做一个整合,到这边你就可以得到一个真正能够训练中文语料的链路框架,并且可以自己准备训练标注语料。
第四部分会给大家介绍基于这个小的chatgpt引擎做的各种应用探索。
宏观介绍

整个链路包括三块:
文本生成AGGENT,为了得到一个不错Agent我们需要用‘输入-输出’语料对训练一个不错基准模型,把这个过程叫做sft
评判文本生成好坏的Reward,为了得到Reward模型我们需要用‘输入-输出list’语料做一个排序打分模型,把这个过程叫做Reward
利用Reward反馈调试Agent模型PPO调控器

fig1.sft训练过程
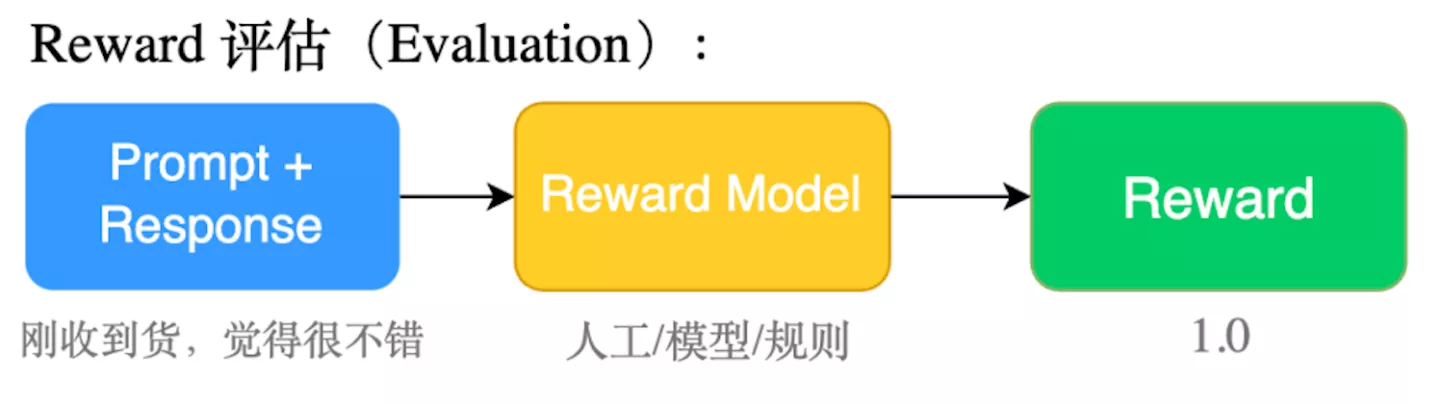
fig2.reward训练过程
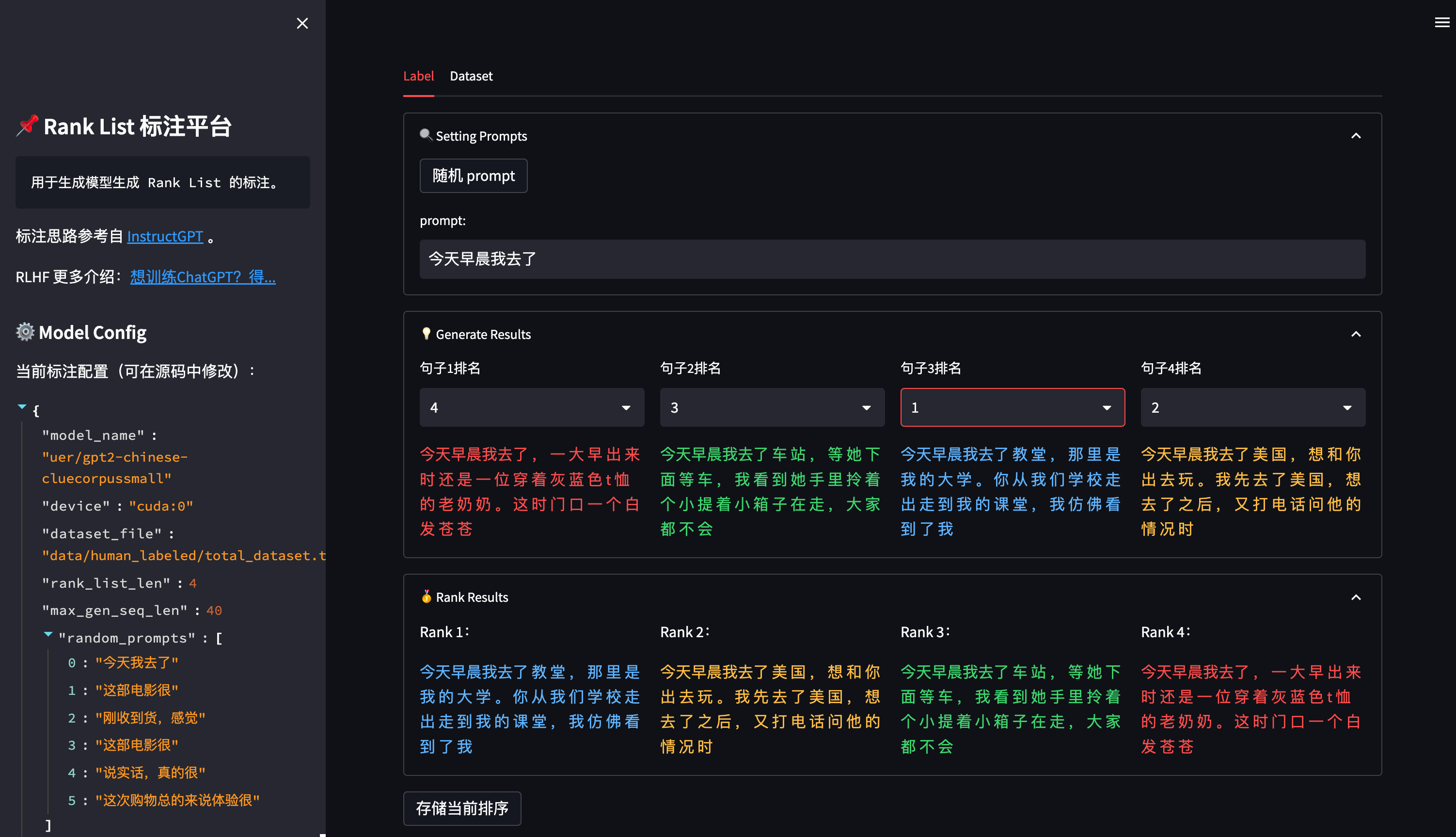
Rank数据打标
SFT实现
先训练一个基本的有文本生成能力的模型,可以选用GPT或者T5框架模型来做训练。
from transformers import BertTokenizer, GPT2LMHeadModel, TextGenerationPipeline
