







前言
最近看王者荣耀视频看到了一个别人提供的一个百里自动设计解决方案,使用一个外设放在百里的二技能上,然后拖动外设在屏幕上滑动,当外设检测到有敌方英雄时外设自动松开百里二技能达到自动射击的效果,
我的思路一下就打开了,之前什么指哪打哪,计算电脑上二技能圆坐标和敌方英雄椭圆射击坐标函数映射,都是屁话,直接让二技能射击线进行像雷达一样的扫描就可以了,当检测到敌方英雄时自动松开二技能,这样百里不就可以超神了吗?而且延时更低,射击更快
那么难点在哪里呢?
还是敌方英雄血条的识别上,当然,这个不是问题
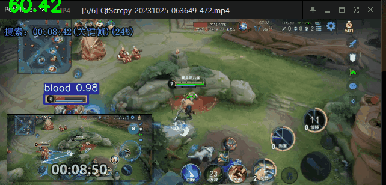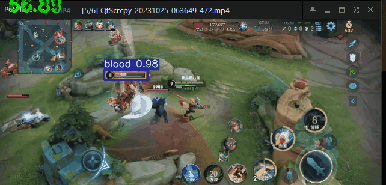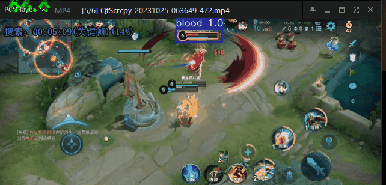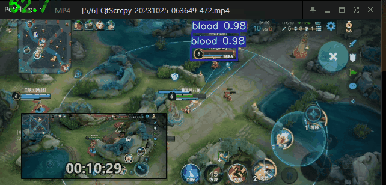
效果如下
可以达到每秒60帧的识别效果,这个识别速度已经嘎嘎快了
我在桌面上打开了我打王者荣耀时录下的视频,然后对视频中的英雄进行实时识别
实现
fastrcnn不是很新鲜的高深技术,事实上他有模板可用
github上有项目路径
https://github.com/sovit-123/fasterrcnn-pytorch-training-pipeline#Tutorials
我所做的也仅仅是自己使用labelimg标注了1000张图片(过程真是痛苦,一个个拉框,中途吃了三个苹果看了会儿剧才断断续续坚持拉满了1000张),然后用fasterrcnn_mobilenetv3_large_fpn模型,迭代了50次进行了训练
我只是略微修改了下,参照烟雾识别模型,使其符合我自己的图片识别,其中我修改了如下文件,以做参考
对了,这是我所使用模型的生成的权重文件和使用的工程
https://download.csdn.net/download/lidashent/88476823
训练原始图像大小为640x288
如果要测试这个权重,运行inference1.py这个文件,然后使用QtScrcpy连接手机打开游戏,格式大小调节为640,在电脑上可以看到游戏画面和实时识别画面
训练数据获得
使用QtScrcpy连接手机,然后打开这个软件的自动录像功能,然后打了一局游戏,然后将得到的视频中敌人出现的视频片段使用pr进行裁剪得到一个新视频,然后使用python获得每一帧,然后使用labelIMG进行手动画框标注
我标注到1000张就开始训练了,从结果看效果识别很不错,
我其实想使用一种更加省力的方法,就是打开王者荣耀的单机模式,然后使用电脑调试,从内存中获得每位敌方英雄的坐标,对每帧敌方英雄动态标注,这样就不用手动拉框了,而且生成的坐标也更加精准,同时也可以做敌方英雄位置动态预测,但是我偷懒了,想赶紧获得训练数据看看效果,所以这个没做,如果有哪位实现了,分享我下,我去偷师
