







 Image Caption任务结合了计算机视觉和自然语言处理,目标是让AI理解图像并自动生成描述。它涉及图像信息与语言信息的融合,常用深度学习模型如CNN和RNN。该任务面临数据集大小、精度、结构变体、视觉与语言关联等挑战。经典算法如Clipcap利用Transformer和ViT进行跨模态交互,提升图像与语言关联性。评估指标包括BLEU、ROUGE、METEOR、CIDEr和SPICE。常用数据集有COCO、Flickr30K等。
Image Caption任务结合了计算机视觉和自然语言处理,目标是让AI理解图像并自动生成描述。它涉及图像信息与语言信息的融合,常用深度学习模型如CNN和RNN。该任务面临数据集大小、精度、结构变体、视觉与语言关联等挑战。经典算法如Clipcap利用Transformer和ViT进行跨模态交互,提升图像与语言关联性。评估指标包括BLEU、ROUGE、METEOR、CIDEr和SPICE。常用数据集有COCO、Flickr30K等。
【Image captioning】AI算法说——图像描述(Image captioning)
作者:安静到无声 个人主页
作者简介:人工智能和硬件设计博士生、CSDN与阿里云开发者博客专家,多项比赛获奖者,发表SCI论文多篇。
Thanks♪(・ω・)ノ 如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦! o( ̄▽ ̄)d
欢迎大家来到安静到无声的《手把手实现Image captioning》,如果对所写内容感兴趣请看手把手实现Image captioning讲解 - 总目录,同时这也可以作为大家学习的参考。欢迎订阅,请多多支持!
遥感图像字幕
自然图像字幕
| 题目 | 期刊 | 下载 | 代码 | 备注 |
|---|---|---|---|---|
| 9. Self-Distillation for Few-Shot Image Captioning | WACV2022 | 链接 | 有 | SFID-few_shot |
| 8. ClipCap: CLIP Prefix for Image Captioning | arXiv2022 | PDF下载 | 有 | ClipCap |
| 7. Efficient Image Captioning for Edge Devices | AAAI2023 | PDF下载 | 无 | LightCap |
| 6. Semantic-Conditional Diffusion Networks for Image Captioning | CVPR2023 | PDF下载 | 有 | SCDNet |
| 5. Towards local visual modeling for image captioning | PR2023 | 链接 | 有 | LSTNet |
| 4. RSTNet: Relationship-Sensitive Transformer Network | CVPR2021 | PDF下载 | 有 | RSTNet |
| 3. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention | arXiv2015 | PDF下载 | 有 | Hard-Att |
| 2. Comprehending and Ordering Semantics for Image Captioning | CVPR2022 | PDF下载 | 有 | COS-Net |
