







论文提出了经典的Vision Transormer模型Swin Transformer,能够构建层级特征提高任务准确率,而且其计算复杂度经过各种加速设计,能够与输入图片大小成线性关系。从实验结果来看,Swin Transormer在各视觉任务上都有很不错的准确率,而且性能也很高
来源:晓飞的算法工程笔记 公众号
论文: Swin Transformer: Hierarchical Vision Transformer using Shifted Windows

Introduction
长期以来,计算机视觉建模一直由卷积神经网络(CNN)主导。从AlexNet在ImageNet中的革命性表现开始,通过更大的规模、更广泛的连接以及更复杂的卷积形式逐级演变出越来越强大的CNN架构。另一方面,自然语言处理(NLP)网络架构的演变则采取了不同的路径,如今最流行的就是Transformer架构。Transformer专为序列建模和转导任务而设计,以使用注意力来建模数据中的长距离关系而著称。
Transformer在语言领域的巨大成功促使研究人员研究其在计算机视觉的适应性,目前也取得了很不错的结果,特别是用于图像分类的ViT以及用于视觉语言联合建模的CLIP。
本文作者尝试扩展Transformer的适用性,将其用作计算机视觉的通用主干,就像Transformer在NLP和CNN在视觉中所做的那样。将Transformer在语言领域的高性能表现转移到视觉领域所面临的主要挑战,主要源自两个领域之间的差异:
- 尺寸。token作为NLP Transformer中的基本元素,其尺寸是固定的,对应段落中的一个单词。但视觉目标的尺寸可能有较大的差异,这也是如物体检测等任务备受关注的问题,通常需要捕获多尺度特征来解决。而在现有的基于Transformer的模型中,token都是固定尺寸的,对应一个单词或固定的图片区域,显然不适用于当前的视觉应用任务。
- 数量级。与文本段落中的单词数量相比,图像中的像素数量要多很多。在许多如语义分割的视觉任务中,需要进行像素级的密集预测。而Transformer在高分辨率图像上的处理是难以进行的,因为自注意力的计算复杂度与图像大小成二次方关系。
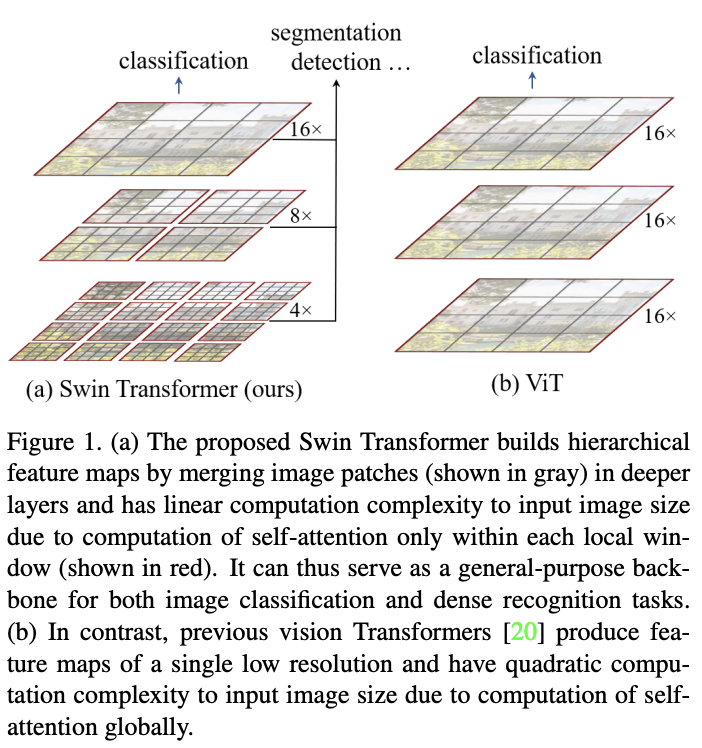
为了解决这些问题,论文提出了Swin Transformer,能够构建层级特征图并且计算复杂度与图像大小成线性关系。
基于层级特征图,Swin Transformer模型可以很方便地结合先进的密集预测技术,如特征金字塔网络(FPN)或U-Net。如图1a所示,Swin Transformer从小尺寸的图像块开始,逐渐合并相邻图像块来构建层级特征。线性计算复杂度则是通过只在局部非重叠窗口(图1a红色区域)计算自注意力来实现的。由于窗口大小是固定的,所以复杂度与图像大小成线性关系。
Swin Transformer还有一个关键设计元素,就是在连续的同尺度self-attention层使用移位窗口分区(shifted window partition)。类似于对分组卷积的分组间通信优化,移位窗口能够促进前一层的窗口之间的特征融合,从而显著提高建模能力。常见的基于滑动窗口(sliding window)的自注意力,由于每个query对应的key集不同,所以都要单独计算注意力矩阵然后输出,实现上很低效。而移位窗口由于仅在窗口内进行自注意力计算,同窗口内的query对应的key集相同,key集可在窗口内共享,可直接单次矩阵计算同时完成全部注意力计算然后输出,在实现上十分高效。
