






LSTM(长短期记忆网络)和Transformer是两种在深度学习领域非常重要的模型,它们各自有独特的优势。将两者结合起来,可以充分发挥它们的优势,应用于多种复杂的任务中。
今天就这两种技术结合LSTM+Transformer整理出了10篇论文+开源代码,以下是精选部分论文
更多论文料可以关注 :AI科技探寻,发送:111 领取更多[论文+开源码】
:AI科技探寻,发送:111 领取更多[论文+开源码】
论文1
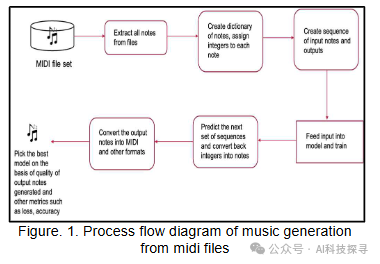
A Novel Bi-LSTM And Transformer Architecture For Generating Tabla Music
一种新颖的用于生成塔布拉鼓音乐的双向LSTM和Transformer架构
方法:
-
预处理:使用Python的librosa库对塔布拉鼓音乐的波形(.wav)文件进行预处理,提取特征和标签。
-
Bi-LSTM与注意力机制:训练一个带有注意力机制的双向长短期记忆(Bi-LSTM)模型,该模型包含两个LSTM层,分别处理输入序列的正向和反向,以捕获双向依赖关系。
-
Transformer模型:训练一个Transformer模型,该模型利用自注意力机制来处理输入序列,并通过多头注意力层、dropout层、密集层和层归一化层来生成输出序列。
-
损失函数与优化器:Bi-LSTM模型使用均方误差损失函数和Adam优化器,而Transformer模型使用稀疏分类交叉熵损失函数和Adam优化器进行训练。
创新点:
-
Bi-LSTM模型:通过引入注意力机制,Bi-LSTM模型能够更好地捕捉塔布拉鼓音乐序列中的长期依赖关系,实现了4.042的损失和1.0814的平均绝对误差(MAE)。
-
Transformer模型:尽管在塔布拉鼓音乐生成上的表现不如Bi-LSTM模型,但Transformer模型仍然能够产生具有节奏感的塔布拉鼓序列,其损失为55.9278,MAE为3.5173,显示出在处理序列数据时的潜力。
-
音乐生成质量:生成的塔布拉鼓音乐在新颖性和熟悉度之间达到了和谐的融合,推动了音乐创作的边界。
论文2
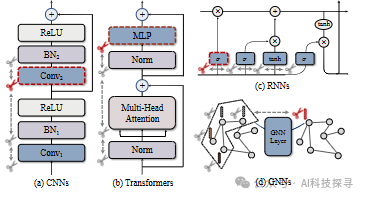
DepGraph Towards Any Structural Pruning
DepGraph:迈向任意结构剪枝
方法:
-
依赖图(DepGraph)构建:提出了一种通用且全自动的方法来显式建模层之间的依赖关系,并全面分组耦合参数以进行剪枝。
-
分组矩阵估计:通过递归过程在DepGraph上进行传播,以找到与给定层具有互依赖关系的所有耦合层,并构建分组矩阵G。
-
组级剪枝:利用简单的基于范数的标准来评估参数组的重要性,并通过稀疏训练方法使参数在组级别上稀疏化,以便安全地从网络中移除这些参数组。
-
实验验证:在多种架构和任务上广泛评估了该方法,包括ResNe(X)t、DenseNet、MobileNet、Vision Transformer、GAT、DGCNN和LSTM,展示了与现有最先进方法相媲美的性能。
创新点:
-
通用剪枝方案:DepGraph是第一个能够应用于包括CNNs、RNNs、GNNs和Transformers在内的多种架构的通用剪枝方案,提高了结构剪枝在各种网络架构上的泛化能力。
-
性能提升:在CNN剪枝方面,该方法在CIFAR上的ResNet-56模型上实现了2.57倍的加速,同时保持了93.64%的准确率,优于未剪枝模型的93.53%准确率。在ImageNet-1k上,该算法在ResNet-50上实现了超过2倍的加速,仅损失了0.32%的性能。
-
