









在做外汇掉期交易的时候,除了需要关注中美息差的走势,也需要了解市场流动性的松紧程度。央行的公开市场操作是市场流动性拼图里面非常重要的一块。实际工作中,有些资讯系统(例如Bloomberg)可以调出央行MLF和逆回购的信息,甚至可以通过专门的excel模板对央行公开市场操作进行观测。但是有时候用起来总感觉不是太符合观察习惯,而且MLF(中期借贷便利)这类数据只能在线使用,系统并没有提供了每一期的操作数据供下载,从而生成个性化定制的央行公开市场操作分析。
没有此类数据分析,要么就只能通过手工将央行所有的历史操作数据下载,然后手工计算出未到期操作总量,从而对MLF到期续作可能的时间窗口和续作数量进行推测;或者只能被动的从一些财经号上面偶尔提示的:“本月MLF到期万亿,市场流动性面临大考”这类的分析获得提示。这掐头去尾的数据,对于实际交易而言,前瞻性不足,也无法跟此前的数据进行比较观察。
基于此,我写了一个自动下载央行公开市场操作数据的小脚本。由于央行的网站是用Java进行渲染,因此在下载数据时,本文直接调用Requests_html里面的HTMLSession,自动对网页进行Java渲染。接着把渲染后加载的网页源代码下载,直接通过requests_html自带的Xpath进行网页解析,提取网页上面的公开操作信息表格。保存到本地后通过熊猫对数据进行清洗、分析和可视化。下面是操作的具体思路:
一、导入requests_html,下载数据
二、数据准备
2.1 读取原始数据
2.2 数据清洗&整理
2.3 拼接根据操作期限生成的现金流数据框
2.4 Matplotlib画图
一、导入requests_html,下载数据
requests_html的具体使用可以参考下面的代码,需要注意下面一些细节:1)random_header还是挺有用的;2)由于requests_html用的是异步协程,速度过快容易遭到下载网页的屏蔽,timeout数字取一个大数也很有必要,sleep多睡两秒也非常需要,这样不至于给数据下载网页造成太大压力; 3)Xpath用了各种轴定位的语句,但由于央行2004年以来公开市场操作的网页格式不时有调整,需要随时观察实际出现的问题从而进行微调。我会在下载时另开一个单个网页的调试脚本,以随时观察出现问题的页面,进而对xpath进行调整。
import time
from requests_html import HTMLSession
import csv
import random
f=open("央行回购公开市场操作.xlsm",mode="w",newline="",encoding='utf_8_sig')
csvwriter=csv.writer(f)
main_url="http://www.pbc.gov.cn"
def random_header():
users = {
1 : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:62.0) Gecko/20100101 Firefox/62.0',
}
x= random.sample(users.keys(),1)[0]
random_user=users[x]
header={"User-Agent":random_user}
return header
def Get_html(url,sec=30):
header=random_header()
session=HTMLSession()
r=session.get(url,verify=False,headers=header)
r.html.render(timeout=sec,wait=1.5,retries=25,sleep=1.5)
return r.html
for i in range(1,138):
url=f"http://www.pbc.gov.cn/zhengcehuobisi/125207/125213/125431/125475/17081/index{i}.html"
r1=Get_html(url)
child_url_lst=r1.xpath("//*[@id='17081']/div[2]/div[1]/table/tbody/tr[2]/td/table/tbody/tr/td[2]/font/a/@href")
for item in child_url_lst:
child_url=main_url+item #拼接每日的公开市场公告URL
r2=Get_html(child_url)
Date = r2.xpath('//*[@id="shijian"]//text()')
Date="".join(str(item) for item in Date)
print(f"********解析网页{Date}********:")
Note = r2.xpath("//*[@id='zoom']/descendant::p[contains(string(),'情况') or contains(string(),'不') or contains(string(),'无')][1][normalize-space()]//text()[normalize-space()]")
