







 本文介绍了VisionTransformer(ViT)如何通过自注意力机制处理图像数据,克服CNN的局限。同时,讨论了MaskedAutoencoder(MAE)的改进,如预训练方法和不同类型的模型调整策略,如partialfine-tuning,以提升视觉学习的效率和泛化能力。
本文介绍了VisionTransformer(ViT)如何通过自注意力机制处理图像数据,克服CNN的局限。同时,讨论了MaskedAutoencoder(MAE)的改进,如预训练方法和不同类型的模型调整策略,如partialfine-tuning,以提升视觉学习的效率和泛化能力。
Vision Transformer (ViT)
论文出处[2010.11929] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (arxiv.org)
传统的卷积神经网络(CNN)在图像分类、目标检测等任务上表现出色,但其局限性也逐渐显露:对大规模数据的依赖、对局部特征的过度关注等。ViT的出现颠覆了传统认知,它采用了自注意力机制(self-attention)来捕捉图像全局信息,避免了CNN中固有的局部感知问题。
但是图片数据是信息量十分大的,这个和1语言有着本质区别。人们日常沟通的语言都是具备高密度信息的,是高度凝练的结果。所以再注意力机制解决NLP问题的任务中,一般是以句子的形式去处理文本。但是在图片的角度来说这是完全不可行的。我们不能直接无脑的把一个图片按照所有的像素来展开,这样去做注意力机制产生的计算量是十分惊人的。
为了解决这个问题,ViT模型将输入图像分成若干个图块,通过线性变换后将它们展平成序列,然后引入自注意力机制对序列进行处理,最终完成图像分类等任务。这种全注意力的机制使得ViT在一定程度上克服了CNN的不足,并在多个视觉任务上展现了出色的性能,比如在ImageNet数据集上的表现超越了传统CNN模型。
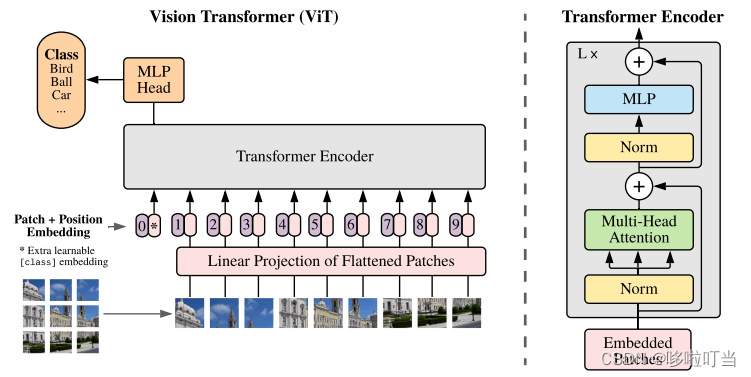
工作流程
-
图像分块: 首先,输入的图像被分割成固定大小的图块。每个图块包含像素信息,并被视为序列化的数据。
-
嵌入式嵌入(Embedding): 接下来,每个图块通过一个线性投影(projection)转换为具有更高维度的特征向量,以便进行后续处理。
-
位置编码(Positional Encoding): 为了保留图块之间的空间位置信息,一个位置编码向量被添加到每个图块的特征向量中,以区分它们在输入图像中的位置。
-
Transformer编码器: 特征向量(包含位置编码)随后被输入到Transformer编码器中。这里的Transformer编码器通常包含多个Transformer块,每个块由多头自注意力机制(Multi-head Self-Attention)和前馈神经网络(Feed-Forward Neural Network)组成。
-
自注意力机制(Self-Attention): 通过自注意力机制,每个图块可以“关注”其他所有图块,从而捕捉全局特征。这种机制使得ViT能够实现对整个图像的全局感知,而非局部。
-
前馈神经网络(Feed-Forward Neural Network): 在自注意力机制之后,每个位置的特征向量会经过一个前馈神经网络进行非线性变换,以更好地学习特征表示。
-
-
Transformer解码器(可选): 在某些任务中,ViT可能还包含一个Transformer解码器,用于执行特定的输出任务,如图像分类、目标检测等。
-
输出层: 最终,ViT的输出会通过一个适当的输出层结构进行处理,如全连接层用于图像分类,或者特定的检测头用于目标检测。
Masked Autoencoder (MAE)
论文出处
[2111.06377] Masked Autoencoders Are Scalable Vision Learners (arxiv.org)
MAE其实就是ViT的一个改进。这个改进有点类似于Denoising Autoencoder的思想。作者把图片的可见patch转成序列形式,用编码器进行编码,前后的维度是不变的,根据位置嵌入给序列加上被掩码的部分,再做decoder解码,解码后的维度也不变,但是解码器预测还原出了一个patch序列,然后转化可以成为一个新的清晰图片。可以观察到encoder画的比decoder更大,因为编码器是更加复杂的,需要深层网络去学习图片的特征,但是decoder只是一个轻量的解码器
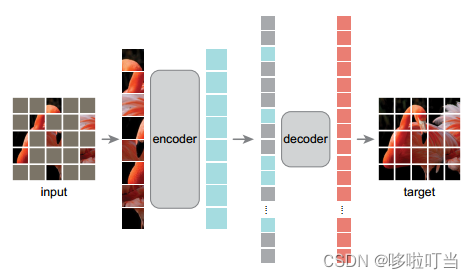
MAE模型预训练
-
切分图片,随机均匀的采样策略,挑选其中的一小部分作为训练的输入,其余都被mask
-
针对可见的部分做位置编码得到encoder patches
-
做位置还原,加入被掩码的部分mask ed patches
-
decoder做预测,预测缺失部分的像素点
-
loss部分就是和原来的图片计算MSE
linear probing:在预训练模型的后面加上一些线性变换层来做下游任务改造,不会影响到整个模型的参数
fine tune:微调模型,会修改整个模型的参数
几个关键的点
-
不同的mask对应的是不同的语义输出,模型可以有泛化能力。作者选用了75%的mask比例,他们对模型的linear probing和fine tune统计比较实验都发现这个比例最合适
-
decoder的深度和宽度对于linear probing影响很大,对于fine tune比较小,这是因为linear probing只会调整模型的浅层,受预训练模型约束较大
-
encoder不需要使用masked token,这个位置和NLP有区别,因为下游任务是看不到这些部分的。BERT的encoder和MAE的decoder的类似,MAE先用不带mask的部分encoder是为了获取高维语义信息,提高信息的密度,这是图片和文字任务区别,文字本身就是一个高密度的信息,而图片中含有很多的无用信息。这也解释了为什么要选用75%这么高比例的mask,因为图片本身的冗余信息太多了,只有mask高到了一定的比例任务才会具有挑战性,模型才能更好地学习
-
重建像素用到了归一化像素值的方式,这样可以让patch之间的差异更加明显模型能够学习到更多的特征
-
数据增强的效果其实不是很明显,因为MAE这个操作本身就是一个数据增强
Partial Fine-tuning:
作者提出的一个概念,结合linear probing和fine tune,调整encoder的最后一部分的层,达到两者之间效果的一个均衡



















 961
961

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











