









- [ ] normalized initialization & intermediate normalization layers addresses vanishing/exploding gradients.
- [ ] stochastic gradient descent
- [ ] stationary points
- [ ] identity mapping
- [ ] vector quantization
Stochastic gradient descent
Stochastic gradient descent (often shortened in SGD), also known as imcremental gradient descent, is a stochastic approximation of the gradient descent optimization method for minimizing an objective function that is written as a sum of differentiable functions. In other words, SGD tries to find minimums or maximums by iteration.
Minimize an objective function that has the form of a sum:
When used to minimize the above function, a standard (or “batch”) gradient descent method would perform the following iterations:
To economize on the computational cost at every iteration, stochastic gradient descent samples a subset of summand functions at every step. This is every effective in the case of large-scale machine learning problems
Iterative method
In stochastic (or “on-line”) gradient descent, the true gradient of
Q(w)
is approximated by a gradient at a single example:
In pseudocode, stochastic gradient descent can be presented as follows:
- Choose an initial vector of parameters w and learning rate
η .- Repeat until an approximate minimum is obtained:
- Randomly shuffle examples in the training set.
- for i=i,2,...,n , do:
- w:=w−η▽Qi(w) .
A compromise between computing the true gradient and the gradient at a single example, is to compute the gradient against more than one training example (called a “mini-batch”) at each step. This can perform significantly better than true stochasitc gradient descent because the code can make use of vectorization libaries rather than computing each step separately. It may alse result in smoother convergence, as the gradient computed at each step uses more training examples.
The convergence of stochastic gradient descent has been analyzed using the theories of convex minimization and of stochastic approximation. Briefly, when the learning rats η decrease with an appropriate rate, and subject to relatively mild assumptions, stochastic gradient descent converges alomost surely to a global minimum when the objective function is convex or pseudoconvex, and otherwise converges almost surely to a local minimum. This is in fact a consequence of the Robbins-Siegmund theorem.
Example
Let’s suppose we want to fit a straight line
y=w1+w2x
to a training set of two-dimensional points
(x1,y1)
,…,
(xn,yn)
using least squares. The objective function to be minimized is:
The last line in the above pseudocode for this specific problem will become:
Related Work
- [ ] What is a scale in Residual Representations.
- [ ] What is an identity mapping?
Deep Residual Learning for Image Recognition
Abstract
We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously.
1. Introduction
Recent evidence reveals that network depth is of crucial importance, and the leading results on the challenging ImageNet dataset all exploit “very deep” models, with depth of sixteen to thirty. Many other nontrivial visual recognition tasks have also greatly benefited from very deep models.
Driven by the significance of depth, a question arises: Is learning better networks as easy as stacking more layers? An obstacle to answering this question was the notorious problem of vanishing/exploding gradients, which hamper convergence from the beginning.
When deeper networks are able to start converging, a degradation problem has been exposed: with the network depth increasing, accuracy gets saturated (which might be unsurprising) and the degrades rapidly. Unexpectedly, such degradation is not caused by overfitting, and adding more layers to a suitable deep model leads to higher training error.
In this paper, we address the degradation problem by introducing a deep residual learning framework. Formally, denoting the desired underlying mapping as H(x) , we let the stacked nonlinear layers fit another mapping of F(x):=H(x)−x . The original mapping is recast into F(x)+x . We hypothesize that it is easier to optimize the residual mapping than to optimize the original, unreferenced mapping.
[x] what is the identity mapping
A new paper by Kaiming He.
2. Related Work
Residual Learning
In image recognition, shallow representation for image retrieval and classification:
- VLAD is a representation that encodes by the residual vectors with respect to dictionary
- Fisher Vector can be formulated as a probabilistic version of VLAD.
For vector quantization, encoding residual vectors is shown to be more effective than encoding original vectors.
List some examples that can suggest that a good reformulation or preconditioning can simplify the optimization.
Shortcut Connections
In our residual network, the reformulation always learns residual functions; our identity shortcuts are never closed, and all information is always passed through, with additional residual functions to be learned.
3. Deep Residual Learning
3.1 Residual Learning
- [ ] zero mapping?
This reformulation is motivated by the counterintuitive phenomena about the degradation problem, i.e. the deeper network has higher training error, and thus test error. The degradation problem suggests that the solvers might have difficulties in approximating identity mappings by multiple nonlinear layers.
In real cases, it is unlikely that identity mappings are optional, but our reformulation may help to precondition the problem. If the optional function is closer to identity mapping than to a zero mapping, it should be easier for the solver to find the perturbations with reference to an identity mapping, than to learn the function as a new one.
3.2 Identity Mapping by Shortcuts
A building block is shown as figure, defined as:
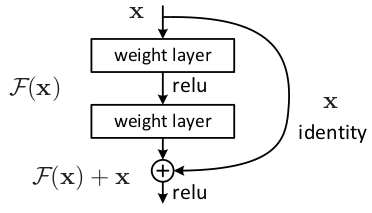
Here x and y are the input and output vectors of the layers considered. The function F(x,{Wi})+x represents the residual mapping to be learned. For the example in the figure that has two layers, F=W2σ(W1x) in which σ denotes ReLU and the biases are omitted for simplifying notations. The operation F+x is performed by a shortcut connection and element-wise addition. We adopt the second nonlinearity after the addition.
The dimensions of x and
F
must be equal in previous equation. If this is not the case, we can perform a linear projection
- [ ] how to understand channal?
Network Architectures
- Plain Network
- Residual Network
3.4 Implementation
- [ ] per-pixel mean substracted
4. Experiments
4.1 ImageNet Classification
Experiments
Facebook has implemented the deep residual network using torch, here is the github project fb.resnet.torch.
To run an experiment:
th main.lua -dataset cifar10 -depth 20 -save DIRECTORY_TO_SAVE














 1051
1051

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









