







目录
1,训练时拓扑结构变化的网络
有些网络在训练的时候会随机丢弃一些网络节点,节点之间的连接或者网络模块来增强网络的泛化能力。常用的在训练的时候使用的方法有以下两种。
1.1 Dropout与 Drop Connect
1)Dropout
dropout在全连接层使用。在训练阶段,对于每个节点,以p概率将其输出值保留,以1-p概率将其输出值乘以0。在测试阶段,输出结果要乘以p。原因是:保持训练阶段和测试阶段的期望值相同。训练阶段,对于每个节点,dropout之前的输出是x, 经历dropout之后的期望值是p*x+(1-p)*0=px,因此在测试阶段需要将结果乘以p,从而输出的期望值是px。测试阶段乘以p会增加计算量,所以改进的版本是训练阶段将输出值再除以p。这样测试阶段不需要任何增加的计算
Dropout作用:通过阻止特征检测器的共同作用来提高神经网络的性能可以看出,网络在提取训练集特征时,舍弃掉了一部分特征来提高网络的泛化能力。
2)Drop Connect
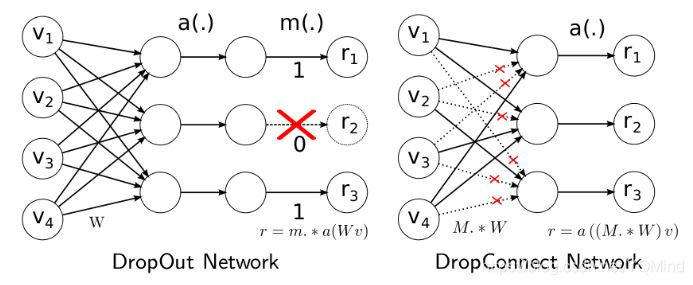
Dropout是将输出随机置0,而DropConnect是将权重随机置0。 文章说之所以这么干是因为原来的Dropout进行的不够充分,随机采样不够合理。
训练的时候,训练过程与Dropout基本相同。测试的时候,我们同样需要一种近似的方法。但其实发现效果并不比Dropout优秀太多,反而计算量要大很多,因此到目前DropConnect并没有得到广泛的应用。下图是两种方法的区别。
1.2 Stochastic Depth(随机深度)
2016年,也就是ResNet被提出的下一年,清华的黄高(也是DenseNet的提出者)在EECV会议上提出了Stochastic Depth(随机深度网络)。这个网络主要是针对ResNet训练时做了一些优化,即随机丢掉一些层,优化了速度和性能(有点类似于Dropout的效果)
ResNet这个里程碑式的创新对AI领域带来了深远的影响。然而,作者发现ResNet网络中不是所有的层都是必要的,因此结合经典的Dropout思想提出在训练过程中随机丢弃丢掉一些层来优化ResNet的训练过程。
首先来看一下原始的ResNet结构,其中f 代表的是残差部分,i d代表的是恒等映射,把这两部分求和经过激活然后然后输出。这个过程可以用下面的式子来表示:
如下图所示:
Stochastic Depth(随机深度网络)就是在训练时加入了一个随机变量b ,其中b的概率分布是满足一个伯努利分布的,然后将f乘以b,对残差部分做了随机丢弃。如果b = 1,这个结构即是原始的ResNet结构,而当b = 0 时,残差支路没有被激活,整个结构退化为一个恒等函数。这个过程可以用下面的等式来表示:

b满足一个伯努利分布(01分布),它的取值只有0和1两种,其中取0的概率为1 − p,取1的概率是p。上面的p又被称为生存概率,这个p 即代表了b = 1 的可能性,因此p的设置相当重要。