跨架构适用性:该方法可以轻松转移到各种流行的网络,包括ResNe(X)t、DenseNet、VGG、MobileNet、GoogleNet和Vision Transformer,并在非图像神经网络(如LSTM用于文本分类、DGCNN用于3D点云、GAT用于图数据)上实现了8到16倍的加速,而没有显著的性能下降。
论文3
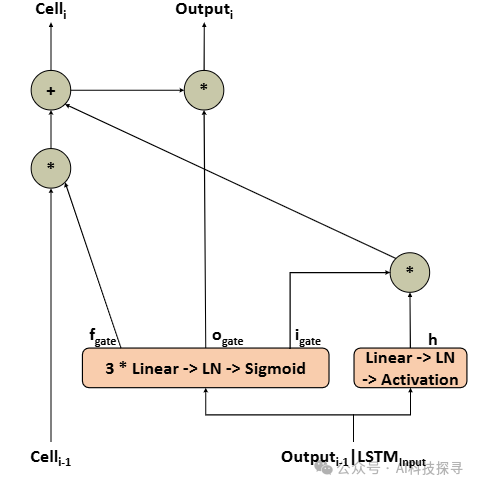
Rewiring the Transformer with Depth-Wise LSTMs
用深度LSTM重构Transformer
方法:
-
深度LSTM集成:提出了一种将深度LSTM与Transformer层和子层连接的方法,将堆叠Transformer层的输出视为时间序列中的步骤,并管理层内和层间的表示聚合。
-
Transformer层归一化和前馈计算吸收:展示了如何将Transformer层归一化和前馈子层计算吸收进深度LSTM中,同时通过深度LSTM连接纯Transformer注意力层,取代残差连接。
-
实验验证:通过6层Transformer在WMT 14英德/法任务和OPUS-100多语言NMT任务上的实验,展示了深度LSTM在BLEU分数上的显著提升。此外,深度Transformer实验也证明了深度LSTM在深度Transformer的收敛性和性能上的有效性。
创新点:
-
性能提升:6层Transformer使用深度LSTM在WMT任务和OPUS-100多语言NMT任务上带来了显著的BLEU分数提升。例如,在WMT 14英德任务中,Transformer Base的BLEU分数从27.55提升到28.53;在英法任务中,从39.54提升到40.10。
-
深度Transformer的收敛性:深度LSTM能够支持高达24层的深度Transformer的收敛,而12层使用深度LSTM的Transformer已经达到了24层普通Transformer的性能水平,表明深度LSTM在参数使用上比基线方法更高效。
论文4
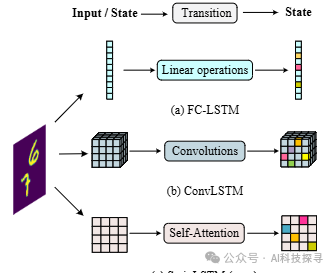
SwinLSTM: Improving Spatiotemporal Prediction Accuracy using Swin Transformer and LSTM
SwinLSTM:使用Swin Transformer和LSTM提高时空预测精度
方法:
-
SwinLSTM单元提出:提出了一种新的循环单元SwinLSTM,它整合了Swin Transformer块和简化的LSTM,扩展了ConvLSTM,用自注意力机制替换了卷积结构。
-
网络架构构建:构建了一个以SwinLSTM单元为核心的网络,用于时空预测任务。该网络首先将输入图像分割成图像块序列,然后通过补丁嵌入层,接着SwinLSTM层接收转换后的图像块或前一层的隐藏状态,以及前一时间步的单元和隐藏状态,以提取时空表示。最后,重建层解码时空表示以生成下一帧。
-
训练流程:介绍了SwinLSTM-B的训练流程,包括Warm-up阶段和预测阶段,通过连接这两个阶段的输出来计算损失。
创新点:
-
性能提升:SwinLSTM在Moving MNIST、Human3.6m、TaxiBJ和KTH数据集上的表现超过了现有的最先进方法。例如,在Moving MNIST数据集上,与ConvLSTM相比,SwinLSTM将MSE从103.3降低到17.7,SSIM从0.707提高到0.962。
-
全局空间依赖性学习:通过引入Swin Transformer块,SwinLSTM能够学习全局空间依赖性,这对于模型捕捉时空依赖性更为有利,从而提高了预测精度。
更多论文料可以关注:AI科技探寻,发送:111 领取更多[论文+开源码】

















 1738
1738

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









