







项目仓库
GitHub - JJLi0427/Model_Params_Analyzer
项目已经开源到github,欢迎做更多的开发和提出issue
项目介绍
在做一些深度学习的项目时,经常要做一些模型参数量和运算效率,指标变化效果的实验,如果有一个合适的工具可以可视化观察项目的参数量分布,并且有一些总量和占比的计算,可以极大优化工作效率,为此开发了这一款工具
项目基于pyecharts库开发,实现了基于模型参数字典的树图绘制,以及矩形树图的绘制,用户可以直观的知道模型各个部分的参数关系和参数量以及占比
图表效果演示
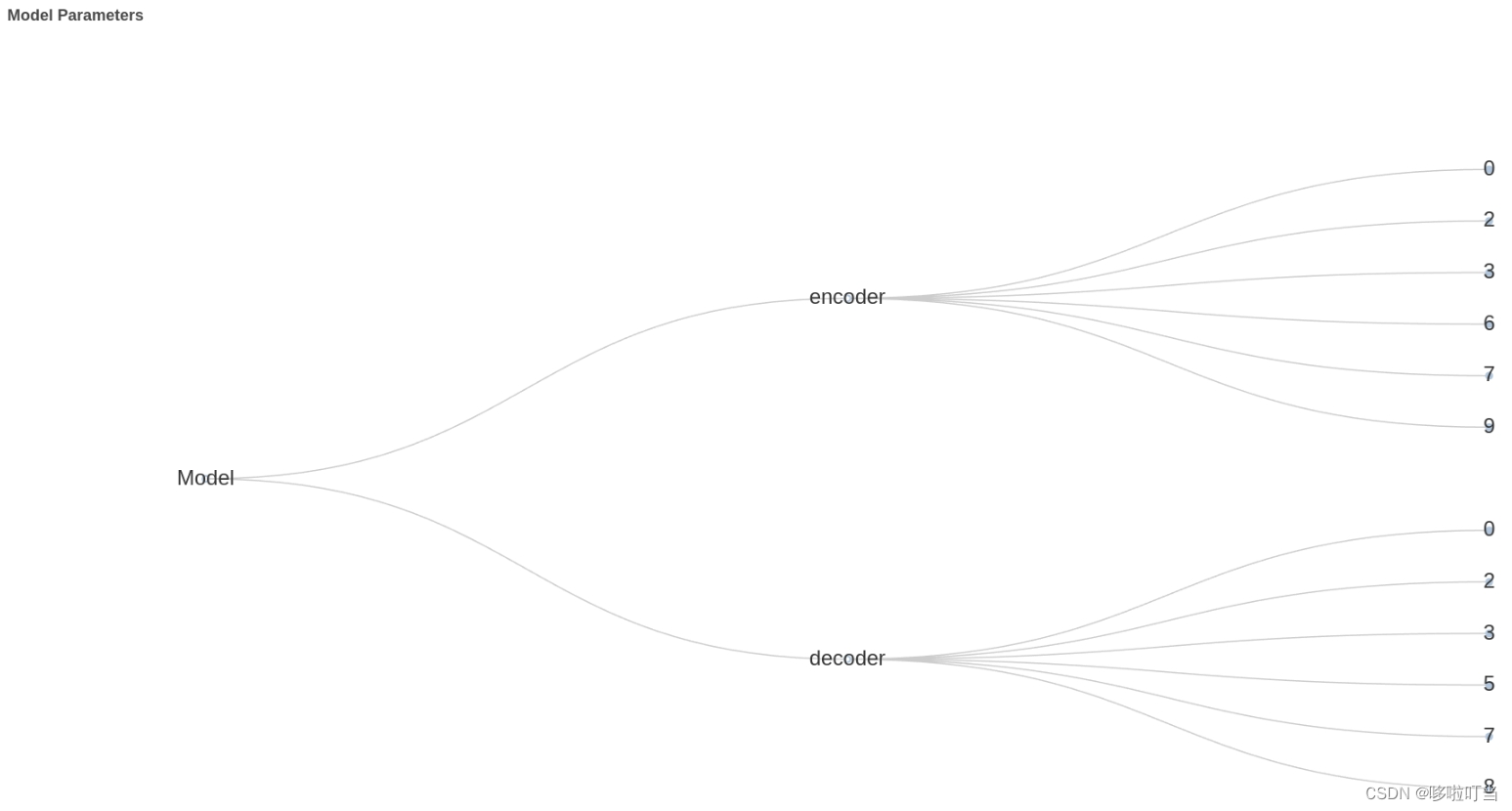
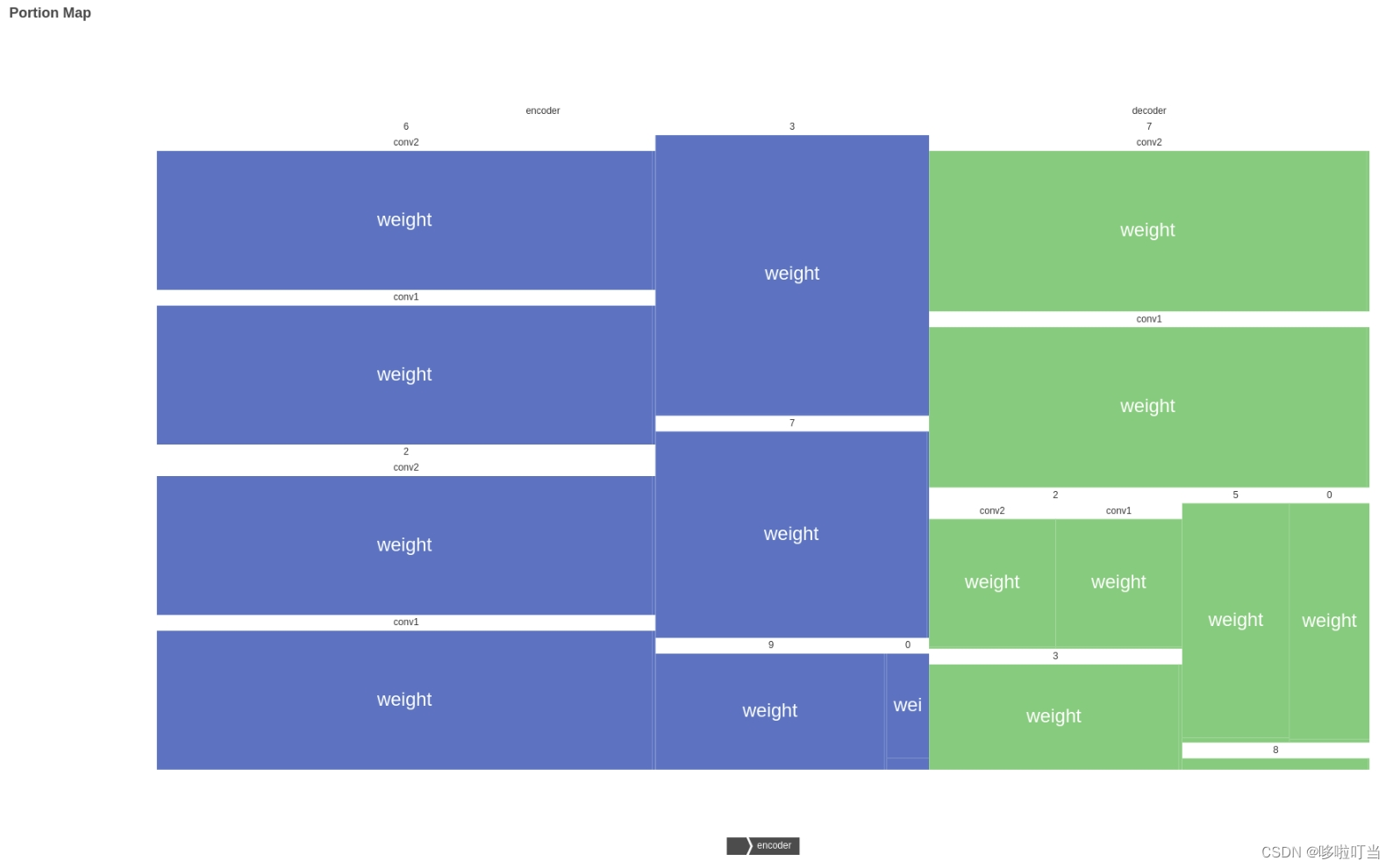
使用方法
项目已经上传到PYPI,支持从pip直接安装mpanalyze
pip install mpanalyze分析模型,在模型的类已经被初始化之后,调用mpanalyze的params_analyze
import mpanalyze
mpanalyze.params_analyze(${model})params_analyze一些其他的参数配置:
- params_analyze
model: 对象 | 要分析的模型 -
name: 字符串(可选) | 模型的名称,它将用于命名分析文件夹,如果未指定,目录名称将为 'params_analyze' -
port: 整数(可选) | 用于HTTP服务器的端口,如果未指定,浏览器将不会被打开。建议只在调试模式下使用,如果在训练中使用,它将阻塞训练过程。 save_dict: 布尔值(可选) | 是否将参数保存到JSON文件,默认为True-
tree: 布尔值(可选) | 是否绘制树形图,默认为True -
treemap: 布尔值(可选) | 是否绘制树状图,默认为True。
如果只想获取参数分析的字典,可以用下面这种方式
param_dict = calculate_dict(model)拿到param_dict字典还可以用于其他的深度学习网络分析工作

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