operation_tables=r2.xpath(r"//*[@id='zoom']//table") #往下找到Table的数量
if len(operation_tables)>0: #如果len==0,则意味着央行当天没有任何操作,但是会通过Note表明市场的实际流动性情况
for table_num in range(1,len(operation_tables)+1): #如果当日有MLF、央票以及逆回购同时操作,会有2+张表格
if len(r2.xpath(f'//*[@id="zoom"]/descendant::table[position()={table_num}]/preceding-sibling::p')) > 0: # 如果table没被p标签括起来,等级和p标签同级
Operation_type = r2.xpath(f"//*[@id='zoom']/descendant::table[position()={table_num}]/preceding-sibling::p[contains(string(),'情况')][1][normalize-space()]//text()[contains(string(),'情况')][normalize-space()]")
else: # table被p标签括起来,等级低于p标签
Operation_type = r2.xpath(f"//*[@id='zoom']/descendant::table[position()={table_num}]/parent::div/preceding-sibling::p[contains(string(),'情况')]"
f"[normalize-space()]//text()[contains(string(),'情况')][normalize-space()]")[-1].replace("\n","").replace(" ","")
#由于央票和逆回购的表格展示列数不一样,需要做如下判断,从而提取正确的信息
if len(r2.xpath(f"//*[@id='zoom']/descendant::table[position()={table_num}]/tbody/tr[1]//descendant::td"))> 3:
Tenor = r2.xpath(f"//*[@id='zoom']/descendant-or-self::table[{table_num}]/tbody/tr[position()>=2][normalize-space()]/td[normalize-space()][3]/descendant-or-self::text()[normalize-space()]")
Amount = r2.xpath(f'//*[@id="zoom"]/descendant-or-self::table[{table_num}]/tbody/tr[position()>=2]/td[normalize-space()][2]/descendant-or-self::text()[normalize-space()]')
Rate = r2.xpath(f"//*[@id='zoom']/descendant-or-self::table[{table_num}]/tbody/tr[position()>=2]/td[normalize-space()][4]/descendant-or-self::text()[normalize-space()]")
else:
Tenor = r2.xpath(f"//*[@id='zoom']/descendant-or-self::table[{table_num}]/tbody/tr[position()>=2][normalize-space()]/td[normalize-space()][1]/descendant-or-self::text()[normalize-space()]")
Amount = r2.xpath(f'//*[@id="zoom"]/descendant-or-self::table[{table_num}]/tbody/tr[position()>=2]/td[normalize-space()][2]/descendant-or-self::text()[normalize-space()]')
Rate = r2.xpath(f"//*[@id='zoom']/descendant-or-self::table[{table_num}]/tbody/tr[position()>=2]/td[normalize-space()][3]/descendant-or-self::text()[normalize-space()]")
csvwriter.writerow([Date,Note,Tenor,Amount,Rate,Operation_type])
else:
csvwriter.writerow([Date, Note])
continue
print(Date, " Downloaded!")