Swin Transformer在图像分类、目标检测和语义分割的识别任务上取得了很不错的结果。在速度相似的情况下,准确率显著优于ViT/DeiT和ResNe(X)t模型。在COCO test-dev数据集上达到的58.7 box AP和51.1 mask AP,分别比SOTA高2.7和2.6。在ADE20K val数据集集上获得了 53.5 mIoU,比SOTA高3.2。在ImageNet-1K数据集上达到了87.3%的top-1准确率。
Method
Overall Architecture
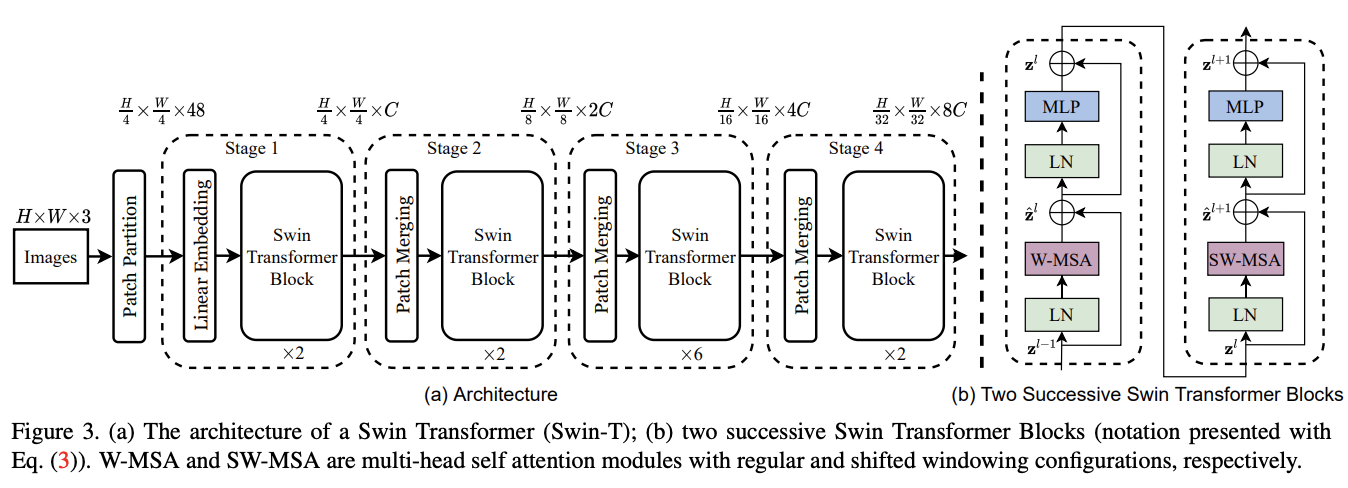
Swin Transformer整体架构如图3所示,该图是Tiny版本Swin-T,分为以下几个部分:
- Patch Partition:输入图像的处理跟ViT类似,通过patch splitting模块将输入的RGB图像分割成不重叠的图像块,直接将每个图像块内的RGB值concate起来作为一个token。在实现时,每个图像块的大小为 4 × 4 4\times 4 4×4,因此每个图像块的特征维度为 4 × 4 × 3 = 48 4\times 4\times 3 = 48 4×4×3=48。
- Linear Embedding:随后,Linear Embedding层对这个原始特征进行处理,将其映射到指定维度大小 C C C。
- Swin Transformer block:在得到图像块token后,连续使用多个包含改进自注意力的Transformer模块(Swin Transformer block)进行特征提取。
- Patch Merging:为了构建层级特征,随着网络变深,通过Patch Merging层减少token的数量。第一个Patch Merging层将每个维度的 2 × 2 2\times 2 2×2的相邻图像块特征concate起来,并在得到的 4 C 4C 4C维特征上使用Linear Embedding层进行维度映射。这样,token量就减少了 2 × 2 = 4 2\times 2 = 4 2×2=4的倍数(相当于两倍下采样)并且映射到指定维度大小 2 C 2C 2C,最后同样使用Swin Transformer blocks进行特征变换。
Linear Embedding与后续的Swin Transformer blocks一起称为Stage 1,token的数量为 H 4 × W 4 \frac{H}{4}\times \frac{W}{4} 4H×4W。第一个Patch Merging和Swin Transformer blocks称为Stage 2,分辨率保持在 H 8 ×
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1107
1107

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