tokenizer = BertTokenizer.from_pretrained("uer/gpt2-chinese-lyric")
model = GPT2LMHeadModel.from_pretrained("uer/gpt2-chinese-lyric")
text_generator = TextGenerationPipeline(model, tokenizer)
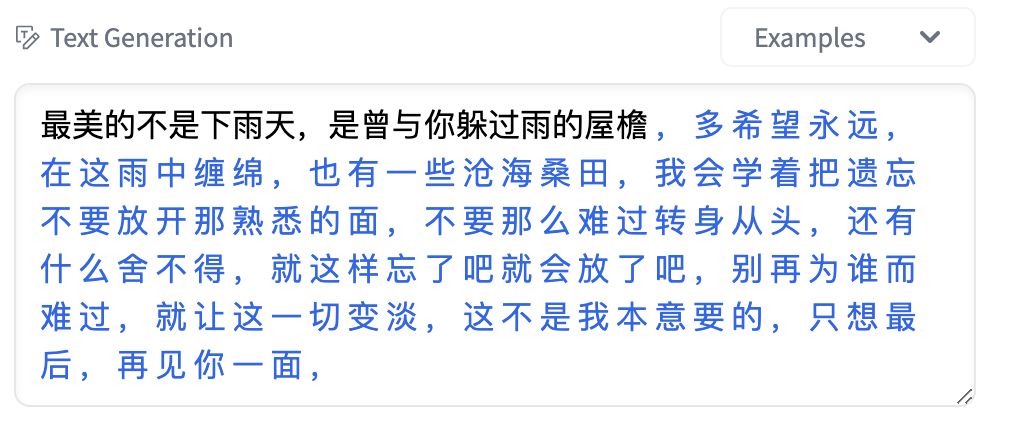
text_generator("最美的不是下雨天,是曾与你躲过雨的屋檐", max_length=100, do_sample=True)GPT2
数据预处理部分
数据样式:
数据使用了deepmind整理的cnnstory部分数据:
原始数据样式如下:
(CNN)Syria is a Hell on Earth that is expanding in plain sight.