time.sleep(2.5)
time.sleep(3)
print(f"*******************Page {i} downloaded!*******************")
f.close()
print("All data downloaded! ")二、数据准备
2.1 读取原始数据
调入数据分析相关库,定义表格读写函数。下面的表格读写函数其实是我在其他分析项目里为既有公式又有数据的excel准备的。本文下载的央行公开市场数据excel表其实并没有写入公式,懒得改,直接拿来用得了。
由于央行在进行公开市场操作时,有时候会在同一天进行不同期限的正逆回购,并同时进行MLF操作,甚至在同一天还有央行票据的操作。但是在下载数据的时候,我会在一个单元格里面写入同天进行的所有品种的操作期限,也会在一个单元格里面写入同天进行的所有品种的操作金额、操作价格。
这样做下载时方便了,但是在后续对现金流进行处理的时候,加总等操作不是太方便。在查看了网上多种方案后,本文写了一个能同时爆炸3列的函数(explode1),这函数能同时把同一行三个单元格(三列)内的多个信息,展开成多行。(例如,如果当日央行进行了两个期限的逆回购 ,同时又续作了一次MLF,则操作期限、操作金额以及操作价格的单元格内均有三份信息,也即三段字符串对这三个操作进行描述。)因此需要把这三个信息展开成三行,从而在后续能生成不同日期区间的现金流,方便对其进行加总处理,从而得出央行操作在每一天的存量加总信息。
import pandas as pd
import numpy as np
from datetime import date,datetime,timedelta
import calendar
from openpyxl import *
from openpyxl.utils.dataframe import dataframe_to_rows
import warnings
warnings.filterwarnings('ignore')
from itertools import chain
import matplotlib.pyplot as plt
from matplotlib.pyplot import MultipleLocator
from matplotlib.dates import MonthLocator
import matplotlib.dates as mdates
from matplotlib.widgets import Cursor
wb_without_formula=load_workbook(filename='央行回购公开市场操作.xlsm',data_only=True) #不带公式
#逐句读取Dataframe,写入excel表的函数
def write_sheet(worksheet,dataframe,index=False,header=False):
for row in dataframe_to_rows(dataframe,index=index,header=header):
worksheet.append(row)
#逐句读取DataFrame,写入excel表,保存到本地或关闭所在表格
def write_df_save_close(source_data,dest_filename='empty_book.xlsx',write=True,name="Final"):
wb=Workbook()
ws=wb.create_sheet(title=name)
write_sheet(ws,source_data,index=True,header=True)
if write==True:
wb.save(filename=dest_filename)
print("workbook {} saved.".format(dest_filename))
else:
wb.close()
print("workbook {} closed.".format(dest_filename))
#读取原excel表所有sheet,把每张表追加到字典并返回,同时生成新excel表的函数
def create_new_file_with_source_wb(source_wb,dest_filename='MLF操作.xlsm',write=True):
source_dict={}
sheet_names=source_wb.get_sheet_names()
wb=Workbook()
for name in sheet_names:
sheet_ranges=source_wb[name]
temp_df_name=name
temp_df=pd.DataFrame(sheet_ranges.values)
source_dict[temp_df_name]=temp_df
ws=wb.create_sheet(title=name)
write_sheet(ws,temp_df,index=True,header=True)
if write==True:
wb.save(filename=dest_filename)
else:
wb.close()
return source_dict
def reset_df_format(df):
df.columns=df.iloc[0]
df.drop(0,axis=0,inplace=True)
df.set_index(df.iloc[:,0],drop=True,inplace=True)
del df[df.columns[0]]
df.dropna(inplace=True)
return df
#对同一行三个不同单元格内的列表进行展开,变成三行数据从而方便后续的求和操作
def explode1(df,col1,col2,col3):
df['tmp']=df.apply(lambda row:list(zip(row[col1],row[col2],row[col3])),axis=1)
df=df.explode('tmp')
df[[col1,col2,col3]]=pd.DataFrame(df['tmp'].tolist(),index=df.index)
df.drop(columns='tmp',inplace=True)
return df2.2 数据清洗&整理
原始数据在下载时会混入各种分隔符号(逗号、空格、中括号等等),接下来需要对导入的原始数据进行清洗。下面用最简单粗暴的replace和过渡df来处理,目测也可以通过导入正则库[RE]进行处理,得空再试试。
下面的代码是读取MLF的公开市场操作数据,主要用了replace剔除掉奇奇怪怪的字符。由于MLF虽然是自2014年创设,但是公告上只有2017年以来的操作数据,数据结构相对简单。除了操作期限需要借助过渡df来拼接一下字符串,操作金额和操作价格都只是简单的把不需要的字符串替换掉,然后直接根据【,】进行split处理就可以。split完之后,expand记得设成False,最后用爆炸函数【explode1】炸开成相应的行信息即可。
df_dict_value_mlf = create_new_file_with_source_wb(wb_without_formula,dest_filename='MLF操作.xlsm',write=False)
mlf_df=df_dict_value_mlf['MLF操作']
mlf_df=reset_df_format(mlf_df)
#DatetimeIndex格式重设!!!