Stochastic Depth(随机深度网络)在训练的时候是一个比测试时候更浅的网络(在训练的时候随机删减一些残差模块,在测试的时候使用所有的单元)。实验证明,这不仅减少了训练的时间,而且随机删减后,测试精度在数据集CIFAR10上有所提升。与基础的ResNet结构相比,其拟合程度大大降低,当网络到达1000层以上,性能依旧不错,不仅没有过拟合。相对于ResNet152还有提升。
2,测试时拓扑结构变化的网络
通常网络在训练后网络就是固定的,测试的时候沿着固定的通路进行计算。然而测试本身有不同的难度,简单的样本只需要少量的计算量就可以完成任务,困难的任务则需要更多的计算量。因此研究者设计了一些网络结构,它可以根据不同的难度使用不同的计算支路。这就是在测试的时候拓扑结果变化的网络。
2.1 BranchyNet
这是一个推理时动态变化的网络结构,如下图所示,它在正常网络通道上包含了多个旁路分支,这样的思想是基于观察到随着网络的加深,表征能力越来越强,大部分简单的图片可以在较浅层时学习到足以识别的特征,如图中的Exit 1通道。一些更难的样本需要进一步的学习,如上图中的Exit 2通道,而只有极少数样本需要整个网络,如Exit3通道。这样的思想可以实现精度和计算量的平衡,对于大部分样本,可以用更小的计算量完成任务。
链接:https://www.zhihu.com/question/337470480/answer/766380855
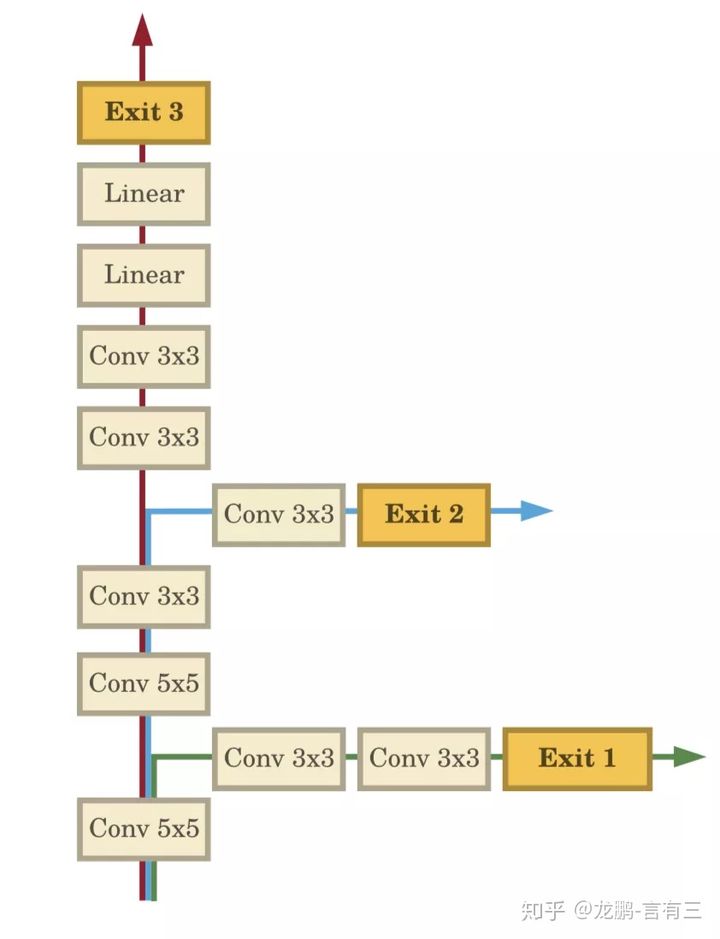
那么如何判断是否可以提前结束呢?在提出该网络的论文中,作者采用分类信息熵,一旦该通道的分类信息熵低于某一个阈值,说明已经以很高的置信度获得了分类的结果,直到最终的通道。
在训练的时候,每一个通道都会对损失有贡献,越靠近浅层的网络权重越大。多通道的损失不仅增强了梯度信息,也在一定程度上实现了正则化。
将BranchyNet的设计思想用于LeNet,AlexNet,ResNet结构后,在维持性能的前提下,加速效果明显。
2.2 Blockdrop
Stochastic Depth(随机深度网络)在训练的时候是一个比测试时候更浅的网络(在训练的时候随机删减一些残差模块,在测试的时候使用所有的单元)。Blockdrop则是从学习到对不同的样本可以丢弃的残差块。两者的根本区别是Stochastic Depth训练的时候变化测试的时候不变化,Blockdrop是训练的时候不变化,测试的时候发生变化,后者节省更多的计算量。
Blockdrop的思想是学习一种策略网络,对于输入图像,它会学习每一个模块是应该保留还是丢弃。假设有4个残差模块。策略网络学习到的是使用第一个和第三个残差结构,在测试的时候就会值使用1和3,而将2和4丢弃。
2.3 SkipNet
SkipNet主要是以此假设出发,通过在传统CNN的每个layer(或module)上设置判断其是否需要执行的Gate module来决定是否需要真的执行此层计算,若判断为否则直接将activation feature maps传入到下一层,越过当下层的运算不做。无益这样做可以有效地节省传统CNN模型在部署时进行推理工作所需的时间。
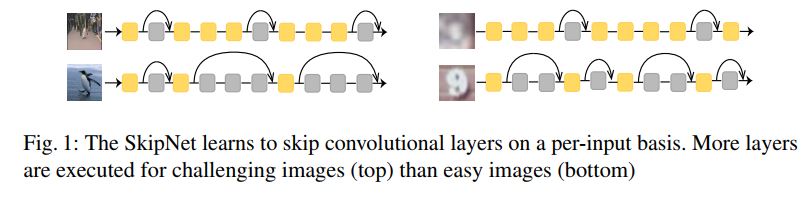
就这样一旦训练好,SkipNet在做图片推理时可根据输入的feature maps不同灵活地决定是否执行某一网络中的层。下图可反映SkipNet这一根本特点。

















 369
369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









