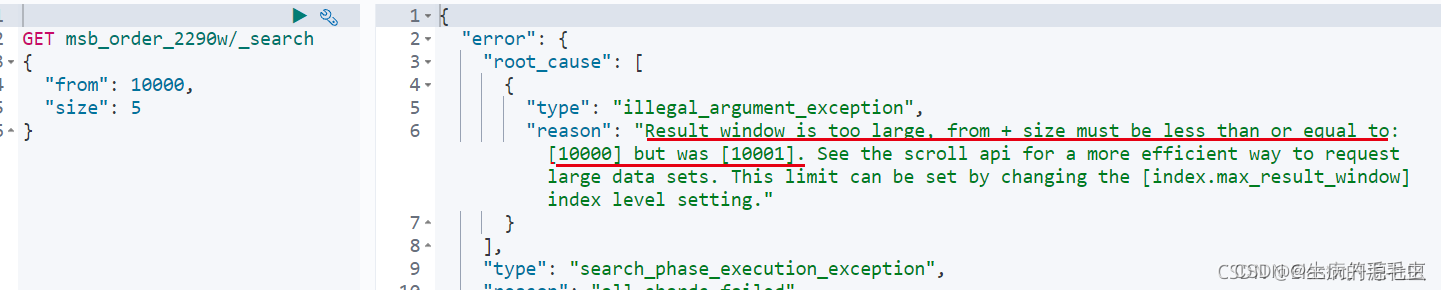
当我们需要查询的数据页数特别大的时候,比如from + size 大于10000 的时候,可能出现“window is too large” 异常,如下网图:
{
"query" : {
"bool" : {
"must" : [
{
"match_all" : { }
}
] ,
"must_not" : [ ] ,
"should" : [ ]
}
} ,
"from" : 10000 ,
"size" : 10 ,
"sort" : [ ] ,
"aggs" : { }
}
保存信息解释为,当前信息超过了10000最大值,虽然只查询了5条数据,为什么elasticSearch需要计算10000 条数据,因为查询的时候,需要按照一定规则排序,es如果不指定排序字段,会更具相关度评分排序
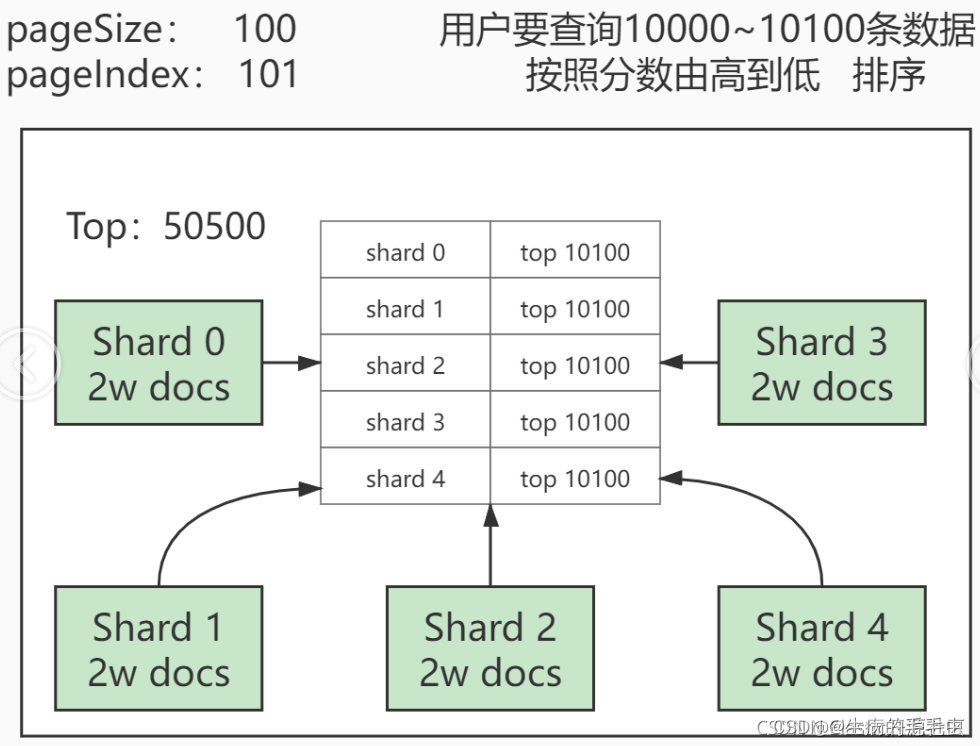
添加了10万条记录在exam_info索引中,并且elasticSearch是分布式部署的,那么这10W数据会分布在不同的分片上,假如又如上5个分片,那么5个分片的数据一定会是近似均匀的 每个2w条。 现在需要查询10001 到11000 的这一千条信息,按照 A 字段排序,那么我们查询的时候需要 查询出 shard1 ~ shard 4 每个分片中10001 ~ 11000 以A排序的所有数据,排序后取前1000 个,才能得到我们想要的数据,因为shard1 ~ shard4 存储顺序并不以A排序所以我们要对每一个分片进行筛选后得到一个排序值 