mlf_df.index=mlf_df.index.format(formatter=lambda t:f'{t:%Y-%m-%d}')
#把mlf_df的操作金额这列在单元格内切分成列表,但是不展开成多列。
mlf_df['操作金额']=mlf_df['操作金额'].str.replace(r", '亿元'","").str.replace("\[","").str.replace("\]","").str.replace(" ","").str.split(",",expand=False)
#把mlf_df的操作价格这列在单元格内切分成列表,但是不展开成多列。
mlf_df['操作价格']=mlf_df['操作价格'].str.replace("\[","").str.replace("\]","").str.replace(" ","").str.split(",",expand=False)
bdg_df=mlf_df['操作期限']
bdg_df=bdg_df.str.replace("\[","").str.replace("\]","").str.replace("\'","").str.split(",",expand=True)
bdg_df[0]=bdg_df[0].fillna("")+bdg_df[1].fillna("")
bdg_df[2]=bdg_df[2].fillna("")+bdg_df[3].fillna("")
del bdg_df[1],bdg_df[3]
bdg_df[0]=bdg_df[0].str.cat(bdg_df[2],",")
mlf_df['操作期限']=bdg_df[0]
mlf_df['操作期限']=mlf_df['操作期限'].str.split(",",expand=False).fillna("")
mlf_df=explode1(mlf_df,'操作金额','操作价格','操作期限')
write_df_save_close(mlf_df,dest_filename='MLF_BALANCE.xlsx',write=True,name="mlf_df")
print(mlf_df.tail(10))下面的代码是读取正逆回购的公开市场操作数据,先是用了replace剔除掉奇奇怪怪的字符。操作期限、操作金额和操作价格均需要借助过渡df来拼接一下字符串,然后直接根据【,】进行split处理。同样的,split完之后,expand记得设成False,最后同样用爆炸函数【explode1】炸开成相应的行信息。
df_dict_value_repo = create_new_file_with_source_wb(wb_without_formula,dest_filename='repo操作.xlsm',write=False)
repo_df=df_dict_value_repo['回购']
repo_df=reset_df_format(repo_df)
#DatetimeIndex格式重设!!!
repo_df.index=repo_df.index.format(formatter=lambda t:f'{t:%Y-%m-%d}')
#清洗操作金额列,替换完成后拼合成字符串存放在单元格1中,然后再重新展开成列表
bdg_df1=repo_df['操作金额']
