






SELF-RAG 简介
SELF-RAG(Self-Reflective Retrieval-Augmented Generation)是一种检索增强生成(RAG)的框架,它通过自我反思学习检索、生成和批判,以提高大型语言模型(LLM)的质量和真实性。
SELF-RAG的工作流程主要包括以下几个步骤:
-
按需检索(Retrieval as Needed):首先,SELF-RAG使用特殊的LLM对问题进行首次结果生成,这个LLM在生成过程中会输出一些特殊的Token,称为Reflection Token。如果生成的结果表明需要检索,则进入检索阶段;如果不需要检索,则直接返回结果。
-
检索与生成(Retrieval and Generation):如果需要检索,SELF-RAG会检索出相关文档,并将每个文档与问题一起输入到LLM中,获取每个文档的生成结果。这一过程可能涉及到并发执行以提高效率。
-
评估与选择(Evaluation and Selection):对每个文档的生成结果进行评估,使用Reflection Token来计算每个文档的得分,并选择得分最高的结果作为最终输出。
SELF-RAG与普通RAG的主要区别在于:
- SELF-RAG可以根据生成的结果判断是否需要检索,而普通RAG每次查询都需要检索。
- SELF-RAG只用单个文档作为上下文生成结果,而普通RAG将所有检索到的文档作为上下文。
- SELF-RAG对生成结果有评估和挑选的过程,普通RAG则没有。
- SELF-RAG使用的是经过特殊训练的LLM,而普通RAG使用的是通用LLM 1。
SELF-RAG通过使用Reflection Token来实现更智能的检索和生成控制,提高了生成文本的准确性和质量。此外,SELF-RAG的训练过程包括训练一个评估模型来生成Reflection Token,然后使用这些Token更新训练语料库,最后训练最终的生成模型来预测输出内容和Reflection Token。
在实际应用中,SELF-RAG可以构建完整的应用,实现从模型测试到构建Self-RAG应用的流程,包括模型的微调方法和应用的优化思考。此外,SELF-RAG框架还包括了对生成内容的评估参数logprobs的使用,这是一个重要的参数,用于计算每个生成的token的概率对数,从而评估生成结果的质量。
总结
SELF-RAG的工作流程如下所述:首先,我们输入一个问题,系统会先进行判断,是否需要进行信息检索。在这个例子中,系统检索到了3个相关文本。接着,大模型会针对这3个文本,并行地生成3个不同的子回答。随后,大模型将进行进一步判断,生成3个评估结果:一是检索到的文本是否与问题相关,二是生成的答案是否基于检索文本(即是否凭空捏造),三是生成的答案是否有助于回答问题。根据这三个评估结果,我们对检索文本和子回答进行排序,将那些相关性强、内容真实且有助于回答问题的部分置于前列。例如,将相关性高且内容可靠的检索文档排在首位。接下来,我们将这些新的子回答和文档片段再次进行检索,如此循环往复,直至最终生成一个最佳回答。
LangGraph 简介
LangGraph是LangChain平台最近推出的一项关键功能,它代表了LangChain向多代理框架发展的重要步伐。那么,如何实现上文提到的类似代理的功能呢?我们不必手动编写繁琐的判断函数,因为LangGraph为我们提供了一个高效的解决方案。
