







原文地址:https://towardsdatascience.com/text-embeddings-comprehensive-guide-afd97fce8fb5
2024 年 2 月 13 日
作为人类,我们可以阅读和理解文本(至少其中一些文本)。相反,计算机“用数字思考”,所以它们不能自动掌握单词和句子的意思。如果我们想让计算机理解自然语言,我们需要将这些信息转换成计算机可以处理的格式——数字向量。
许多年前,人们就学会了如何将文本转换为机器可理解的格式(最早的版本之一是ASCII)。这种方法有助于呈现和传输文本,但不编码单词的含义。当时,标准的搜索技术是搜索包含特定单词或N-gram的所有文档时使用的关键字搜索。
然后,几十年后,Embeddings出现了。我们可以计算单词、句子甚至图像的Embeddings。Embeddings也是数字向量,但它们可以捕捉到含义。因此,您可以使用它们进行语义搜索,甚至处理不同语言的文档。
在本文中,我想更深入地探讨Embedding主题并讨论所有细节:
- 在Embeddings之前是什么以及它们是如何进化的,
- 如何使用OpenAI工具计算Embeddings,
- 如何定义句子是否彼此接近,
- 如何可视化Embeddings,
- 最令人兴奋的部分是如何在实践中使用Embeddings。
让我们继续了解Embeddings的演变。
Embeddings的演变
我们将以简要介绍文本表示的历史开始我们的旅程。
词袋
将文本转换为矢量的最基本方法是一个单词包。让我们来看看理查德·费曼的一句名言:“We are lucky to live in an age in which we are still making discoveries。”我们将用它来说明一个词袋方法。
获得一袋单词向量的第一步是将文本分成单词(tokens),然后将单词约简为基本形式。例如,“running”将转换为“run”。这个过程称为词干提取。我们可以使用NLTK Python包。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 |
from nltk.stem import SnowballStemmer from nltk.tokenize import word_tokenize text = 'We are lucky to live in an age in which we are still making discoveries' # tokenization - splitting text into words words = word_tokenize(text) print(words) # ['We', 'are', 'lucky', 'to', 'live', 'in', 'an', 'age', 'in', 'which', # 'we', 'are', 'still', 'making', 'discoveries'] stemmer = SnowballStemmer(language = "english") stemmed_words = list(map(lambda x: stemmer.stem(x), words)) print(stemmed_words) # ['we', 'are', 'lucki', 'to', 'live', 'in', 'an', 'age', 'in', 'which', # 'we', 'are', 'still', 'make', 'discoveri'] |
现在,我们有了所有单词的基本形式的列表。下一步是计算它们的频率来创建一个向量。
1 2 3 4 5 |
import collections
bag_of_words = collections.Counter(stemmed_words)
print(bag_of_words)
# {'we': 2, 'are': 2, 'in': 2, 'lucki': 1, 'to': 1, 'live': 1,
# 'an': 1, 'age': 1, 'which': 1, 'still': 1, 'make': 1, 'discoveri': 1}
|
实际上,如果我们想把文本转换成向量,我们不仅要考虑文本中的单词,还要考虑整个词汇表。假设我们的词汇表中还有“i”、“you”和“study”,让我们根据费曼的话创建一个向量。

这种方法非常基础,它没有考虑到单词的语义含义,所以句子“the girl is studying data science”和“the young woman is learning AI and ML”不会彼此接近。
TF-IDF
单词包方法的一个稍微改进的版本是[**TF-IDF**](https://en.wikipedia.org/wiki/Tf - idf) (Term Frequency - Inverse Document Frequency)。它是两个度量的乘法。
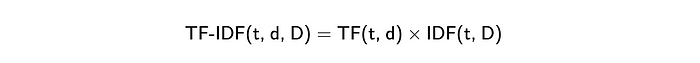
- Term Frequency(词频) 显示单词在文档中出现的频率。最常见的计算方法是将文档中术语的原始计数(如单词包中的术语)除以文档中术语(单词)的总数。然而,还有许多其他方法,如原始计数、布尔“频率”和不同的归一化方法。您可以在[Wikipedia](https://en.wikipedia.org/wiki/Tf -idf)上了解更多关于不同方法的信息。

- Inverse Document Frequency(逆文档频率) 表示单词提供的信息量。例如,单词“a”或“that”并不能提供关于文档主题的任何附加信息。相反,像“ChatGPT”或“生物信息学”这样的词可以帮助你定义领域(但不适用于这句话)。它被计算为文档总数与包含该单词的文档总数之比的对数。IDF越接近0——这个词越常见,它提供的信息就越少。

因此,最后,我们将得到一些向量,其中常见单词(如“I”或“you”)的权重较低,而在文档中多次出现的罕见单词的权重较高。这种策略会得到更好的结果,但它仍然不能捕获语义。
这种方法的另一个挑战是它产生的向量非常稀疏。向量的长度等于语料库的大小。英语中大约有470K个独特的单词(来源),所以我们将有巨大的向量。由于句子中不超过50个唯一的单词,因此向量中99.99%的值将为0,不编码任何信息。看到这里,科学家们开始考虑密集向量表示。
Word2Vec
最著名的密集表示方法之一是word2vec,由Google于2013年在Mikolov等人的论文effective Estimation of Word Representations in Vector Space中提出。
文中提到了两种不同的word2vec方法:连续词袋(当我们根据周围的词来预测单词时)和Skip-gram(相反的任务-当我们根据单词来预测上下文时)。
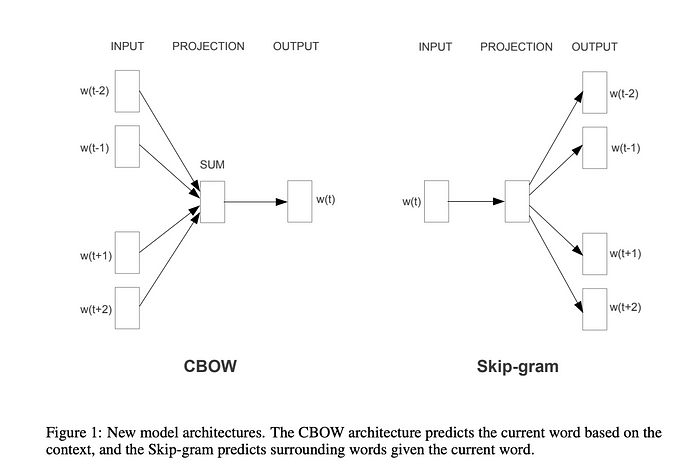
Figure from the paper by Mikolov et al. 2013 | source
密集向量表示的高级思想是训练两个模型:encoder和解码器。例如,在skip-gram的情况下,我们可能会将单词“christmas”*传递给encoder。然后,encoder将产生一个向量,我们将其传递给解码器,期望得到单词“merry”,“to”和“you”。

Scheme by author
这个模型开始考虑单词的意思,因为它是根据单词的上下文进行训练的。然而,它忽略了词法(我们可以从单词部分获得的信息,例如,“*-less”*表示缺少某物)。这个缺点后来通过查看GloVe中的子词跳过克来解决。
此外,word2vec只能处理单词,但我们想要编码整个句子。所以,让我们继续下一个与Transformers进化的步骤。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1414
1414











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