bdg_df1=bdg_df1.str.replace(r", '亿元'","").str.replace("\[","").str.replace("\]","").str.replace("亿","").str.replace("元","").str.replace("\'","").str.split(",",expand=True)
bdg_df1[0]=bdg_df1[0].str.cat(bdg_df1[1].fillna(""),",").str.cat(bdg_df1[2].fillna(""),",").str.cat(bdg_df1[3].fillna(""),",").str.rstrip(",")
bdg_df1[0]=bdg_df1[0].str.replace("\ , ","").str.rstrip(",").str.replace(" ","")
# write_df_save_close(bdg_df1,dest_filename='repo_test1.xlsx',write=True,name="test1_df")
repo_df['操作金额']=bdg_df1[0]
repo_df['操作金额']=repo_df['操作金额'].str.split(",",expand=False).fillna("")
#清洗操作期限列,替换完成后拼合成字符串存放在单元格1中,然后再重新展开成列表
bdg_df2=repo_df['操作期限']
bdg_df2=bdg_df2.str.replace("天","").str.replace("\[","").str.replace("\]","").str.replace("\'","").str.split(",",expand=True)
print(bdg_df2[1490:1510])
bdg_df2[0]=bdg_df2[0].str.cat(bdg_df2[1].fillna(""),",").str.cat(bdg_df2[2].fillna(""),",").str.cat(bdg_df2[3].fillna(""),",").str.cat(bdg_df2[4].fillna(""),",").str.rstrip(",")
bdg_df2[0]=bdg_df2[0].str.replace("\ , ","").str.rstrip(",").str.replace(" ","")
# write_df_save_close(bdg_df2,dest_filename='repo_test.xlsx',write=True,name="test_df")
repo_df['操作期限']=bdg_df2[0]
repo_df['操作期限']=repo_df['操作期限'].str.replace("1个月","30")
repo_df['操作期限']=repo_df['操作期限'].str.split(",",expand=False).fillna("")
#清洗操作价格列,替换完成后拼合成字符串存放在单元格1中,然后再重新展开成列表
bdg_df3=repo_df['操作价格']
bdg_df3=bdg_df3.str.replace("%","").str.replace("\[","").str.replace("\]","").str.replace("\'","").str.split(",",expand=True)
bdg_df3[0]=bdg_df3[0].str.cat(bdg_df3[1].fillna(""),",").str.cat(bdg_df3[2].fillna(""),",").str.cat(bdg_df3[3].fillna(""),",").str.rstrip(",")