| 1. In Defense of Grid Features for Visual Question Answering | CVPR2020 | PDF下载 | 无 | Grid Features |
目录标题
转载自AI产品汇,如有侵权,联系删除。
1. 任务简介
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-htWw0tN0-1686465523891)(/imgs/2023-06-11/yJKJJEhoBOs65EJj.png)]](https://i-blog.csdnimg.cn/blog_migrate/bb6656bc44a7f753499565b650e51657.png)
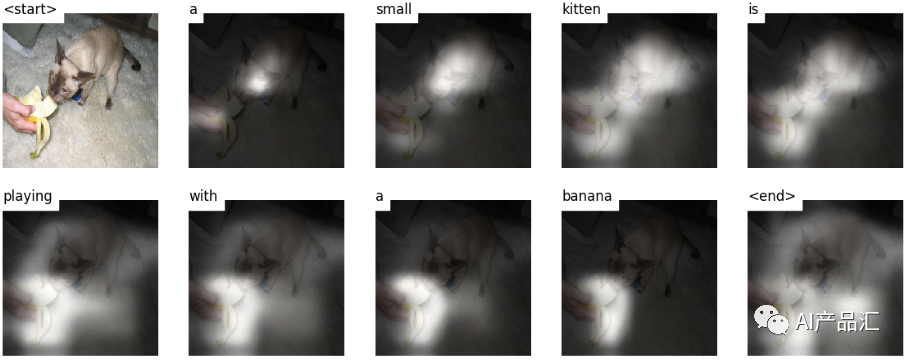
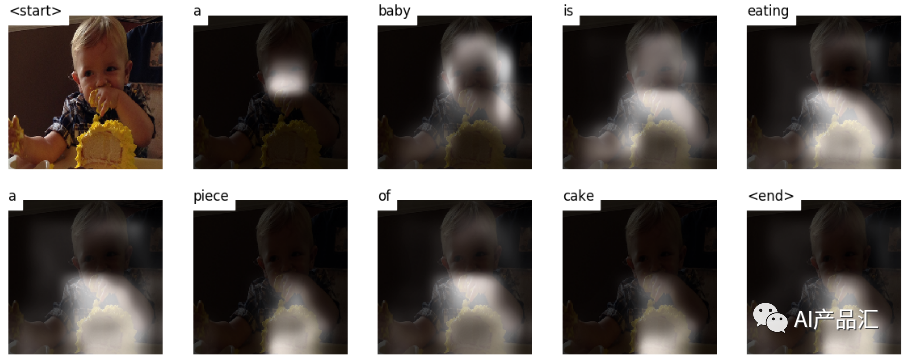
Image Caption任务是一个计算机视觉和自然语言处理的交叉任务,其目标是让计算机理解视觉图像并自动为其生成一段文字描述。Image Caption任务的输入是一张图像,输出是一段文字,描述该图像的内容和场景。Image Caption任务被广泛应用于图像理解、智能搜索引擎、自动翻译等领域。
Image Caption任务的核心就是如何将视觉信息与语言信息相结合,使计算机能够自动理解图像并描述其内容。实现这个任务的方法通常是将深度学习算法应用于图像和文本处理,例如使用卷积神经网络(CNN)和循环神经网络(RNN)等。
2. 任务挑战
-
任务复杂:生成自然语言描述需要结合考虑图片的信息,而图片则可能涉及到更加复杂的情境,包括图像中每个像素的颜色、位置、大小以及物体之间的关系等。因此,Image Caption算法需要在复杂的多元数据中寻找关联性和必要细节。
-
结构变体:即便是同一类目的图片,其内容也可能非常不同。比如拍摄地点、拍摄时间、光线、角度等的差别都会让一张具有相似场景的图片变得截然不同。这种结构变体的存在,使得生成准确的描述变得更加困难。
-
视觉与语言之间的关联:由于文本和视觉表示有很大的不同,机器学习算法需要通过学习到的特征来获取两种不同表示之间的联系。因此,图像和文本语言之间的联系不可能只是简单的像素到单词的一一映射,而是一个复杂的和很多层次的关联。
-
数据集大小和精度:为了训练和评估Image Caption算法,需要大量的图片和相应的描述数据。然而,这些数据集往往存在噪声、错误或者缺失信息。而这些问题会影响深度学习模型的训练和泛化能力。
-
实时性:Image Caption任务需要处理大量的视觉和语言信息,因此需要消耗大量的计算资源。因此,对于实时性任务来说,算法的性能和效率是非常重要的挑战。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TKQjfyzN-1686465549187)(/imgs/2023-06-11/a6syZtmCdEbcEJMf.png)]](https://i-blog.csdnimg.cn/blog_migrate/3205927e42c8141a1e02244a2cc1a157.png)
3. 任务框图
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-emeCSPge-1686465523892)(/imgs/2023-06-11/FGZSQayyXgnT8w8o.png)]](https://i-blog.csdnimg.cn/blog_migrate/47152cfa66bcb25b0953971cab6f9551.png)
