







内容概览
前言
这篇论文提出了一个采用非episodic training方法的少样本图像分类算法,作者来自巴黎萨克雷大学,于2020.12.26挂在arxiv上:论文链接
这篇论文的实验结果比较好,并且在预训练时采用了注意力的思想,获得了一个良好的特征提取器。因此我把它的算法记录下来,应当会有参考意义~不过需要注意,这个算法仍采用了有监督的预训练。
从算法来看,这篇论文同样认为episodic training的方式不是最优解。(关于episodic training的说法,可以参考这篇博文)我也认为,在解决少样本学习这个问题中,获得一个泛化性能好、提取特征优秀的特征提取器才是关键!而元学习不是唯一的解决方法。
一、空间对比学习(Spatial Contrastive Learning)
论文中在预训练时,选择有监督的图像分类训练,采用最基本的交叉熵损失,但为了提升训练的效果,作者提出了空间对比学习,即在分类训练的同时,向损失函数中加入空间对比学习损失,最终获得预训练的损失函数如下:

L
C
E
L_{CE}
LCE表示图像分类的交叉熵损失,
L
S
C
L_{SC}
LSC表示空间对比损失。
接下来我们来看作者的Spatial Contrastive Learning是如何实现的~
1.对比学习
首先我们需要知道什么是对比学习,对比学习是指在特征域拉近相似正样本对之间的距离,拉远负样本对的距离。什么是正样本对和负样本对呢?这里需要分两种情况:
- 在有监督对比学习中:每张图像都有类别标签,那么属于同一类的两张图像就是一个正样本对,属于不同类别的两张图像构成一个负样本对;
- 在无监督对比学习中:每张图像没有标签,这时将每张图像都进行随机变换,比如裁剪、随机旋转、色彩变化等,一张图像就可以获得几个不同的变体。我们认为同一张图像的两个变体就构成一个正样本对,不同图像的变体之间构成负样本对。
无论是哪种类型的对比学习,其训练时使用的损失函数都具有相同的结构:
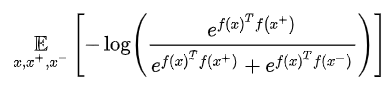
f
(
x
)
f(x)
f(x)表示对图像
x
x
x提取到的特征,
x
+
x^+
x+表示
x
x
x的正样本对图像,
x
−
x^-
x−表示
x
x
x的负样本对图像,这个损失的意义就是要拉近正样本对的特征距离,而拉远负样本对的图像距离。即希望
e
f
(
x
)
T
f
(
x
+
)
e^{f(x)^Tf(x^+)}
ef(x)Tf(x+)大,
e
f
(
x
)
T
f
(
x
−
)
e^{f(x)^Tf(x^-)}
ef(x)Tf(x−)小。
式子里写成
e
s
i
m
i
l
a
r
i
t
y
(
f
(
x
)
,
f
(
x
+
)
)
e^{similarity(f(x),f(x^+))}
esimilarity(f(x),f(x+)) 更好,
s
i
m
i
l
a
r
i
t
y
(
x
,
y
)
similarity(x, y)
similarity(x,y)可以是余弦距离或是负的欧式距离。
2.全局对比损失
这篇论文中主要采用有监督的对比学习,在实验时也测试了无监督对比学习的损失函数对结果的影响。但我们仍以有监督对比为主进行讲解。
先介绍一下论文中的符号~
f
ϕ
f_\phi
fϕ:特征提取网络,可以将输入图像
x
x
x转变为空间特征
z
s
∈
R
H
W
∗
d
z^s\in R^{HW*d}
zs∈RHW∗d,对这个空间特征进行global pooling,得到全局特征
z
g
∈
R
d
z^g\in R^{d}
zg∈Rd。
f:
z
g
z^g
zg经过映射头之后的降维特征,维度变为
R
d
′
R^{d'}
Rd′
于是,有监督对比损失函数可以写为:
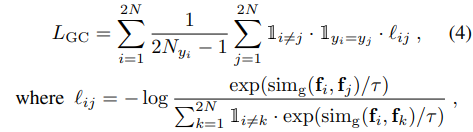
在论文中又被称为全局对比损失函数(GC),可以看到图像的标签
y
y
y 决定着两张图像是一组正样本对,还是负样本对。文中
s
i
m
g
(
)
sim_g()
simg()使用的是余弦距离。
3.空间对比损失
可以看到,上面的全局对比损失是磨灭了特征图的空间特征:对于特征在空间维度上实施了全局池化,因此会忽略特征的空间特性。作者基于此提出了空间对比损失,在 z s ∈ R H W ∗ d z^s\in R^{HW*d} zs∈RHW∗d层面上计算对比损失,保留空间位置信息。
对比损失中最重要的部分是两张图像全局特征间的相似度,即
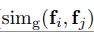
那么空间对比损失中,两张图像相似度的计算就是对于两张图像的空间特征,在每个空间位置上都按上述方式计算一次相似度,再将结果相加取平均。
这也是作者的做法,不过在此之前,作者引入了注意力机制,对一个正/负样本对中的两张图像的空间特征进行了修正。因此求两张图像之间空间相似度的方式变成了:
用
a
a
a图像的特征修正
b
b
b图像特征,再用修正后的
b
b
b特征与原始
a
a
a特征求相似度;再将这个操作反过来进行一遍,即用
b
b
b修正
a
a
a,并计算修正后的
a
a
a特征与原始
b
b
b特征的相似度。将上面两个相似度相加,就是最终的相似度。如下:
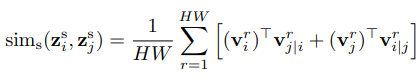
r
r
r表示空间位置,
v
i
r
v_i^r
vir表示图像
i
i
i的第
r
r
r个空间位置的特征向量,
v
i
∣
j
r
v_{i|j}^r
vi∣jr表示用
j
j
j图像特征修正后的
i
i
i图像特征,在第
r
r
r个位置处的特征向量。
这个过程可以用下图直观地表示:

