







原文地址:Improving retrieval using Hypothetical Document Embeddings(HyDE)
2023 年 11 月 5 日
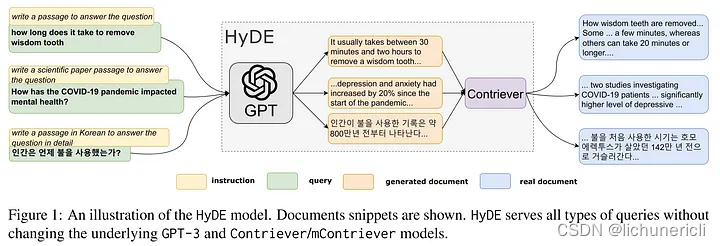
什么是HyDE?
HyDE 使用一个语言学习模型,比如 ChatGPT,在响应查询时创建一个理论文档,而不是使用查询及其计算出的向量直接在向量数据库中搜索。
它更进一步,通过对比方法学习无监督编码器。这个编码器将理论文档转换为一个嵌入向量,以便在向量数据库中找到相似的文档。
它不是寻求问题或查询的嵌入相似性,而是专注于答案到答案的嵌入相似性。
它的性能非常稳健,在各种任务(如网络搜索、问答和事实核查)中的表现与经过良好调整的检索器相匹配。
它的灵感来源于论文Precise Zero-Shot Dense Retrieval without Relevance Labels
为什么需要LLM生成假设性回答?
在面对缺乏具体性或缺乏易于识别的元素从给定上下文中推导答案的问题时,有时候会相当具有挑战性。
例如,考虑必胜客(Pizza Hut)连锁餐厅的情况,它通常以销售食物而闻名。然而,如果有人询问必胜客最好的菜品是什么,这个问题暗示了对食物的关注。这里的难点在于没有指定具体的食物项。因此,寻找洞察力变得有困难。为了解决这个问题,我们利用语言模型(LLM)的帮助来编写一个假设性的答案,然后将其转化为嵌入向量。这些嵌入向量然后在向量存储库中根据语义相似性进行检查,以帮助寻找相关信息。
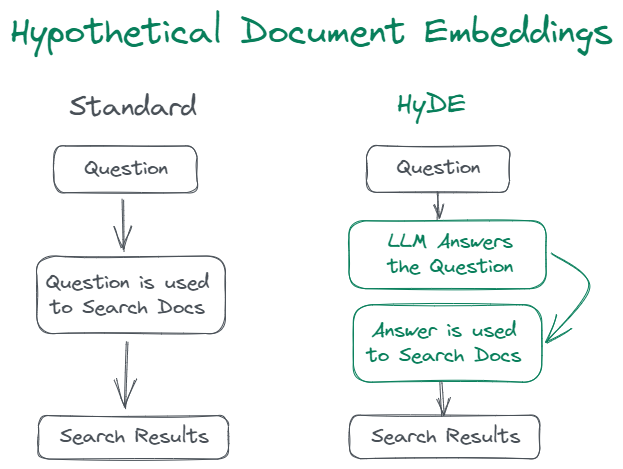
HyDE 利用 LLM(GPT3)的帮助创建一个“假设性”答案,然后搜索嵌入向量以找到匹配项。在这里,我们进行比较的是答案到答案的嵌入相似性搜索,而不是传统 RAG 检索方法中的查询到答案的嵌入相似性搜索。
然而,这种方法有一个缺点,即它可能无法始终如一地产生良好的结果。例如,如果讨论的主题对语言模型来说完全陌生,这种方法就无效了,可能会导致生成错误信息的次数增加。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1049
1049

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