The death toll there has doubled in a year's time, if an opposition group is right.
Since civil war broke out there, 310,000 people have been killed, the Syrian Observatory for Human Rights said Thursday. A year earlier, SOHR's tally stood at 162,402. And the year before, the United Nations put the death toll at 70,000.
Violence has plunged well over half of all Syrians into such destitution that they are in dire need of survival aid, the United Nations says, as food rations are being cut for lack of donations.
Numbers alone can't convey the immeasurable anguish of millions, but maybe it can remind the rest of us of the magnitude of the world's currently greatest tragedy.
The number of years since perpetual bloodshed began, since dictator Bashar al-Assad's security forces fired on crowds of demonstrators and armed militant groups rose up against him in March 2011.
Percentage of the Syrian population killed. It would be like killing 3 to 4 million Americans. The range comes from the SOHR's death toll of 310,000 and a recent lower estimate by the U.N. of at least 220,000 dead.
The number of Syrians in need of immediate life-saving aid, according to the U.N. That's the population of Moscow.
Syrians driven from their homes, the U.N. says. Imagine the entire Boston metropolitan area emptied out.
Syrians who have fled as refugees to neighboring countries, creating humanitarian and economic hardship across Syria's borders. Turkey has taken in 1.7 million, Lebanon 1.2 million, Jordan 625,000, and Iraq 245,000.
The reduction in the size of food rations the World Food Programme says it has been forced to make due to a lack of donations. That means people receiving aid will get only 60% of the daily nutrition they need.
@highlight
More people have been displaced than live in Moscow; more people lost their homes than live in greater Boston
@highlight
The WFP has cut food ration sizes by 30% for lack of donations上面数据@highlight部分就是文章的摘要部分
#这个文件命名为until.py,
import random
import numpy as np
import torch
import torch.nn.functional as F
from transformers import GPT2Tokenizer
from tqdm import tnrange
#下面方法主要用来做gptencode
def add_special_tokens():
""" Returns GPT2 tokenizer after adding separator and padding tokens """
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
special_tokens = {'pad_token':'<|pad|>','sep_token':'<|sep|>'}
num_add_toks = tokenizer.add_special_tokens(special_tokens)
return tokenizer
def set_seed(args):
random.seed(args.seed)
np.random.seed(args.seed)
torch.manual_seed(args.seed)
if args.n_gpu > 0:
torch.cuda.manual_seed_all(args.seed)
def top_k_top_p_filtering(logits, top_k=0, top_p=0.0, filter_value=-float('Inf')):
""" Filter a distribution of logits using top-k and/or nucleus (top-p) filtering
Args:
logits: logits distribution shape (vocabulary size)
top_k > 0: keep only top k tokens with highest probability (top-k filtering).
top_p > 0.0: keep the top tokens with cumulative probability >= top_p (nucleus filtering).
Nucleus filtering is described in Holtzman et al. (http://arxiv.org/abs/1904.09751)
From: https://gist.github.com/thomwolf/1a5a29f6962089e871b94cbd09daf317
"""
assert logits.dim() == 1 # batch size 1 for now - could be updated for more but the code would be less clear
top_k = min(top_k, logits.size(-1)) # Safety check
if top_k > 0:
# Remove all tokens with a probability less than the last token of the top-k
indices_to_remove = logits < torch.topk(logits, top_k)[0][..., -1, None]
logits[indices_to_remove] = filter_value
if top_p > 0.0:
sorted_logits, sorted_indices = torch.sort(logits, descending=True)
cumulative_probs = torch.cumsum(F.softmax(sorted_logits, dim=-1), dim=-1)
# Remove tokens with cumulative probability above the threshold
sorted_indices_to_remove = cumulative_probs > top_p
# Shift the indices to the right to keep also the first token above the threshold
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
indices_to_remove = sorted_indices[sorted_indices_to_remove]
logits[indices_to_remove] = filter_value
return logits
def sample_seq(model, context, length, device, temperature=1, top_k=0, top_p=0.0):
""" Generates a sequence of tokens
Args:
model: gpt/gpt2 model
context: tokenized text using gpt/gpt2 tokenizer
length: length of generated sequence.
device: torch.device object.
temperature >0: used to control the randomness of predictions by scaling the logits before applying softmax.
top_k > 0: keep only top k tokens with highest probability (top-k filtering).
top_p > 0.0: keep the top tokens with cumulative probability >= top_p (nucleus filtering).
