








一、大模型的分类:从“万金油”到“特种兵”
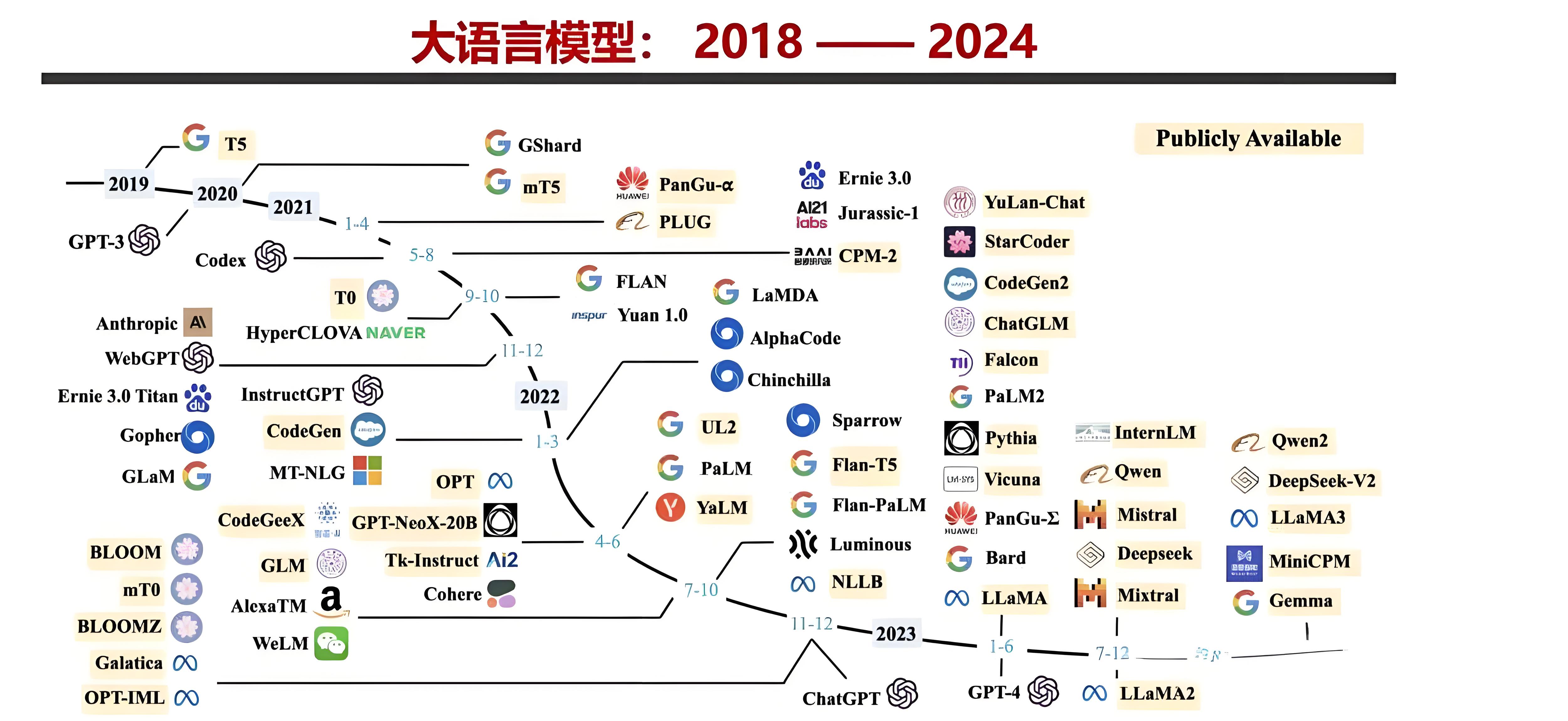
1.1 应用领域:你的AI是“通才”还是“专才”?