如上图所示,经典的Image Caption算法主要包含两部分,即一个用于提取图片信息的Visual Model模型和一个用户提取文本信息的Language Model模型。Visual Model模型可以由CNN、Transformer、GCN等组成;Language Model模型可以由LSTM、CNN+RNN、Beat、Transformer等组成。该任务的难点是如何有效的将图像特征表示与文本特征表示对齐,常用的优化策略包括:注意力机制、GCN等。模型训练阶段,输入是一张图片和这张图片对应的文本信息,输出是预训练好的模型文件。模型推理阶段,输入是一张待测试的图片,输出是这张图片的文本描述信息。
4. 任务类别
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PP7sapkk-1686465523893)(/imgs/2023-06-11/qXxFF1bzSr3JN3fK.png)]](https://i-blog.csdnimg.cn/blog_migrate/9c5bdc62e879462a8766d02c7af5e1db.png)
-
Attension-based方法-该类方法受到人类注意力模式和人眼聚焦图像的方式的启发而形成的。该类方法在经典的CNN+LSTM的基础上增加了Attension模块,该模块使得模型能够更加关注图像中的重点目标。代表性的算法包括:Neural machine translation by jointly learning to align and translate和Long short-term memory。
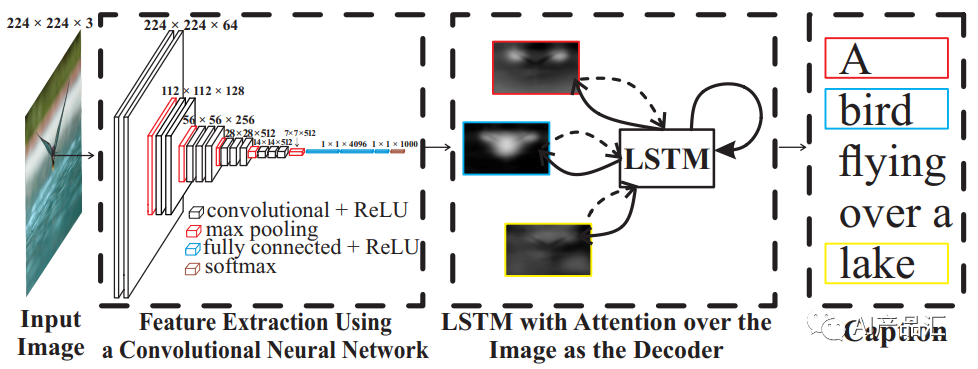
-
Attension-based+Spatial & Semantic Relations方法-基于注意力机制的方法并不能很好的关联图像特征和文本特征。有学者提出一种旨在利用图像中的空间和语义关系来更恰当地描述内容的关联方法,代表性的算法包括:Image captioning: Transforming objects into words。
-
Graph-based方法-由于图结构可以很好地将图片信息与文本信息关联起来,因而学者们尝试着将该思路引入到Image Caption任务中。代表性的算法包括:Auto-encoding scene graphs for image captioning和Unpaired image captioning via scene graph alignments等。
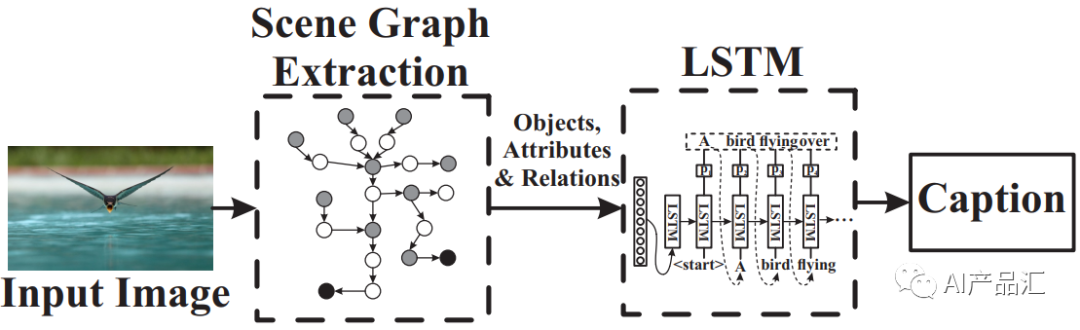
-
Graph-based+Attension方法-图结构可以很好的处理图像与文本之间的关联问题,而Attension模块则可以更好的将图像与文本之间的关键信息对齐起来,因而学者们尝试着将两种思路进行融合。代表性的算法包括:Exploring visual relationship for image captioning和Comprehensive image captioning via scene graph decomposition等。
-
Convolutional-based方法-经典的Image Caption都是CNN+LSTM的基础架构。随着SeqToSeq模型的出现,使得全卷积的Image Caption方法称为了可能!代表性的算法包括:Convolutional image captioning和Convolutional decoders for image captioning等。
-