bdg_df3[0]=bdg_df3[0].str.replace("\ , ","").str.rstrip(",").str.replace(" ","")
# write_df_save_close(bdg_df,dest_filename='repo_test.xlsx',write=True,name="test_df")
repo_df['操作价格']=bdg_df3[0]
repo_df['操作价格']=repo_df['操作价格'].str.split(",",expand=False).fillna("")
repo_df=explode1(repo_df,'操作金额','操作价格','操作期限')
write_df_save_close(repo_df,dest_filename='REPO_BALANCE.xlsx',write=True,name="repo_df")
2.3 拼接根据操作期限生成的现金流数据框
下面处理MLF的数据。由于MLF的操作期限有6个月和1年,我用了一个字典把操作期限转为具体的操作天数,6个月姑且按照182天来处理。
把mlf数据框的日期索引先转成列表,再把列表内的单个日期用pd.to_datetime转成日期对象。这样,接下来才能通过这日期索引的信息,循环生成临时的日期区间。
对生成后的现金流数据框所有列进行加总,然后保存成本地的csv格式。避免后续每次都得重新处理原始数据,才能生成图表。
temp_index_mlf=pd.to_datetime(mlf_df.index.to_list())
dict={"1个月":30,"2个月":30,"3个月":91,"6个月":182,"1年":360,"2年":720,"3年":1080}
days_list_mlf=mlf_df['操作期限'].apply(lambda x:dict[x.replace(" ","")]).to_list()
amount_list_mlf=mlf_df['操作金额'].str.replace("'","").str.replace("亿","").str.replace("元","").str.replace(" ","").astype('float').to_list()
cash_flow_df_mlf=pd.DataFrame()
for row in range(0,len(mlf_df)):
temp_range=pd.date_range(temp_index_mlf[row],temp_index_mlf[row]+timedelta(days=days_list_mlf[row]),closed='left',freq='D')
temp_df=pd.DataFrame(list([amount_list_mlf[row]])*days_list_mlf[row],index=temp_range)
cash_flow_df_mlf=pd.concat([cash_flow_df_mlf,temp_df],axis=1,sort=False)
cash_flow_df_mlf.fillna(0,inplace=True)
cash_flow_df_mlf['Sum_mlf']=cash_flow_df_mlf.sum(axis=1)