二、特征的修正
前面我们说到作者使用修正后的特征计算空间对比损失,那么如何进行这个修正呢?
作者是使用了注意力机制的思想,针对一张图像的空间特征,生成了
k
e
y
,
q
u
e
r
y
,
v
a
l
u
e
key, query, value
key,query,value这三个注意力机制中的要素。在用
j
j
j修正
i
i
i时,使用
i
i
i的
q
u
e
r
y
query
query与
j
j
j的
k
e
y
key
key计算相似度,并将结果乘在
i
i
i上:
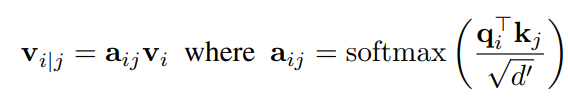
我个人感觉这个过程是想要找到
i
,
j
i,j
i,j 两特征中对相似度影响大的那些空间位置,体现在相似度矩阵
a
i
j
a_{ij}
aij中,再使
i
i
i 突出这些有更大影响力的空间位置处的特征,完成特征修正(或者说是“联合”)。这样可以使得最终计算出的相似度更有效。
文中仍有一张图可以描述该过程:

三、对比蒸馏(Contrastive Distillation)
作者加入蒸馏的目的是起到正则化项的作用,防止前面的训练过程太优秀,而使得在基类数据集上训练得到的特征提取器,不能很好地迁移到新的类别上去👅于是想通过蒸馏的方式,从前面训练好的网络中,再训练出一个新的学生网络;训练时不使用图像的真实标签,而是用原(教师)网络的输出作为标签,以实现正则化的目的。
As such, to avoid an excessive disentanglement of the learned features and to further improve the generalization of the embedding model, we propose Contrastive Distillation (CD) to relax the placement of the features in embeddings space.
蒸馏学习是从原网络(teacher)中获取新网络(student)的方法,这里不做详细介绍。一般的蒸馏学习中,会计算学生分类网络与教师分类网络的分类结果之间的KL散度,并作为一项损失函数。在本文中除了KL散度损失,作者又加入了一项contrastive distillation loss