Transformer-based方法-随着Transformer技术的发展,学者们发现Transformer自带注意力机制,而且很适合处理文本任务,因而出现了很多基于Transformer的Image Caption算法。代表性的算法包括:Image captioning: Transforming objects into words和Attention on attention for image captioning等。
-
Transformer-based+Graphs方法-为了更好的学习图像块之间的空间关系,学者们在Transformer架构中引入了Graphs。代表性的算法包括:Image captioning through image transformer和Captioning transformer with scene graph guiding等。
-
VLP方法-为了减少模型对监督学习的数据依赖,通过自我监督学习在具有大量数据的数据集上预训练大规模模型。然后将预训练模型推广到各种下游任务。代表性的算法包括:Clipcap: Clip prefix for image captioning等。
-
Unsupervised & Reinforcement Learning方法-由于前面的这些方法都需要提供一张图片和这张图片对应的描述文本来训练模型,为了降低图片和文本之间的强依赖关系,学者们引入了无监督学习和强化学习的思路来解决Image Caption问题。代表性的算法包括:Unsupervised image captioning和Improving image captioning with conditional generative adversarial nets等。
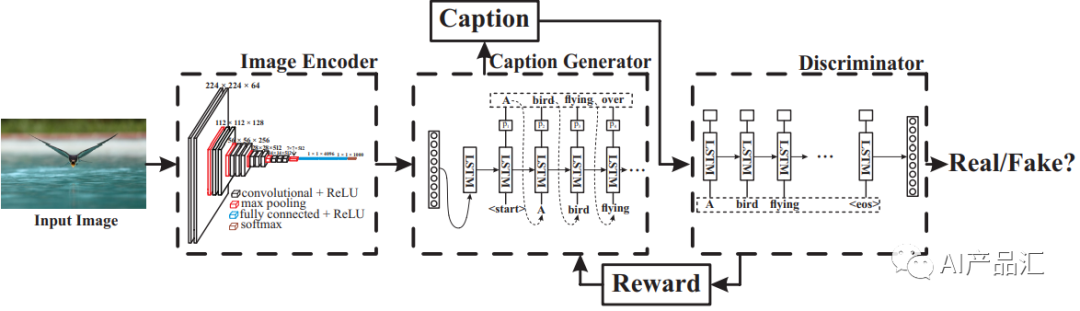
-
Generating Multi-Style Captions方法-为了使得模型能够输出更多样、带有不同风格的文本信息,学者们提出了该方法。该方法需要在标注时标注多个不同风格的文本标签,代表性的算法包括:Mscap: Multi-style image captioning with unpaired stylized text和Engaging image captioning via personality等。
5. 经典算法剖析-Clipcap
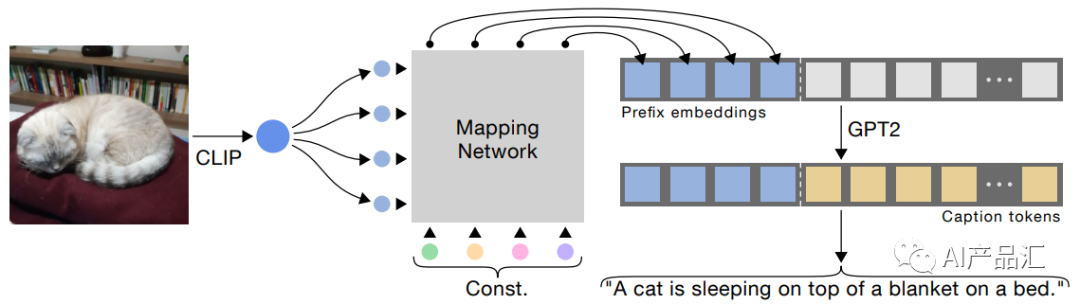
论文链接:https://arxiv.org/pdf/2111.09734.pdf
算法思路:
这篇论文的主要思路是提出了一个名为ClipCap的神经网络模型,用于图像字幕生成任务。其在生成图像字幕时引入了一个预测语言模型的先验知识,并将网络的编码器和解码器部分分别与Vision Transformer(ViT)和Transformer构建而成。与传统方法相比,ClipCap不需要对图像和语言分别编码,而是利用Transformer中的跨模态注意力机制在图像和语言之间进行交互,从而更好地捕捉到图像和语言之间的关联性。此外,ClipCap还使用了基于样条的可形变卷积以减少耦合和避免过度匹配。
算法创新点:
-
提出了一种将ViT和Transformer结合起来的方法,提高了图像字幕生成的性能。
-
引入了预测语言模型的先验知识,提高了图像字幕生成的质量和流畅度。
-
使用跨模态注意机制和可形变卷积来更好地捕捉图像和语言之间的关联性。
-
在多个图像字幕数据集上进行了广泛的实验,证明了ClipCap的有效性和优越性。
算法步骤:
-
预处理输入图像和对应的字幕,将其转换为模型所需的格式。
-
将图像和语言输入到网络中,网络的编码器部分采用ViT结构,将图像嵌入到一个向量空间中。解码器部分采用Transformer结构,将字符序列编码为语义向量。
-