LangGraph建立在LangChain之上,它使得开发者能够更加轻松地构建强大的代理系统。以下是关于LangGraph的官方资源:
LangGraph的核心是以图形化的方式运行,它包含三个主要元素:StateGraph、Node和Edge。
- StateGraph:这是图形的状态,它用于存储代理运行时的信息。在SELF-RAG中,StateGraph负责保存运行过程中产生的各种数据,如召回的文档、问题、子答案等,这些数据通常以字典的形式进行存储。
- Node:代表图形中的节点,它们是代理执行过程中的关键步骤。例如,召回文档和根据文档生成答案都是独立的节点。
- Edge:连接各个节点的边,它们代表了代理的工作流程方向。Edge通常负责执行文本分类的任务,例如决定是否进行检索。如果需要检索,流程就会转向检索节点;如果不需要,则直接由大模型生成答案。
通过这种方式,LangGraph为代理的构建和运行提供了一个清晰且易于管理的框架。
复现 SELF-RAG
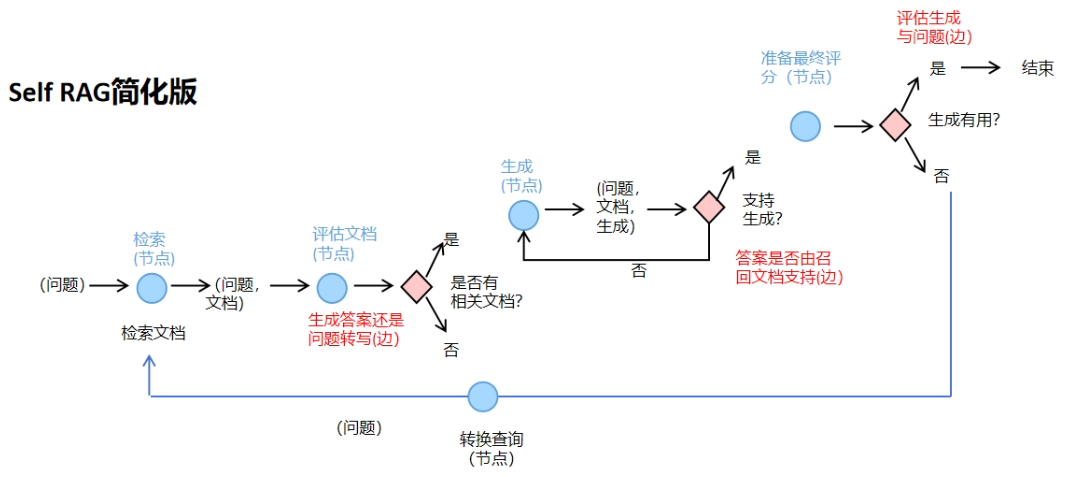
构建Agent工作流程图如下所示:
-
问题输入与文档检索:首先,用户输入一个问题,召回文档集,此检索过程是固定的。
-
文档相关性评估:接着,我们评估这些召回的文档是否与问题相关。将相关的文档保留,不相关的文档则被排除。这个过程实际上是对文档进行了一次筛选和排序。
f"""你是一个评分员,正在评估检索到的文档与用户问题的相关性, \n 以下是检索到的文档: \n {context} \n 这是用户的问题: {question} \n 如果文档包含与用户问题相关的关键词或语义意义,将其评分为相关. \n 只输出一个二分类的评分 'yes' 或者 'no' 用来表示文档是否与问题相关.""" -
文档存在性判断:然后,我们检查是否有相关文档。如果没有相关文档,系统将进行问题转写;如果有相关文档,则基于这些文档生成答案。
-
答案支持性判断:在这一步,我们需要判断生成的答案是否得到了召回文档的支持,即检查大模型是否忠实于文档内容,没有胡编乱造。如果答案得到支持,则继续下一步;如果答案不支持,则需要重新生成回答。
f"""你是一个评分员,在评估一个答案是否基于现有的事实依据. \n 以下是事实依据: \n ------- \n {documents} \n ------- \n 以下是回答: {generation} 只输出一个二分类的评分 'yes' 或者 'no' 用来表示答案是否基于事实的支持.""" -
最终评分准备:在这个节点,我们只进行图状态的变更,不需要调用大模型进行任何操作。
-
答案有用性判断:最后,我们评估生成的答案是否有助于解决问题。如果答案有用,代理任务结束;如果答案无用,则进行问题转写,并重新开始整个过程。
f"""你是一个评分助手用于判断回答是否解决了问题. \n 以下是回答: \n ------- \n {generation} \n ------- \n H以下是问题: {question} 给出一个二分类评分 'yes' 或者 'no' 提示答案是否对解决问题有用."""

















 2302
2302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