"""
context = torch.tensor(context, dtype=torch.long, device=device)
context = context.unsqueeze(0)
generated = context
with torch.no_grad():
for _ in tnrange(length):
inputs = {'input_ids': generated}
outputs = model(**inputs) # Note: we could also use 'past' with GPT-2/Transfo-XL/XLNet (cached hidden-states)
next_token_logits = outputs[0][0, -1, :] / temperature
filtered_logits = top_k_top_p_filtering(next_token_logits, top_k=top_k, top_p=top_p)
next_token = torch.multinomial(F.softmax(filtered_logits, dim=-1), num_samples=1)
generated = torch.cat((generated, next_token.unsqueeze(0)), dim=1)
return generated
def beam_search(model, context, length, beam_size, device, temperature=1):
""" Generate sequence using beam search https://machinelearningmastery.com/beam-search-decoder-natural-language-processing/
Args:
model: gpt/gpt2 model
context: tokenized text using gpt/gpt2 tokenizer
length: length of generated sequence.
beam_size: >=1 and <= total_no_of_tokens
device: torch.device object.
temperature >0: used to control the randomness of predictions by scaling the logits before applying softmax.
"""
context = torch.tensor(context, dtype=torch.long, device=device)
context = context.unsqueeze(0)
with torch.no_grad():
inputs = {'input_ids': context}
outputs = model(**inputs)
next_token_logits = outputs[0][0, -1, :] / temperature
next_token_probs = F.softmax(next_token_logits)
scores, indices = torch.topk(next_token_probs, beam_size)
indices = indices.tolist()
sequences = [[c] for c in indices]
for _ in tnrange(length-1):
logits = torch.zeros(beam_size*len(next_token_logits))
for j in range(len(sequences)):
new_generated = torch.cat((context,torch.tensor([sequences[j]], dtype=torch.long, device=device)),dim=1)
inputs = {'input_ids': new_generated}
outputs = model(**inputs)
next_token_logits = outputs[0][0, -1, :] / temperature
next_token_probs = F.softmax(next_token_logits)
start, stop = j*len(next_token_logits), (j+1)*len(next_token_logits)
logits[start:stop] = scores[j]*next_token_probs
scores, new_logits_indices = torch.topk(logits,beam_size)
logits = (new_logits_indices%50259).tolist()
for j in range(len(sequences)):
sequences[j] = sequences[j]+[logits[j]]
return scores, sequences
def generate_beam_sample(data, tokenizer, model, num=1, length=100, beam_size=3, device=torch.device('cuda')):
""" Generate summaries for "num" number of articles using beam search.
Args:
data = GPT21024Dataset object
tokenizer = gpt/gpt2 tokenizer
num = number of articles for which summaries has to be generated
"""
for i in range(num):
sample = data[i]
idx = sample['sum_idx']
context = sample['article'][:idx].tolist()
summary = sample['article'][idx+1:][:100].tolist()
scores, sequences = beam_search(model, context, length, beam_size, device)
print('new_article', end='\n\n')
print(tokenizer.decode(context[:-1]), end='\n\n')
print('actual_summary', end='\n\n')
print(tokenizer.decode(summary), end='\n\n')
for i in range(len(sequences)):
text = tokenizer.convert_ids_to_tokens(sequences[i],skip_special_tokens=True)
text = tokenizer.convert_tokens_to_string(text)
print("generated_summary-{} and Score is {}.".format(i+1, scores[i]), end='\n\n')
print(text, end='\n\n')
def generate_sample(data, tokenizer, model, num=1, eval_step=False, length=100, temperature=1, top_k=10, top_p=0.5, device=torch.device('cuda')):
""" Generate summaries for "num" number of articles.