引入预测语言模型的先验知识,将上一步生成的语义向量输入到语言模型中进行预测,生成下一个单词的分布概率。
-
使用跨模态注意机制,对图像、语言、上一步生成的输出进行交互,得到下一个单词的词向量表示。
-
使用可形变卷积网络对图像进行卷积,提高图像和语言之间的匹配性和泛化性。
-
重复执行步骤3-5,直到生成完整的字幕序列。
-
训练网络,使用交叉熵损失函数对生成的字幕和真实字幕之间的差异进行优化。
-
在测试时,通过最大化生成概率来选择最佳的字幕序列,输出生成的图像字幕。
6. 评估指标
Image caption任务的常见评估指标如下所述:
-
BLEU(bilingual evaluation understudy)得分:BLEU是评估机器翻译中语句质量的一种评估指标,也适用于image caption任务。使用BLEU指标需要有参考文本作为标准,计算机生成文字的得分与参考文本相似的程度。BLEU得分越高,表示生成的文字越接近参考文本,相似度越大。BLEU得分是一种基于n-gram匹配的评估方法,效果较为直接。但是BLEU仅会计算预测和给定参考文本之间的n-gram匹配度,并不考虑句法、语义结构等复杂的信息。时,因为BLEU需要参考文本,所以BLEU评测指标可能受到参考文本数量、选择等因素的影响,不具有足够普适性。
-
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)得分:ROUGE是评估自然语言生成任务的指标,可以对生成文本的关键词、n-gram等进行比对,评估生成文本的质量。ROUGE主要是以召回率为基础进行评测,通过计算生成描述中的n-gram数量与参考文本中的n-gram数量来获取ROUGE得分。与BLEU类似,ROUGE也存在一定的问题,比如ROUGE无法体现出生成文本与参考文本的准确度问题,只是在考虑覆盖率和召回率的基础上进行评估。
-
METEOR(Metric for Evaluation of Translation with Explicit ORdering)得分:METEOR也是一种自然语言生成任务的指标,以单词、短语等细节为基础比对参考文本和生成文本似度,可以更准确地评估自然语言生成任务的质量。METEOR不仅仅是在计算n-gram等简单的单词或短语匹配,其在评估时还会考虑多个方面的问题,比如大小写问题、标点问题等问题。METEOR通过计算生成描述与参考文本的精确匹配度、召回率、所涉及到的操作数量、权重等多方面指标,评估生成文本的质量。由于考虑了多方面信息,METEOR评测指标较为完善和准确。
-
CIDER(Consensus-based Image Description Evaluation得分:CIDER是一种基于一致性的图像描述评估指标,主要用于评估生成的图像描述与参考描述之间的一致性。CIDEr与其他评估指标的不同之处在于,它考虑了多个参考描述的相互一致性。CIDEr通过计算候选描述与多个参考描述之间的n-gram匹配得分,然后对这些得分进行加权平均。在计算 n-gram 匹配得分时,CIDEr使用的是特定的权重,这些权重是通过对大量图像描述数据集中的人工标注进行学习得出的。CIDEr的分数范围是0到1,分数越高表示候选描述与参考描述的一致性越高。
-
SPICE(Semantic Propositional Image Caption Evaluation)得分:SPICE是一种语义命题图像描述评估指标,主要用于评估生成的图像描述与参考描述之间的语义一致性。SPICE与其他评估指标的不同之处在于,它考虑了描述中的语义信息,而不是单纯的字符串匹配。SPICE使用句法分析器生成描述的语言结构,然后根据语义提议的正确性对描述进行评分。给定一个语义提议,SPICE会根据提议中的单词和短语在图像中的出现情况,计算提议的吻合度分数。最后,SPICE将所有提议的得分加权平均,得到一个总体得分。SPICE的分数范围是0到1,分数越高表示候选描述与参考描述的语义一致性越高。