L
C
D
L_{CD}
LCD,即计算教师网络提取的图像特征与学生网络提取特征之间的距离,这是在特征域进行对比,因此称为对比蒸馏,式子为:
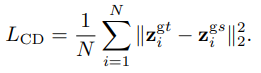 其中
t
t
t表示教师网络,
s
s
s表示学生网络。
其中
t
t
t表示教师网络,
s
s
s表示学生网络。
最终的蒸馏损失表示为:
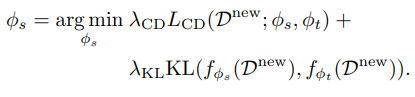
四、少样本分类
上面的所有过程都是在描述预训练时,损失函数的构造。这一部分要讲一下,在完成预训练后如何进行少样本图像分类。
通过预训练我们获得了良好的特征分类器,在一个少样本学习任务中,
- 将 s u p p o r t support support及 q u e r y query query中所有样本通过特征提取器,获得它们的特征;
- 直接用 s u p p o r t support support和sklearn中的线性分类器,训练 一个分类器;(盲猜逻辑回归🙃)
- 把 q u e r y query query图像特征送入分类器,获得预测结果。
So easy有木有,竟然连全连接层都不要了,直接用机器学习也能获得很好的效果!
事实证明,只要特征算得好,分类器可以随意了~
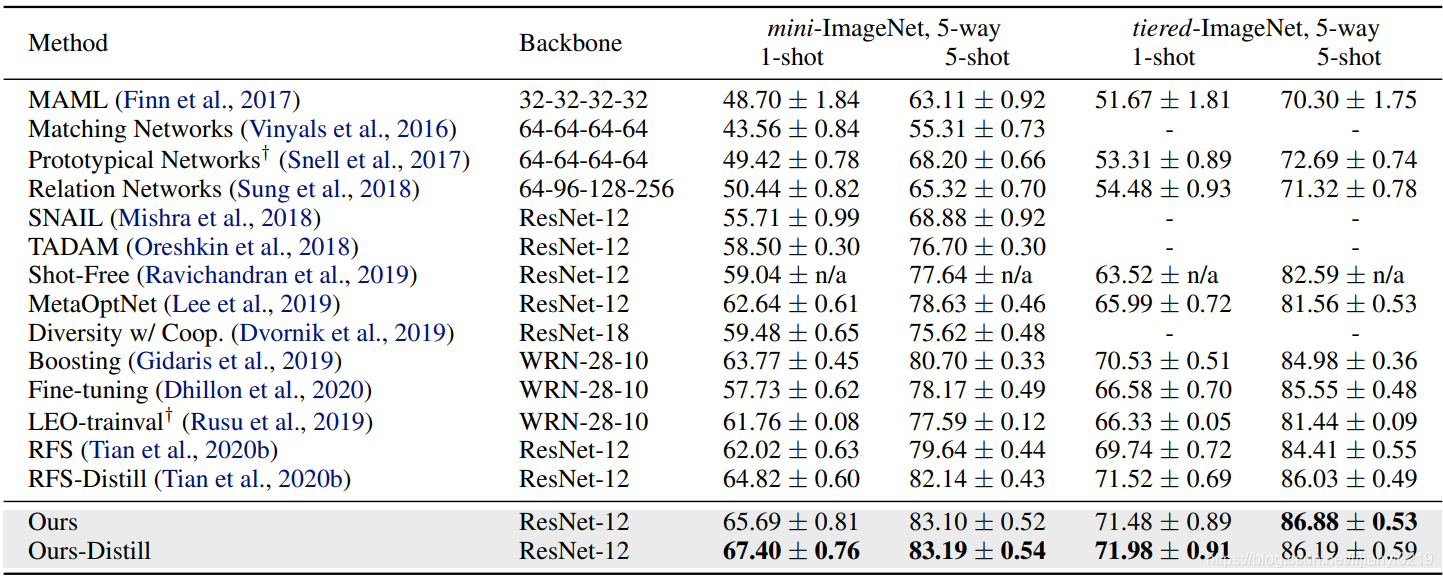
五、实验结果
论文中有多组对比实验,包括预训练时损失函数的不同设置对比,有无对比蒸馏的对比以及训练时batchsize的大小、蒸馏次数的对比,大家可以去原文查看。这里只放一个和其他少样本学习算法的对比结果,这篇论文还是可以的~
(蒸馏还是有效的😁)
总结
2021年的第一篇博文,献给论文解读了哈哈哈哈。
选择这篇论文主要是因为这是 我最近看的一篇 我认为符合研究趋势的论文(●ˇ∀ˇ●),并且引入了空间位置信息,虽然想法也不是特别新鲜,但融合了2020年各种热门元素(对比学习、注意力机制),而且实验结果挺好哒~

















 1367
1367

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