训练数据和测试数据yaml文件
就是修改了下血条数据存放路径和标签而已
TRAIN_DIR_IMAGES: ./data/blood_pascal_voc/archive/train/images
TRAIN_DIR_LABELS: ./data/blood_pascal_voc/archive/train/annotations
VALID_DIR_IMAGES: ./data/blood_pascal_voc/archive/valid/images
VALID_DIR_LABELS: ./data/blood_pascal_voc/archive/valid/annotations
# Optional test data path. If given, test paths (data) will be used in
# `eval.py`.
# TEST_DIR_IMAGES:
# TEST_DIR_LABELS:
# Class names.
CLASSES: [
'__background__',
'blood'
]
# Number of classes (object classes + 1 for background class in Faster RCNN).
NC: 2
# Whether to save the predictions of the validation set while training.
SAVE_VALID_PREDICTION_IMAGES: True
训练py
不习惯使用参数化方式训练数据,于是我修改了下train文件直接预设参数进行训练,直接执行train文件
至于模型的微调,你自己看着办吧,我不能保证我微调的模型一定更加合理,你可以直接使用预设的模型
def parse_opt():
# Construct the argument parser.
parser = argparse.ArgumentParser()
parser.add_argument(
'-m', '--model',
default='fasterrcnn_resnet50_fpn',
help='name of the model'
)
parser.add_argument(
'--data',
default=r"data_configs/bloodLine.yaml",
help='path to the data config file'
)
parser.add_argument(
'-d', '--device',
default='cuda',
help='computation/training device, default is GPU if GPU present'
)
parser.add_argument(
'-e', '--epochs',
default=50,
type=int,
help='number of epochs to train for'
)
parser.add_argument(
'-j', '--workers',
default=4,
type=int,
help='number of workers for data processing/transforms/augmentations'
)
parser.add_argument(
'-b', '--batch',
default=16,
type=int,
help='batch size to load the data'
)
parser.add_argument(
'--lr',
default=0.001,
help='learning rate for the optimizer',
type=float
)
parser.add_argument(
'-ims', '--imgsz',
default=640,
type=int,
help='image size to feed to the network'
)
parser.add_argument(
'-n', '--name',
default="blood_training4-fasterrcnn_resnet50_fpn",
type=str,
help='training result dir name in outputs/training/, (default res_#)'
)
parser.add_argument(
'-vt', '--vis-transformed',
dest='vis_transformed',
action='store_true',
help='visualize transformed images fed to the network'
)
parser.add_argument(
'--mosaic',
default=0.0,
type=float,
help='probability of applying mosaic, (default, always apply)'
)
parser.add_argument(
'-uta', '--use-train-aug',
dest='use_train_aug',
action='store_true',
help='whether to use train augmentation, blur, gray, \
brightness contrast, color jitter, random gamma \
all at once'
)
parser.add_argument(
'-ca', '--cosine-annealing',
dest='cosine_annealing',
action='store_true',
help='use cosine annealing warm restarts'
)
parser.add_argument(
'-w', '--weights',
default=None,
# default=r"outputs/training/blood_training-fasterrcnn_mobilenetv3_large_fpn/best_model.pth",
type=str,
help='path to model weights if using pretrained weights'
)
parser.add_argument(
'-r', '--resume-training',
dest='resume_training',
action='store_true',
help='whether to resume training, if true, \
loads previous training plots and epochs \
and also loads the otpimizer state dictionary'
)
parser.add_argument(
'-st', '--square-training',
dest='square_training',
action='store_true',
help='Resize images to square shape instead of aspect ratio resizing \
for single image training. For mosaic training, this resizes \
single images to square shape first then puts them on a \
square canvas.'
)
parser.add_argument(
'--world-size',
default=1,
type=int,
help='number of distributed processes'
)
parser.add_argument(
'--dist-url',
default='env://',
type=str,
help='url used to set up the distributed training'
)
parser.add_argument(
'-dw', '--disable-wandb',
dest="disable_wandb",
action='store_true',
default='3',
help='whether to use the wandb'
)
parser.add_argument(
'--sync-bn',
dest='sync_bn',
help='use sync batch norm',
action='store_true'
)
parser.add_argument(
'--amp',
action='store_true',
help='use automatic mixed precision'
)
parser.add_argument(
'--seed',
default=0,
type=int ,
help='golabl seed for training'
)
parser.add_argument(
'--project-dir',
dest='project_dir',
default=None,
help='save resutls to custom dir instead of `outputs` directory, \
--project-dir will be named if not already present',
type=str
)
args = vars(parser.parse_args())
return args
画框文件的修改py
因为训练数据少,模型有时只能识别血条,无法区分敌我,因此需要对血条颜色进行区分
所以对于模型最后给出的分类结果,我加了如下限制,在annotations.py文件里我添加了一个画框约束代码
就是检测画框内红色点数,经过实践发现,红色点数低于60就可以判定为非敌方英雄
可根据需要对此行代码进行修改
for j, box in enumerate(draw_boxes):
def judgePoint(p1,p2,img):
# 制定矩形范围
(x1, y1), (x2, y2) =p1,p2
roi = img[y1+2:y2, x1+15:x2]
# 将图像转换为HSV色彩空间
hsv = cv2.cvtColor(roi, cv2.COLOR_BGR2HSV)
# 设定红色范围
lower_red = (0, 50, 50)
upper_red = (10, 255, 255)
mask1 = cv2.inRange(hsv, lower_red, upper_red)
lower_red = (170, 50, 50)
upper_red = (180, 255, 255)
mask2 = cv2.inRange(hsv, lower_red, upper_red)
# 合并两个掩码
mask = mask1 + mask2
# cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 计算红色像素数量
red_pixels = cv2.countNonZero(mask)