7. 开源数据集
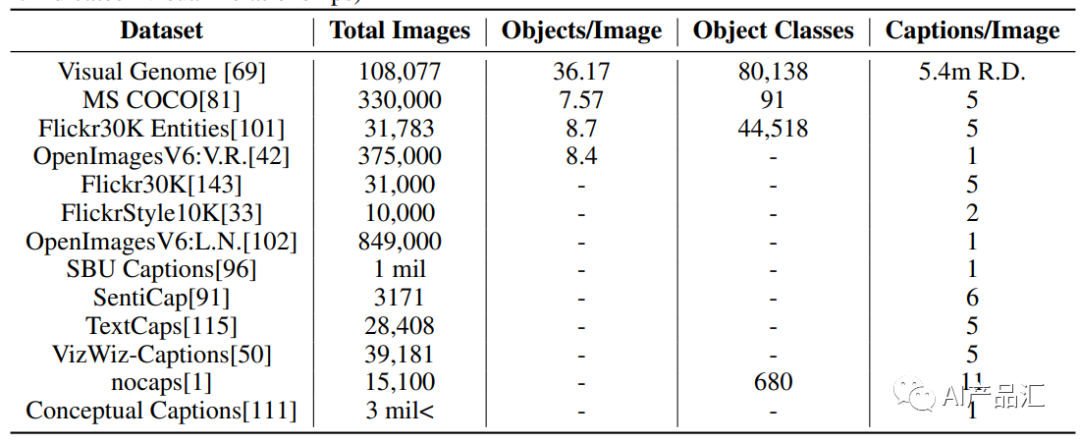
1、COCO (Common Objects in Context)-http://cocodataset.org/#home
简介:COCO数据集是一个大规模常见物体检测、分割和图像描述的数据集。它包含超过330k张图像,其中包括2.5 million个目标实例,每张图像都有5个不同的图像描述。COCO数据集已成为自然语言处理和计算机视觉领域中一个非常优秀的基准数据集。
2、Flickr30K-http://shannon.cs.illinois.edu/DenotationGraph/
简介:Flickr30k数据集是一个基于Flickr网站的数据集,它包括了31,000张图像和每张图像准确的5个人工标注语句。该数据集的图像类型非常丰富,从日常生活场景到复杂的社会场景都有涉及。
3、VisualGenome-http://visualgenome.org/
简介:VisualGenone数据集是一个非常详细的多模态数据集,它包括108,000张图像、4,100,000个视觉和语言关系。每张图片都有5个每个图片独特的图像描述。VisualGenome已经成为自然语言处理和计算机视觉领域中一个非常重要的基准数据集。
4、Multi30k-https://github.com/multi30k/dataset
简介:Multi30k数据集是一个基于Europarl v7多语言语料库,包括29,000张图像,每张图像都有5个多语言图像描述。该数据集的多语言特性为跨语言翻译等任务提供了便利。
5、Flickr8k-https://illinois.edu/fb/sec/1713398
简介:Flickr8k数据集是一个基于Flickr网站的数据集,包含8,000张图像,每个图像对应5个不同的描述。该数据集的特点是句子比较简单、单词数量不多,因此成为了image caption任务中较为容易处理的数据集之一。
6、MIT-Adobe FiveK-http://data.csail.mit.edu/graphics/fivek/
简介:MIT-Adobe FiveK数据集是一个包括了5,000张来自不同摄像机和镜头的图像的数据集。它的目的是衡量图像字幕技术对于从大量全尺寸图像中生成描述的可行性和有效性。
7、Visual7W-https://cs.stanford.edu/people/yukez/research/visual7w/
简介:Visual7W数据集是一个大规模多选择视觉问答挑战数据集,包括30,000多个图像、150,000多个问答对、50,000多个图像描述和72个类别。该数据集在视觉问答、视觉嵌入和视觉对话等任务中都能够提供有效的帮助。
8、Narrativeqa-https://github.com/deepmind/narrativeqa
简介:Narrativeqa数据集是一个基于小说的数据集,它涵盖了401部小说、9704个问题和9万多个答案,每个问题都有一个自由文本答案和多个选择题选项。该数据集对于图像讲故事领域的研究非常重要。
9、Conceptual Captions-https://ai.google.com/research/ConceptualCaptions/
简介:Conceptual Captions是一个基于计算机视觉和自然语言处理的数据集,总共包含了3.3亿张图片和2400万个语句,语句是自动生成的。该数据集非常大,非常适合深度学习算法的训练。