Args:
data = GPT21024Dataset object
tokenizer = gpt/gpt2 tokenizer
model = gpt/gpt2 model
num = number of articles for which summaries has to be generated
eval_step = can be True/False, checks generating during evaluation or not
"""
for i in range(num):
sample = data[i]
idx = sample['sum_idx']
context = sample['article'][:idx].tolist()
summary = sample['article'][idx+1:][:100].tolist()
generated_text = sample_seq(model, context, length, device, temperature, top_k, top_p)
generated_text = generated_text[0, len(context):].tolist()
text = tokenizer.convert_ids_to_tokens(generated_text,skip_special_tokens=True)
text = tokenizer.convert_tokens_to_string(text)
if eval_step==False:
print('new_article', end='\n\n')
print(tokenizer.decode(context), end='\n\n')
print("generated_summary", end='\n\n')
print(text, end='\n\n')
print('actual_summary', end='\n\n')
print(tokenizer.decode(summary), end='\n\n')
else:
print(tokenizer.decode(context), end='\n\n')
print("generated_summary", end='\n\n')把数据转成一篇文章对应一个json文件格式,json包括article、abstract两部分,同时对文本做gptencode编码处理代码如下:
import json
import os
import pickle
import sys
import time
from utils import add_special_tokens
#tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
dm_single_close_quote = '\u2019' # unicode
dm_double_close_quote = '\u201d'
# acceptable ways to end a sentence
END_TOKENS = ['.', '!', '?', '...', "'", "`", '"',
dm_single_close_quote, dm_double_close_quote, ")"]
def fix_missing_period(line):
"""Adds a period to a line that is missing a period"""
if "@highlight" in line:
return line
if line == "":
return line
if line[-1] in END_TOKENS:
return line
return line + " ."
def get_art_abs(lines):
""" return as list of sentences"""
# truncated trailing spaces, and normalize spaces
lines = [' '.join(line.strip().split()) for line in lines]
lines = [fix_missing_period(line) for line in lines]
# Separate out article and abstract sentences
article_lines = []
highlights = []
next_is_highlight = False
for idx, line in enumerate(lines):
if line == "":
continue # empty line
elif line.startswith("@highlight"):
next_is_highlight = True
elif next_is_highlight:
highlights.append(line)
else:
article_lines.append(line)
return ' '.join(article_lines), ' '.join(highlights)
def write_json(i,article, abstract):
""" Saves a json file."""
file = "./gpt2_1024_data/"+str(i)+".json"
js_example = {}
js_example['id'] = i
js_example['article'] = article
js_example['abstract'] = abstract
with open(file, 'w') as f:
json.dump(js_example, f, ensure_ascii=False)
def main(file_names, directory):
""" Reads txt files, extract articles and summaries, tokenize them and save as json files
Args:
file_names: list, all the articles with total no of tokens less than 1024
directory: string, directory where files in file_names is stored
"""
tokenizer = add_special_tokens()
print("Execution Started...")
train_ids = []
file_id_map = {}
i = 0
for file in file_names:
file = os.path.join(os.getcwd(),directory,file)
with open(file,'r',encoding='utf-8') as f:
lines = f.read().split('\n\n')
article, abstract = get_art_abs(lines)
article, abstract = tokenizer.encode(article), tokenizer.encode(abstract)
if len(article)>0 and len(abstract)>0 and (len(article)+len(abstract))<=1023:
train_ids.append(i)
write_json(i,article,abstract)
file_id_map[i] = os.path.basename(file).replace('.story', '')
i += 1
if i%100==0:
print(i, " files written")
x,y = int(len(train_ids)*0.8), int(len(train_ids)*0.9)
valid_ids = train_ids[x:y]
test_ids = train_ids[y:]
train_ids = train_ids[:x]
with open("ids.json",'w') as f:
js = {}
js['train_ids'] = train_ids
js['valid_ids'] = valid_ids
js['test_ids'] = test_ids
json.dump(js,f)
# file_id_map maps the json file ids to actual cnn/dm file names ending with ".story"
print("saving file_id_map...")
with open("file_id_map.pickle", 'wb') as f:
pickle.dump(file_id_map,f)
print("file_id_map saved.")