大模型的第一层分类逻辑,取决于它在真实世界中的“职业定位”。
- 通用型大模型:像瑞士军刀一样全能,能写代码、写小说、甚至写论文。例如阿里云的通义千问(Qwen)和百度的文心一言,这类模型追求“一招鲜吃遍天”,但代价是需要海量参数和算力支撑。
- 垂直型大模型:专精某一领域,例如华为盘古大模型的医疗子模型,能精准分析CT影像;腾讯的“混元”在游戏场景中优化NPC行为。这类模型通过定向优化,用更少资源实现更高效率。
- 多模态大模型:打破单一感官限制,例如商汤的“日日新”支持图文音视频的跨模态理解,未来可能成为元宇宙的“全能管家”。
1.2 架构设计:从“全连接”到“聪明的懒人”
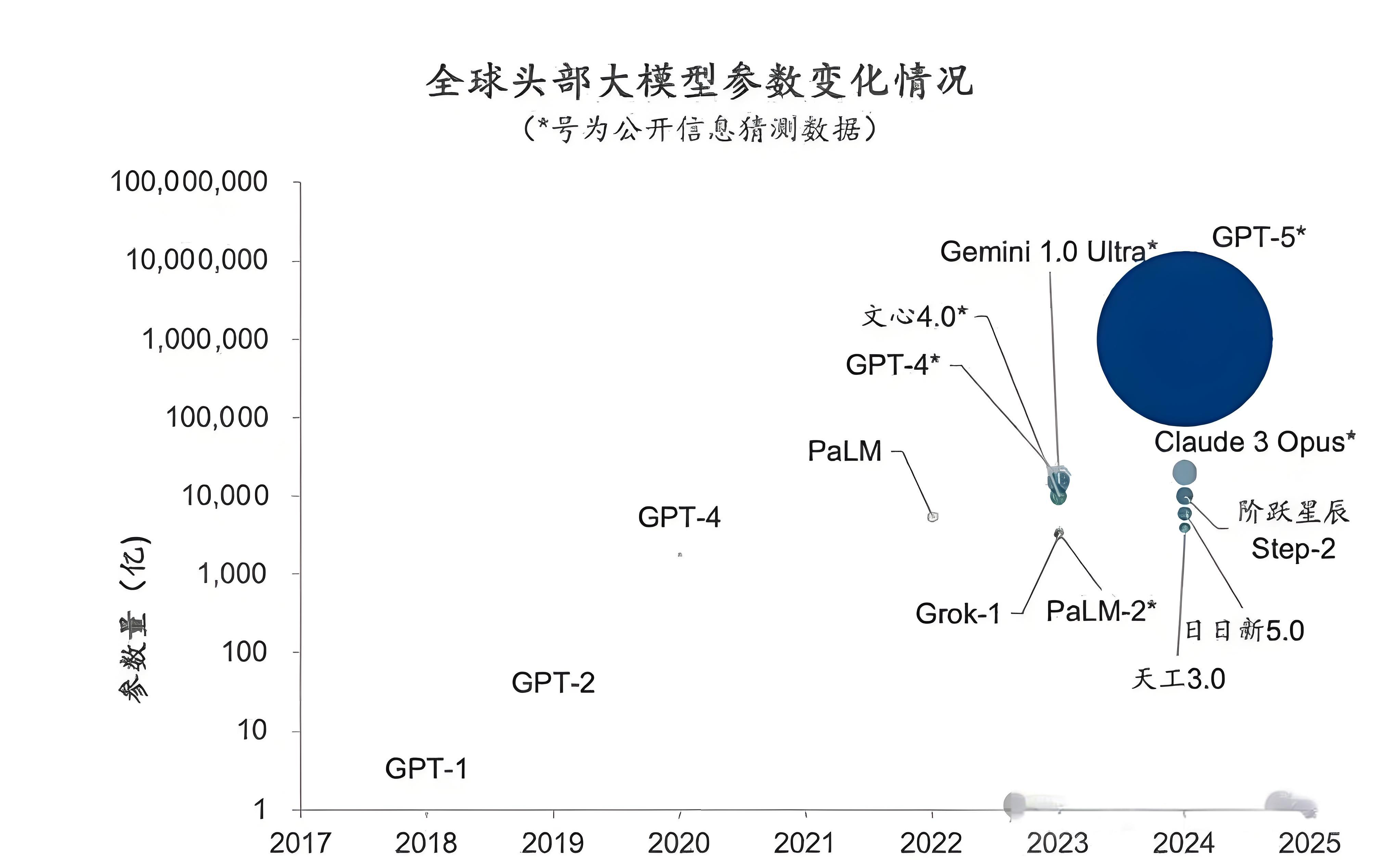
模型的“身体结构”决定了它的智力天花板与能耗。
- 密集模型(Dense Models):像传统健身房的“增肌狂魔”,通过全连接网络堆砌参数(如GPT-3的1750亿参数),计算资源消耗惊人。
- 稀疏模型(Sparse Models):聪明的“选择性用脑”,例如阿里云的M6和DeepSeek的MoE架构,只激活部分参数,像人类大脑的神经元选择性放电,能效比提升30%以上。
- 混合架构:例如科大讯飞的“星火”大模型,结合密集与稀疏设计,实现“关键时刻火力全开,日常低功耗待机”。
1.3 训练范式:从“填鸭式学习”到“举一反三”
训练方式决定了模型的“学习能力”与“成长速度”。
- 预训练+微调(Fine-tuning):像传统教育,先背课本(预训练),再考专科(微调),如BERT的训练模式。但缺点是成本高,且新任务需重复“填鸭”。
- 提示学习(Prompt-based Learning):让模型“举一反三”,例如通义千问通过自然语言指令(如“请扮演一位律师”)动态切换角色,无需重训。
- 强化学习(RLHF):像家长监督,通过人类反馈优化输出,例如DeepSeek的长思维链推理能力,就是通过人类标注数据不断纠偏而来。
1.4 功能定位:生成、理解、推理——AI的“三头六臂”
- 生成型模型:主打“创意输出”,如OpenAI的DALL·E生成图像,但国产模型如通义万相也在追赶,能根据文字生成国画风格的山水。
- 理解型模型:侧重“读心术”,例如Bert在语义分析上的优势,被用于电商评论的情感分析。
- 推理型模型:像人类的“逻辑链”,例如DeepSeek通过多步推理解决复杂问题,华为盘古在数学解题中的表现已接近人类水平。
二、核心技术指标:大模型的“体检报告”
2.1 模型规模:参数量是肌肉,架构是骨骼
- 参数量(Parameters):参数越多,模型越“聪明”,但也越“吃资源”。例如GPT-4的参数量达1.8万亿,相当于人类大脑神经元的1/100,但训练成本高达数亿美元。
- 架构细节:层数、注意力头数、隐层维度共同决定“计算密度”。例如,通义千问的710B模型采用24层架构,每层32个注意力头,像精密的齿轮般协同工作。
2.2 训练资源:算力是粮食,数据是养料
- 数据量:训练数据的规模和质量直接决定模型“见识”。例如,GPT-3的13万亿token数据相当于10万本《红楼梦》的文本量,而阿里云的通义实验室通过爬取互联网数据,构建了涵盖多语言、多领域的“营养库”。
- 算力消耗:训练一次大模型,可能需要数千块GPU运行数月。例如,GPT-3的训练消耗约3.14e23次浮点运算(FLOPs),相当于让全球人口每人每秒计算100次,持续10年!