8. 热门论文
1、Show and tell: A neural image caption generator-https://doi.org/10.1109/CVPR.2015.7298935
简介:这篇论文提出了一种基于卷积神经网络的图像说明生成器。通过在卷积神经网络之后添加递归神经网络,该生成器可以从图像中提取特征并生成与图像相关的自然语言说明。
2、Deep visual-semantic alignments for generating image descriptions-https://doi.org/10.1109/CVPR.2015.7298936
简介:这篇论文提出了另一种基于卷积神经网络的图像说明生成器。与其他方法不同的是,它利用了一个新颖的多模态深度神经网络架构,将图像信息与自然语言信息进行对齐。
3、Knowing when to look: Adaptive attention via a visual sentinel for image captioning-https://doi.org/10.1109/CVPR.2017.422
简介:这篇论文引入了“视觉哨兵”概念,该概念可以引导图像说明生成器在对图像进行分析时集中精力于正确的区域。通过在生成器中引入这种注意力机制,该方法可以大幅提高生成的自然语言说明的质量。
4、Neural image caption generation with visual attention-https://doi.org/10.1162/neco_a_00989
简介:这篇论文利用了一种称为“视觉注意力”的机制,使得生成器可以根据图像的视觉特征来调整生成自然语言说明的过程。与传统方法不同的是,这种方法可以对生成的说明进行反复修正,从而提高其质量。
5、DenseCap: Fully Convolutional Localization Networks for Dense Captioning" by Justin Johnson, Andrej Karpathy, Li Fei-Fei. https://doi.org/10.1109/CVPR.2016.91
简介:这篇论文提出了一种称为“密集标注”的方法,该方法可以在给定图像中局部化每个对象,并为每个对象生成自然语言说明。通过使用深度卷积神经网络和自然语言处理技术,此方法可以实现高质量的对象检测和说明生成。
6、Bottom-Up and Top-Down Attention for Image Captioning and Visual Question Answering-https://doi.org/10.1109/CVPR.2018.00070
简介:该论文提出了“自底向上和自上而下的注意力”的概念,该概念可以让图像说明生成器在处理图像中的复杂场景时具有更好的效果。通过在生成器中引入这种注意力机制,可以关注最重要的图像区域,进而提高生成自然语言说明的准确性。
7、Self-critical sequence training for image captioning-https://doi.org/10.1109/CVPR.2017.286
简介:这篇论文提出了一种基于强化学习的方法,可以通过最小化与参考说明之间的距离来训练图像说明生成器。具体来说,该方法引入了一个自我批评机制,使得生成器可以在生成说明后评估其质量,并通过此评估来优化其生成策略。实验结果表明,该方法可以显著提高生成的自然语言说明的质量,达到了当前最先进的水平。
9. 热门仓库
1、neuraltalk2-https://github.com/karpathy/neuraltalk2