if __name__ == '__main__':
start = time.time()
with open(sys.argv[1],'rb') as f:
file_sizes = pickle.load(f)
file_names = [file for file,size in file_sizes.items() if size<=1023] #only consider files with total no of tokens less than 1024
if sys.argv[1].startswith("cnn"):
directory = "cnn_stories_tokenized"
os.chdir('/CNN/')
else:
directory = "dm_stories_tokenized"
os.chdir('./DM/')
main(file_names, directory)
print("total_time_taken: ", (time.time()-start)/60, " minutes")处理完的数据格式如下
{"id": 0, "article": [12, 43, 27912, 12, 8100, 532, 21095, 33, 12, 1377, 7214, 4621, 286, 262, 890, 5041, 351, 257, 474, 5978, 284, 534, 17627, 764, 775, 1965, 1312, 6207, 3816, 284, 2648, 5205, 286, 511, 4004, 7505, 3952, 5636, 2171, 764], "abstract": [9787, 503, 8100, 13, 785, 7183, 705, 7505, 3952, 5205, 764, 1471, 19550, 287, 319, 262, 995, 705, 82, 27627, 6386, 1660, 19392, 764]}模型训练部分
#这部分代码拷贝命名'dataset.py'
import os
import json
import numpy as np
import torch
from torch.utils.data import Dataset
from utils import add_special_tokens
class GPT21024Dataset(Dataset):
def __init__(self, root_dir, ids_file, mode='train',length=None):
self.root_dir = root_dir
self.tokenizer = add_special_tokens()
# with open(ids_file,'r') as f:
# if mode=='train':
# self.idxs = np.array(json.load(f)['train_ids'])
# elif mode=='valid':
# self.idxs = np.array(json.load(f)['valid_ids'])
# elif mode=='test':
# self.idxs = np.array(json.load(f)['test_ids'])
# self.idxs = self.idxs -min(self.idxs)
self.idxs = os.listdir(root_dir)
self.mode = mode
if len == None:
self.len = len(self.idxs)
else:
self.len = length
def __len__(self):
return self.len
def __getitem__(self,idx):
if self.mode=='valid':
idx = self.idxs[-idx]
elif self.mode=='test':
idx = self.idxs[-idx-self.len] # assuming valid and test set of same sizes
else:
idx = self.idxs[idx]
# file_name = os.path.join(self.root_dir,str(idx)+".json")
file_name = os.path.join(self.root_dir,str(idx))
with open(file_name,'r') as f:
data = json.load(f)
text = self.tokenizer.encode(self.tokenizer.pad_token)*1024
content = data['article'] + self.tokenizer.encode(self.tokenizer.sep_token) + data['abstract']
text[:len(content)] = content
text = torch.tensor(text)
sample = {'article': text, 'sum_idx': len(data['article'])}
return sample#训练部分代码
import argparse
from datetime import datetime
import os
import time
import numpy as np
from transformers import GPT2LMHeadModel,AdamW, WarmupLinearSchedule
from torch.utils.tensorboard import SummaryWriter
import torch
from torch.nn import CrossEntropyLoss
import torch.nn.functional as F
from torch.utils.data import DataLoader, RandomSampler, SequentialSampler
from tqdm import tnrange, tqdm_notebook
from dataset import GPT21024Dataset
from utils import add_special_tokens, generate_sample, set_seed
#please change default arguments if needed
parser = argparse.ArgumentParser()
parser.add_argument("--lr",default=5e-5, type=float, help="learning rate")
parser.add_argument("--seed",default=42, type=int, help="seed to replicate results")
parser.add_argument("--n_gpu",default=1, type=int, help="no of gpu available")
parser.add_argument("--gradient_accumulation_steps",default=2, type=int, help="gradient_accumulation_steps")
parser.add_argument("--batch_size",default=1, type=int, help="batch_size")
parser.add_argument("--num_workers",default=4, type=int, help="num of cpus available")
parser.add_argument("--device",default=torch.device('cpu'), help="torch.device object")
parser.add_argument("--num_train_epochs",default=1, type=int, help="no of epochs of training")
parser.add_argument("--output_dir",default='./output', type=str, help="path to save evaluation results")
parser.add_argument("--model_dir",default='./weights', type=str, help="path to save trained model")
parser.add_argument("--max_grad_norm",default=1.0, type=float, help="max gradient norm.")
parser.add_argument("--root_dir",default='./CNN/gpt2_1024_data', type=str, help="location of json dataset.")
parser.add_argument("--ids_file",default='./CNN/ids.json', type=str, help="location of train, valid and test file indexes")
args = parser.parse_args([])
print(args)
def train(args, model, tokenizer, train_dataset, valid_dataset, ignore_index):
""" Trains GPT2 model and logs necessary details.