cash_flow_df_mlf.to_csv("outstanding_mlf.csv")接下来是读入正逆回购数据,处理的思路跟MLF的类似。但是有一样需要注意的,就是需要根据操作种类信息来确定正逆回购的符号,如果是正回购,意味着央行是从市场上抽走资金,因此操作金额为负值。
temp_index_repo=pd.to_datetime(repo_df.index.to_list())
days_list_repo=repo_df['操作期限'].astype('int').to_list()
repo_df['操作金额']=repo_df['操作金额'].str.replace("'","").str.replace("亿","").str.replace("元","").str.replace(" ","").astype('float')
repo_df['操作金额']=repo_df['操作金额'].mask(~repo_df['操作种类'].str.contains("逆回购"),(-1)*repo_df['操作金额'])
amount_list_repo=repo_df['操作金额'].replace("'","").replace("亿","").replace("元","").replace(" ","").astype('float').to_list()
cash_flow_df_repo=pd.DataFrame()
for row in range(0,len(repo_df)):
temp_range=pd.date_range(temp_index_repo[row],temp_index_repo[row]+timedelta(days=days_list_repo[row]),closed='left',freq='D')
temp_df=pd.DataFrame(list([amount_list_repo[row]])*days_list_repo[row],index=temp_range)
cash_flow_df_repo=pd.concat([cash_flow_df_repo,temp_df],axis=1,sort=False)
cash_flow_df_repo.fillna(0,inplace=True)
cash_flow_df_repo['Sum']=cash_flow_df_repo.sum(axis=1)
cash_flow_df_repo.to_csv("outstanding_repo.csv")2.4 Matplotlib画图
画一个简单的公开市场操作存量图,由于需要设置时间轴的间隔,因此需要导入MonthLocator,通过调整里面的interval来设置想要的间隔。
%matplotlib qt5
from matplotlib.dates import MonthLocator,YearLocator
cash_flow_df_repo=pd.read_csv("outstanding_repo.csv",index_col='Unnamed: 0',parse_dates=True).fillna("").loc["2017-01-01":"2022-07-19",:]
cash_flow_df_mlf=pd.read_csv("outstanding_mlf.csv",index_col='Unnamed: 0',parse_dates=True).fillna("")
fig,ax=plt.subplots(figsize=(20,15))
ax.set_title('PBOC OMO Outstanding Balance') #要求画图时显示图表名称