简介:这是一个基于深度学习的图像说明生成器。它的架构使用了卷积神经网络和递归神经网络,可以从图像中提取特征并生成与图像相关的自然语言说明。
2、im2txt-https://github.com/tensorflow/models/tree/master/research/im2txt
简介:这是一个基于Tensorflow的图像说明生成器。它的架构采用了卷积神经网络和递归神经网络,可以从图像中提取特征并生成自然语言说明。
3、show_attend_and_tell-https://github.com/kelvinxu/arctic-captions
简介:这是一个基于注意力机制的图像说明生成器。其架构可以从图像中提取特征并根据注意力机制来生成自然语言说明。
4、bottom-up-attention-https://github.com/peteanderson80/bottom-up-attentio
简介:这个仓库提供了一个利用自底向上和自上而下的注意力机制来生成图像说明的框架。它的架构可以在处理大型复杂场景时提高说明的准确性。
5、neural-storyteller-https://github.com/ryankiros/neural-storyteller
简介:这是一个基于卷积神经网络的自然语言说明生成器。它可以从图像中提取特征并生成与图像相关的自然语言说明,并可以在生成说明时逐步细化。
6、ImageCaptioning.pytorch-https://github.com/mvezivishal/ImageCaptioning.pytorch
简介:这是一个基于PyTorch的图像说明生成器。它可以使用卷积神经网络和递归神经网络提取图像特征并生成与图像相关的自然语言说明。
7、image_captioning-https://github.com/keon/image_captioning
简介:这是一个基于卷积神经网络的图像说明生成器。它可以从图像中提取特征并生成自然语言说明。
8、awesome-image-captioning-https://github.com/ChahatBhatia/awesome-image-captioning
简介:该仓库是一个收集了各种图像说明生成器和相关资源的列表。其中包括论文、代码和数据集等。
9、Image-Captioning-https://github.com/adityathakker/Image-Captioning
简介:该仓库包含了一个基于深度学习的图像说明生成器。它使用卷积神经网络和递归神经网络来提取图像特征和生成自然语言说明。
10、image_captioning-https://github.com/rastogi-yogesh/image_captioning
简介:这是一个基于TensorFlow的图像说明生成器。它使用卷积神经网络和递归神经网络来提取图像特征和生成自然语言说明。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mFoKNRVh-1686465523894)(/imgs/2023-06-11/aKXxrqjLXjQwTBfG.png)]](https://i-blog.csdnimg.cn/blog_migrate/5d0b05ecab34a1732f8497fc58492f38.png)
转载自:https://mp.weixin.qq.com/s/EEMDKmAXoYzmlissmNTb4g


















 627
627

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











