







新一代视觉生成范式「VAR: Visual Auto Regressive」视觉自回归来了!使 GPT 风格的自回归模型在图像生成首次超越扩散模型,并观察到与大语言模型相似的 Scaling Laws 缩放定律、Zero-shot Task Generalization 泛化能力:
论文标题: "Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction"
这项名为 VAR 的新工作由北京大学和字节跳动的研究者提出,登上了 GitHub 和 Paperwithcode 热度榜单,并得到大量同行关注:
目前体验网站、论文、代码、模型已放出:
-
体验网站:https://var.vision/
-
论文链接:https://arxiv.org/abs/2404.02905
-
开源代码:https://github.com/FoundationVision/VAR
-
开源模型:https://huggingface.co/FoundationVision/var
背景介绍
在自然语言处理中,以 GPT、LLaMa 系列等大语言模型为例的 Autoregressive 自回归模型已经取得了较大的成功,尤其 Scaling Law 缩放定律和 Zero-shot Task Generalizability 零样本任务泛化能力十分亮眼,初步展示出通往「通用人工智能 AGI」的潜力。
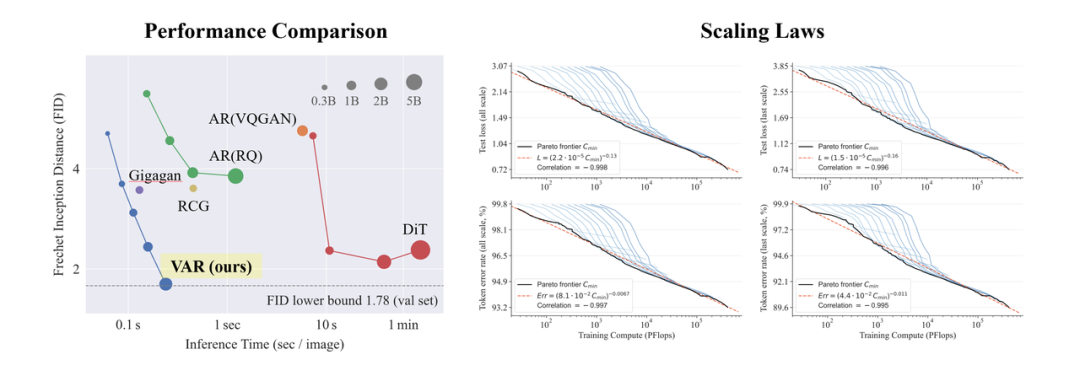
然而在图像生成领域中,自回归模型却广泛落后于扩散(Diffusion)模型:近期持续刷屏的 DALL-E3、Stable Diffusion3、SORA 等模型均属于 Diffusion 家族。此外,对于视觉生成领域是否存在「Scaling Law 缩放定律」仍未知,即测试集损失是否随模型或训练开销增长而呈现出可预测的幂律 (Power-law) 下降趋势仍待探索。
GPT 形式自回归模型的强大能力与 Scaling Law,在图像生成领域,似乎被「锁」住了:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 991
991

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