2.3 性能指标:跑分决定“战斗力”
- 通用指标:困惑度(Perplexity)越低,模型预测能力越强;MMLU(多任务语言理解)准确率则反映“跨界能力”。例如,DeepSeek的MMLU得分达85%,接近人类平均水平。
- 推理效率:延迟(Latency)和吞吐量(Throughput)是落地关键。例如,华为盘古在推理时,单次响应仅需200毫秒,支撑了其在工业场景的应用。
2.4 能耗与部署:绿能AI,未来必争之地
- 能效比:单位能耗下的性能输出,直接影响商业成本。例如,采用稀疏模型的DeepSeek,能效比比密集模型提升50%。
- 模型压缩技术:量化(Quantization)、剪枝(Pruning)等技术,让大模型“瘦身”。例如,通义千问的7B版本通过量化到INT8,显存占用从几十GB降至10GB,轻松部署到手机端。
2.5 其他关键指标:安全、公平与透明
- 鲁棒性:对抗攻击下是否“脸不红心不跳”?例如,腾讯的混元模型通过对抗训练,对恶意输入的识别率提升30%。
- 公平性:避免输出性别、种族偏见。例如,阿里云在训练时引入“公平损失函数”,减少医疗建议中的性别歧视。
- 可解释性:像医生需要“病历记录”,模型决策过程需可视化。例如,DeepSeek通过注意力热力图,让用户直观看到推理逻辑。
三、中国大模型的“实战案例”:接地气的技术突围
3.1 通义千问:从“通义”到“通晓”
阿里云的通义千问(Qwen)主打“全场景覆盖”,参数量达710B,支持多语言和代码生成。其特色在于“本土化适配”:
- 在电商场景,可理解“双十一”促销话术;
- 在政务领域,能撰写符合中国政策的公文;
- 在医疗场景,与三甲医院合作,辅助诊断报告生成。
3.2 华为盘古:工业界的“最强大脑”
华为盘古大模型专攻行业落地,例如:
- 矿山安全:通过图像识别监测设备故障,准确率超99%;
- 天气预测:结合气象数据,提升台风路径预报精度;
- 代码写作:支持Java、Python等10+语言,开发效率提升30%。
3.3 百度文心一言:从搜索到创作的“跨界者”
文心一言3.5版本在文生图、视频生成上发力,例如:
- 为用户提供“一键生成小说封面”的服务;
- 在百度搜索中,能直接生成结构化的知识图谱,取代传统文字列表。
四、未来战场:大模型的“进化论”
4.1 效率革命:从“暴力美学”到“聪明计算”
稀疏模型(如MoE)和混合专家架构(Mixture of Experts)将主导未来,例如:
- MoE 2.0:动态分配计算资源,像“按需用电”,降低90%的训练成本;
- 神经辐射场(NeRF):让多模态模型更高效处理3D场景,用于虚拟现实。
4.2 数据合成:AI自己当“老师”
通过模型自生成数据(Self-Training),例如:
- DeepSeek的“长思维链策略”让模型自己写问题并解答,持续迭代;
- 华为盘古在医疗领域,通过合成CT图像数据,解决隐私与数据不足的矛盾。
4.3 多模态融合:万物互联的“通感”时代
未来大模型将打破模态壁垒,例如:
- 视频理解+生成:输入一段舞蹈动作,生成对应的解说文字和配乐;
- 跨语言多模态:用中文指令生成英文视频,再翻译成阿拉伯语图像。
4.4 伦理与安全:AI的“紧箍咒”
- 可控生成:通过强化学习,确保输出符合中国法律法规;
- 数据隐私:联邦学习技术让模型训练“不碰用户数据”,如腾讯的医疗模型在医院本地化部署。
总结:中国大模型的“弯道超车”密码
大模型的分类与技术指标,本质是“资源与能力的博弈”。中国厂商在算力、数据、场景的积累下,正通过垂直化、稀疏化、本土化三大路径突围。未来,当模型能像水和电一样“即插即用”,这场智能革命的终极战场,将是“如何让AI真正懂中国人的需求”。


















 75
75

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