每次有序查询都是分片中单独查询,在合并数据二次排序,这个二次排序过程是在heap(堆内存)中进行的,也就是单次查询数据越多,内存中汇总的数据就更多,数据越靠后,需要排序的数据越多,越容易导致OOM elasticSearch为了规避这种情况,设置了一个阈值,max_result_window 默认值是10000,包含堆内存不被错误操作导致溢出 规避错误,将跳页功能删掉,不让直接查看第N页的数据,包括百度,google,淘宝等分页请求也是这么干的。如下:
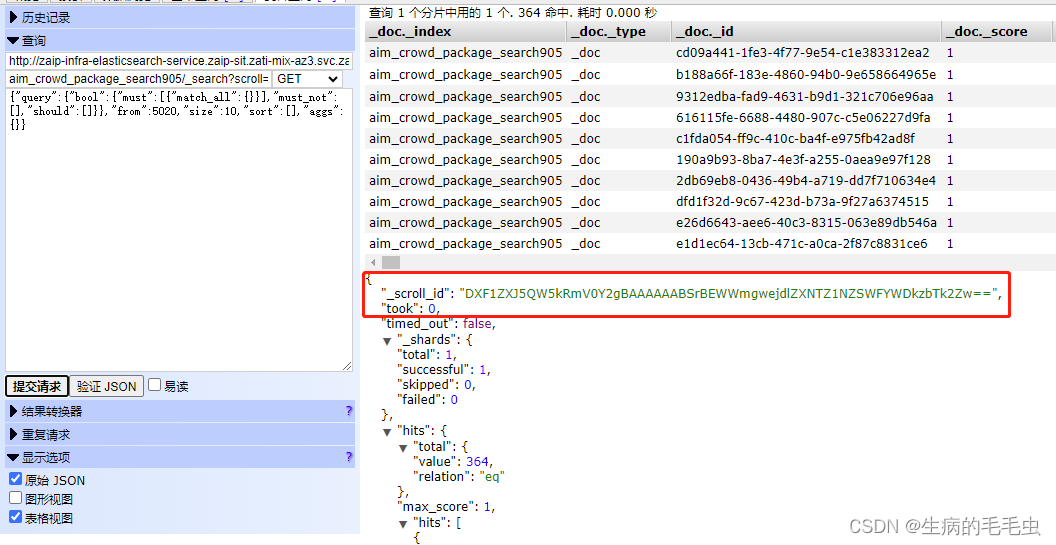
GET aim_crowd_package_search905/ _search? scroll= 1m
{
{ "query" : { "bool" : { "must" : [ { "match_all" : { } } ] , "must_not" : [ ] , "should" : [ ] } } , "from" : 5020 , "size" : 10 , "sort" : [ ] , "aggs" : { } }
}
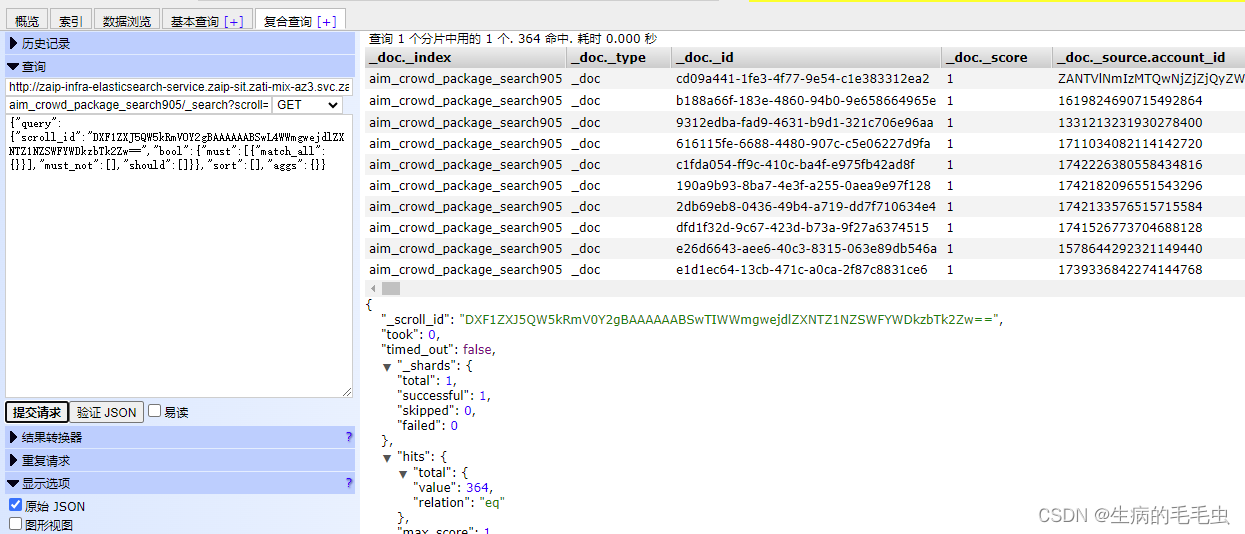
上述请求的结果包含一个_scroll_id,可以通过这个id来完成下一批次的请求,也就是elasticSearch帮我们圈了一批数据,第一次查询给了一个标记位_scroll_id,之后的查询我们只需用代码这个,elasticSearch会直接给我们查第二页的数据。如下图,第二次带上scroll_id, 查询语句: GET aim_crowd_package_search905/ _search? scroll= 1m
{
{ "query" : { "scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAABSwL4WWmgwejdlZXNTZ1NZSWFYWDkzbTk2Zw==" , "bool" : { "must" : [ { "match_all" : { } } ] , "must_not" : [ ] , "should" : [ ] } } , "sort" : [ ] , "aggs" : { } }
}
如上案例看出 scroll search 查询的智能一页,一页给你返回,这样可能不满足很多C端口业务场景 而且,elasticSearch为了限制资源,对scrolls的数量又一定限制,最多打开500个,可以通过集群设置修改:search.max_open_scroll_context 不支持向前搜索 每次搜后一页数据 不适用于C端业务 第一点:按一定规则排序,例如自增id排序,查询第二页,带上 id > X, 此处X是第一页最后一条数据;这样每次只需用查询一页数据就能满足分页查询 第二点:解决跳页问题:
当跳页时候,无法获取到前一页数据,以上规则不适用 缓存,空间换时间,每次查询预加载前后5页的id顺序数据,前端只支持10个页面跳转,这样无论那一页都能拿到前一页数据
























 2851
2851











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