ax.grid(which='both',axis='both') #显示水平、垂直的主副网格线
ax.yaxis.set_major_locator(MultipleLocator(3000))
ax.set_xticks(cash_flow_df_repo.index) #把回购的日期索引,设为x轴时间刻度
ax.xaxis.set_tick_params(rotation=70,labelsize=10,colors='blue')
ax.xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d'))
month=MonthLocator(interval=3)
ax.xaxis.set_major_locator(month) #时间轴的主刻度间隔设为3个月
ax.legend(loc='best',labels=['MLF','REPO'])
plt.axhline(0,color='black')
ax.plot(cash_flow_df_mlf['Sum_mlf'],c='c',alpha=0.8)
ax.plot(cash_flow_df_repo['Sum'],c='cornflowerblue',alpha=0.8,marker='o',lw=3.5,mfc='blue',ms=1,ls="dashdot",)
cash_sum=pd.concat([cash_flow_df_repo['Sum'],cash_flow_df_mlf['Sum_mlf']],axis=1,sort=False)
cash_sum.fillna(0,inplace=True)
cash_sum['Total']=cash_sum.sum(axis=1)
ax.bar(cash_sum.index,cash_sum['Total'],color='lightpink',alpha=0.5)
cursor1 = Cursor(ax, useblit=True, color='red', linewidth=1)
plt.show()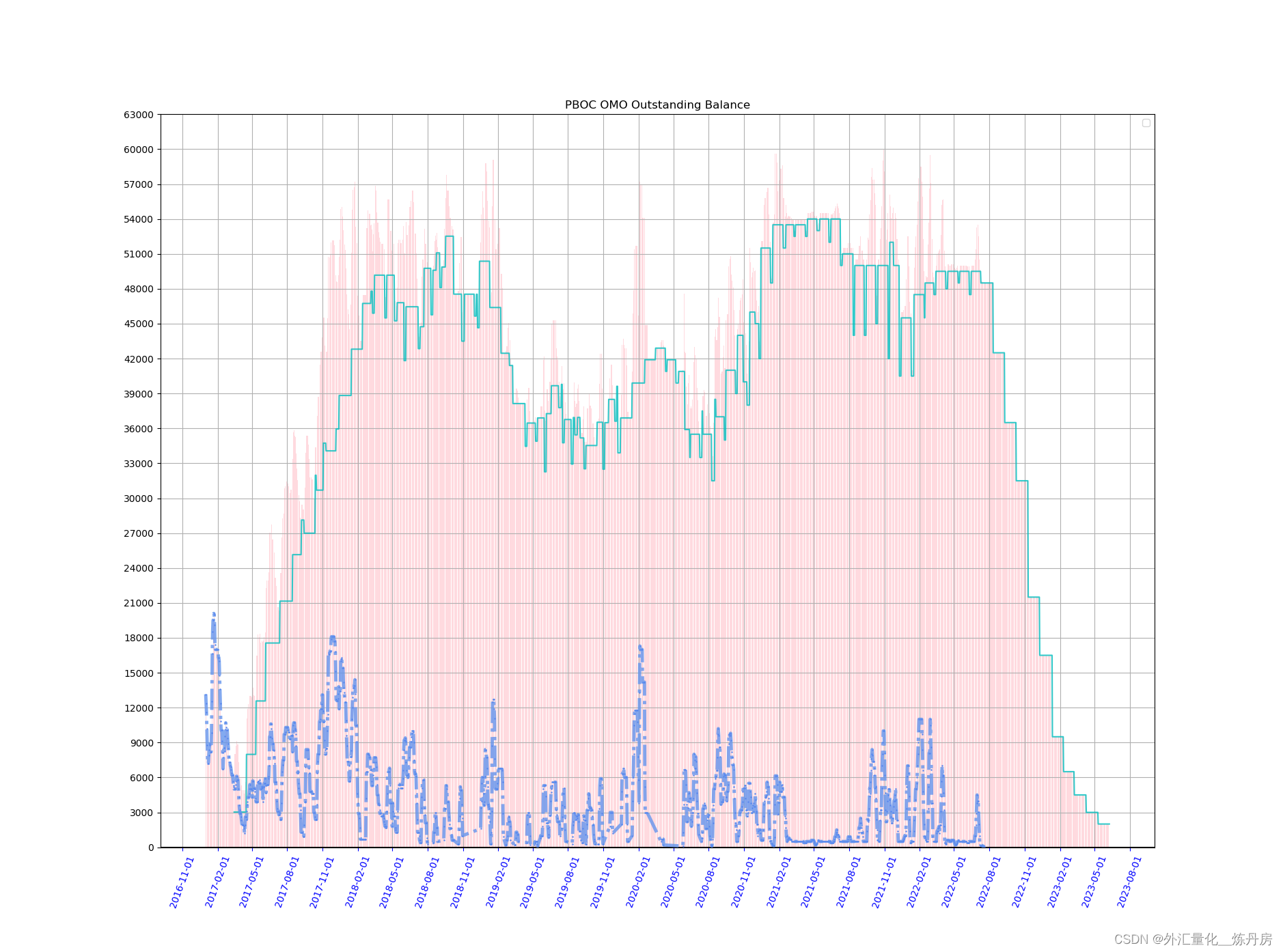
加入下列代码,可以显示不同MLF的存量余额数值。
ind=cash_flow_df_mlf.index
for i in range(0,len(cash_flow_df_mlf['Sum_mlf']),30):
plt.text(ind[i],cash_flow_df_mlf['Sum_mlf'][i],cash_flow_df_mlf['Sum_mlf'][i],ha='center',fontsize=7)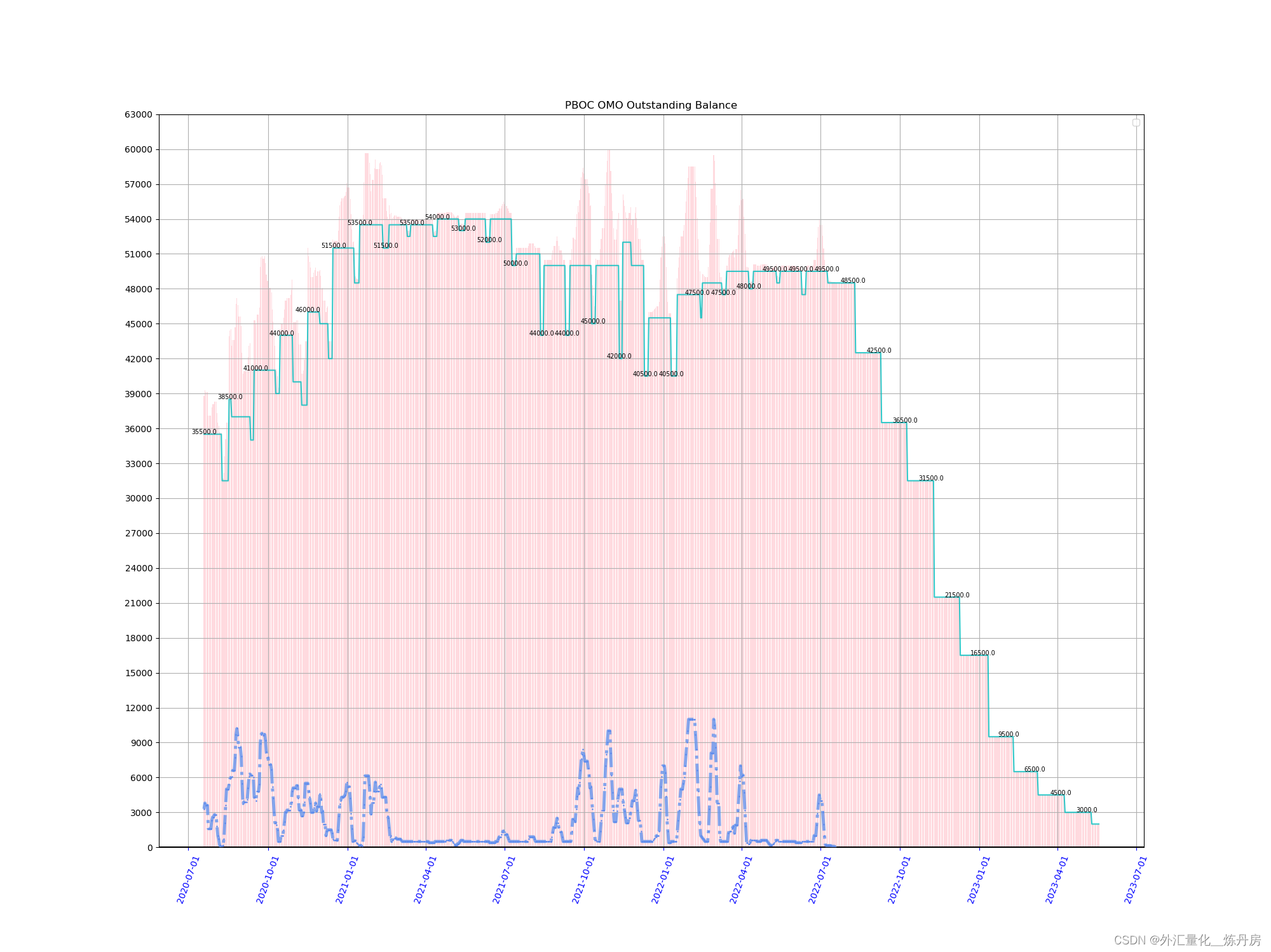
轻轻瞄一眼由这张图,心里就会对接下来的MLF到期情况了然于胸,再也不用依赖资讯系统,财经博主的提醒。
7月的MLF存量仍有4.85万亿,年底如果央行不续做,则MLF存量就会降至2万亿左右,除非通过降准补充流动性,否则流动性缺口还是足够市场吃一壶的。当然根据此前MLF的续作情况,这种事情大概率不会发生。这背后的逻辑就看每个人对总体流动性的进一步分析和把握了。
但是至少这块数据的拼图我们已经拿下来了,后面有时间再做进一步的优化和分析吧。


















 419
419

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