return red_pixels
# Draw the bounding boxes and write the class name on top of it.
for j, box in enumerate(draw_boxes):
p1 = (int(box[0]/image.shape[1]*width), int(box[1]/image.shape[0]*height))
p2 = (int(box[2]/image.shape[1]*width), int(box[3]/image.shape[0]*height))
class_name = pred_classes[j]
redCounts=judgePoint(p1,p2,orig_image)
# print(redCounts)
if redCounts>80:
if args['track']:
color = colors[classes.index(' '.join(class_name.split(' ')[1:]))]
else:
color = colors[classes.index(class_name)]
cv2.rectangle(
orig_image,
p1, p2,
color=color,
thickness=lw,
lineType=cv2.LINE_AA
)
if not args['no_labels']:
# For filled rectangle.
final_label = class_name + ' ' + str(round(scores[j], 2))
w, h = cv2.getTextSize(
final_label,
cv2.FONT_HERSHEY_SIMPLEX,
fontScale=lw / 3,
thickness=tf
)[0] # text width, height
w = int(w - (0.20 * w))
outside = p1[1] - h >= 3
p2 = p1[0] + w, p1[1] - h - 3 if outside else p1[1] + h + 3
cv2.rectangle(
orig_image,
p1,
p2,
color=color,
thickness=-1,
lineType=cv2.LINE_AA
)
cv2.putText(
orig_image,
final_label,
(p1[0], p1[1] - 5 if outside else p1[1] + h + 2),
cv2.FONT_HERSHEY_SIMPLEX,
fontScale=lw / 3.8,
color=(255, 255, 255),
thickness=tf,
lineType=cv2.LINE_AA
)
测试py
我修改其为获得桌面指定区域的动态图像,然后对桌面图像的每一帧进行识别
修改其inference.py文件,然后修改其图片获取方式为桌面图像
x, y = 0, 0
width, height = 641, 321
while(1):
image_name='aa'
screenshot = pyautogui.screenshot(region=(x, y, width, height))
# 显示截图
# 将截图转换为NumPy数组
screenshot = np.array(screenshot)
orig_image = cv2.cvtColor(screenshot, cv2.COLOR_RGB2BGR)
#对每一帧桌面图像进行识别
...
对于识别显示,如果发现卡顿,是因为设置的是检测到才显示图像
实际上可以调整为检测到血条显示标识框,不检测到正常显示,可以对推理py显示部分修改为:
将显示部分移出检测判断范围,使其和画框部分代码并列:
if len(outputs[0]['boxes']) != 0:
draw_boxes, pred_classes, scores = convert_detections(
outputs, detection_threshold, CLASSES, args
)
orig_image = inference_annotations(
draw_boxes,
pred_classes,
scores,
CLASSES,
COLORS,
orig_image,
image_resized,
args
)
if args['show']:
cv2.imshow('Prediction', orig_image)
cv2.waitKey(0)
if args['mpl_show']:
plt.imshow(orig_image[:, :, ::-1])
plt.axis('off')
plt.show()
升级
其实有更加简单的方案,就是不用fastrcnn识别血条,而是直接识别百里的二技能射击线在敌方英雄上的情况,这样,每当百里二技能射击线在敌方英雄身上,就会自动松开百里二技能,就能直接射击了

















 1568
1568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