Args:
args: dict that contains all the necessary information passed by user while training
model: finetuned gpt/gpt2 model
tokenizer: GPT/GPT2 tokenizer
train_dataset: GPT21024Dataset object for training data
ignore_index: token not considered in loss calculation
"""
writer = SummaryWriter('./output/logs')
train_sampler = RandomSampler(train_dataset)
train_dl = DataLoader(train_dataset,sampler=train_sampler,batch_size=args.batch_size,num_workers=args.num_workers)
loss_fct = CrossEntropyLoss(ignore_index=ignore_index) #ignores padding token for loss calculation
optimizer = AdamW(model.parameters(),lr=args.lr)
scheduler = WarmupLinearSchedule(optimizer,100,80000)
global_step = 0
tr_loss, logging_loss = 0.0, 0.0
model.zero_grad()
train_iterator = tnrange(int(args.num_train_epochs), desc="Epoch")
set_seed(args)
for _ in train_iterator:
epoch_iterator = tqdm_notebook(train_dl, desc="Training")
for step, batch in enumerate(epoch_iterator):
inputs, labels = batch['article'].to(args.device), batch['article'].to(args.device)
model.train()
logits = model(inputs)[0]
# only consider loss on reference summary just like seq2seq models
shift_logits = logits[..., batch['sum_idx']:-1, :].contiguous()
shift_labels = labels[..., batch['sum_idx']+1:].contiguous()
loss = loss_fct(shift_logits.view(-1, shift_logits.size(-1)), shift_labels.view(-1))
loss = loss/args.gradient_accumulation_steps
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), args.max_grad_norm)
tr_loss += loss.item()
if (step + 1) % args.gradient_accumulation_steps == 0:
optimizer.step()
scheduler.step() # Update learning rate schedule
model.zero_grad()
global_step += 1
writer.add_scalar('lr', scheduler.get_lr()[0], global_step)
writer.add_scalar('loss', (tr_loss - logging_loss)/args.gradient_accumulation_steps, global_step)
logging_loss = tr_loss
print("loss:", loss.item(), end='\n\n')
if (step + 1)/args.gradient_accumulation_steps == 1.0:
print('After 1st update: ', end='\n\n')
generate_sample(valid_dataset, tokenizer, model, num=2, eval_step=False,device=args.device)
if (step + 1) % (10*args.gradient_accumulation_steps) == 0:
results = evaluate(args, model, valid_dataset, ignore_index, global_step)
for key, value in results.items():
writer.add_scalar('eval_{}'.format(key), value, global_step)
print('After', global_step+1,'updates: ', end='\n\n')
generate_sample(valid_dataset, tokenizer, model, num=2, eval_step=True,device=args.device)
# creating training and validation dataset object
train_data = GPT21024Dataset(args.root_dir,args.ids_file,mode='train',length=3000) #training on only 3000 datasets
valid_data = GPT21024Dataset(args.root_dir,args.ids_file,mode='valid',length=500) #validation on only 500 datasets
# load pretrained GPT2
tokenizer = add_special_tokens()
ignore_idx = tokenizer.pad_token_id
model = GPT2LMHeadModel.from_pretrained('gpt2')
model.resize_token_embeddings(len(tokenizer))
model.to(args.device)
#training the model
start = time.time()
train(args, model, tokenizer, train_data, valid_data, ignore_idx)
print('total time: ', (time.time()-start)/60, " minutes", end='\n\n')
print('Saving trained model...')
model_file = os.path.join(args.model_dir, 'model_data{}_trained_after_{}_epochs_only_sum_loss_ignr_pad.bin'.format(len(train_data),args.num_train_epochs))
config_file = os.path.join(args.model_dir, 'config_data{}_trained_after_{}_epochs_only_sum_loss_ignr_pad.json'.format(len(train_data),args.num_train_epochs))
torch.save(model.state_dict(), model_file)
model.config.to_json_file(config_file)训练好的模型做inference
import argparse
import os
from bs4 import BeautifulSoup
from googlesearch import search
import numpy as np
import requests
from transformers import GPT2Config, GPT2LMHeadModel
import torch
from tqdm import tnrange, tqdm_notebook
from dataset import GPT21024Dataset
from utils import add_special_tokens, beam_search, generate_beam_sample, generate_sample, sample_seq, set_seed, top_k_top_p_filtering
#please change default arguments if needed
parser = argparse.ArgumentParser()
parser.add_argument("--seed",default=42, type=int, help="seed to replicate results")
parser.add_argument("--num_workers",default=4, type=int, help="num of cpus available")
parser.add_argument("--device",default=torch.device('cuda'), help="torch.device object")
parser.add_argument("--output_dir",default='./output', type=str, help="path to save evaluation results")
parser.add_argument("--model_dir",default='./weights', type=str, help="path to save trained model")
parser.add_argument("--root_dir",default='./CNN/gpt2_1024_data', type=str, help="location of json dataset.")
parser.add_argument("--ids_file",default='./CNN/ids.json', type=str, help="location of train, valid and test file indexes")
args = parser.parse_args([])
print(args)
# using the same validation and training data as during training
tokenizer = add_special_tokens()
# train_data = GPT21024Dataset(args.root_dir,args.ids_file,mode='train',length=3000)
# valid_data = GPT21024Dataset(args.root_dir,args.ids_file,mode='valid',length=500)
test_data = GPT21024Dataset(args.root_dir,args.ids_file,mode='test',length=500)
# model_file and config_file are files used to load finetuned model, change these name as per your file names
# model_file = os.path.join(args.model_dir, 'model_data{}_trained_after_{}_epochs_only_sum_loss_ignr_pad.bin'.format(len(train_data),args.num_train_epochs))
# config_file = os.path.join(args.model_dir, 'config_data{}_trained_after_{}_epochs_only_sum_loss_ignr_pad.json'.format(len(train_data),args.num_train_epochs))
# path to model and config files
model_file = "345-model_O0_data3000_trained_after_5_epochs_only_sum_loss_ignr_pad.bin"
config_file = "345-config_O0_data3000_trained_after_5_epochs_only_sum_loss_ignr_pad.json"
config = GPT2Config.from_json_file(config_file)
model = GPT2LMHeadModel(config)
state_dict = torch.load(model_file)
model.load_state_dict(state_dict)
model.eval()
model.to(args.device)
generate_sample(test_data, tokenizer, model, num=2, length=100, temperature=1, top_k=10, top_p=0.5, device=args.device)生成结果:
HBox(children=(IntProgress(value=0), HTML(value='')))
new_article
Rome -LRB- CNN -RRB- -- A cruise ship of the Costa Cruises line is adrift off the coast of the Seychelles after a fire in its engine room, the Italian coast guard said Monday. The ship, the Allegra, is a sister of the Costa Concordia, which wrecked off the coast of Italy on January 13, killing at least 21 people. The fire left the Allegra without propulsion, although its communications equipment is intact, the authorities said. The Allegra's fire has been put out, and the passengers are all in good health, the authorities said. The Seychelles is sending a tug, and merchant ships in the area are steaming toward the Allegra, the coast guard said.
generated_summary
The ship is carrying cargo from the Seychelles . The ship was carrying cargo from the Seychelles . The ship was carrying cargo from the Seychelles . The ship was carrying cargo from the Seychelles . The ship was carrying cargo from the Seychelles . The ship was carrying cargo from the Seychelles . The ship was carrying cargo from the Seychelles . The ship was carrying cargo from the Seychelles . The ship was carrying
actual_summary
An engine room fire leaves the Costa Allegra without propulsion, authorities say. Its sister ship, the Costa Concordia, shipwrecked last month, killing at least 21. <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|> <|pad|>代码链接:https://github.com/AigcLwq/miniChatgpt.git
T5
下次迭代更新















 247
247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









