






本章内容
数学和统计函数
字符处理函数
循环和条件执行
自编函数
数据整合与重塑
5.2 数值和字符处理函数
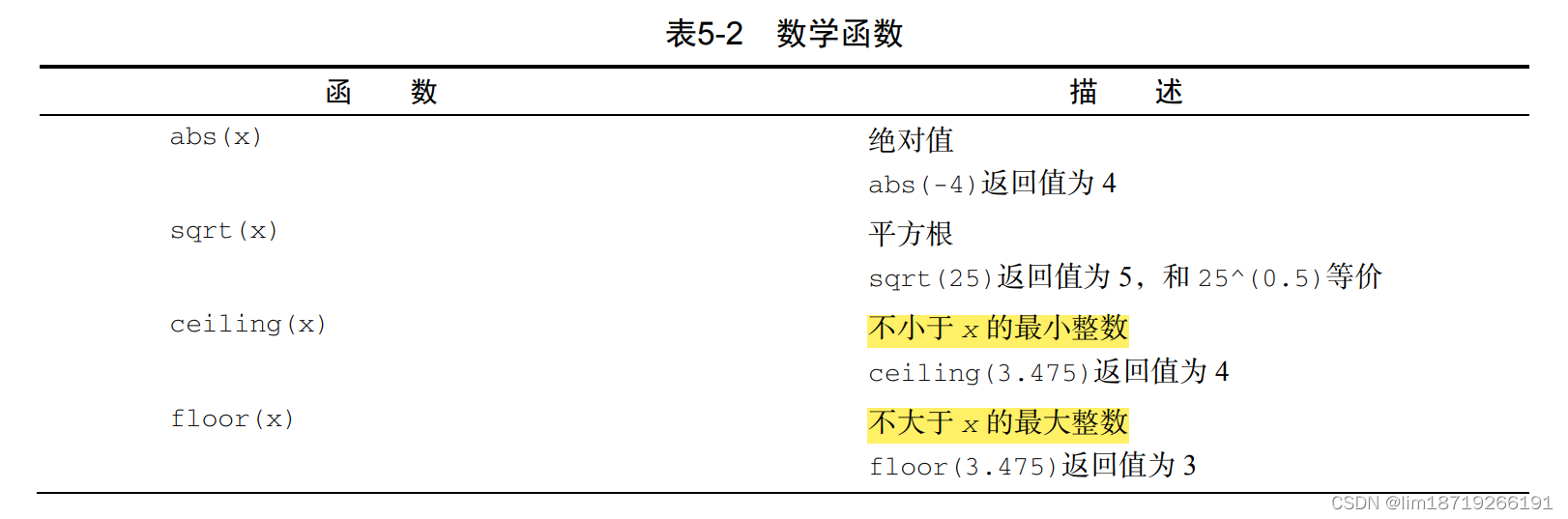

5.2.2 统计函数

css <- sum((x - meanx)^2)数据标准化
默认情况下,函数scale()对矩阵或数据框的指定列进行均值为0、标准差为1的标准化:
newdata <- scale(mydata)要对每一列进行任意均值和标准差的标准化,可以使用如下的代码:
newdata <- scale(mydata)*SD + M其中的M是想要的均值,SD为想要的标准差。
要对指定列而不是整个矩阵或数据框进行标准化,你可以使用这样的代码:
newdata <- transform(mydata, myvar = scale(myvar)*10+50)此句将变量myvar标准化为均值50、标准差为10的变量。
5.2.3 概率函数
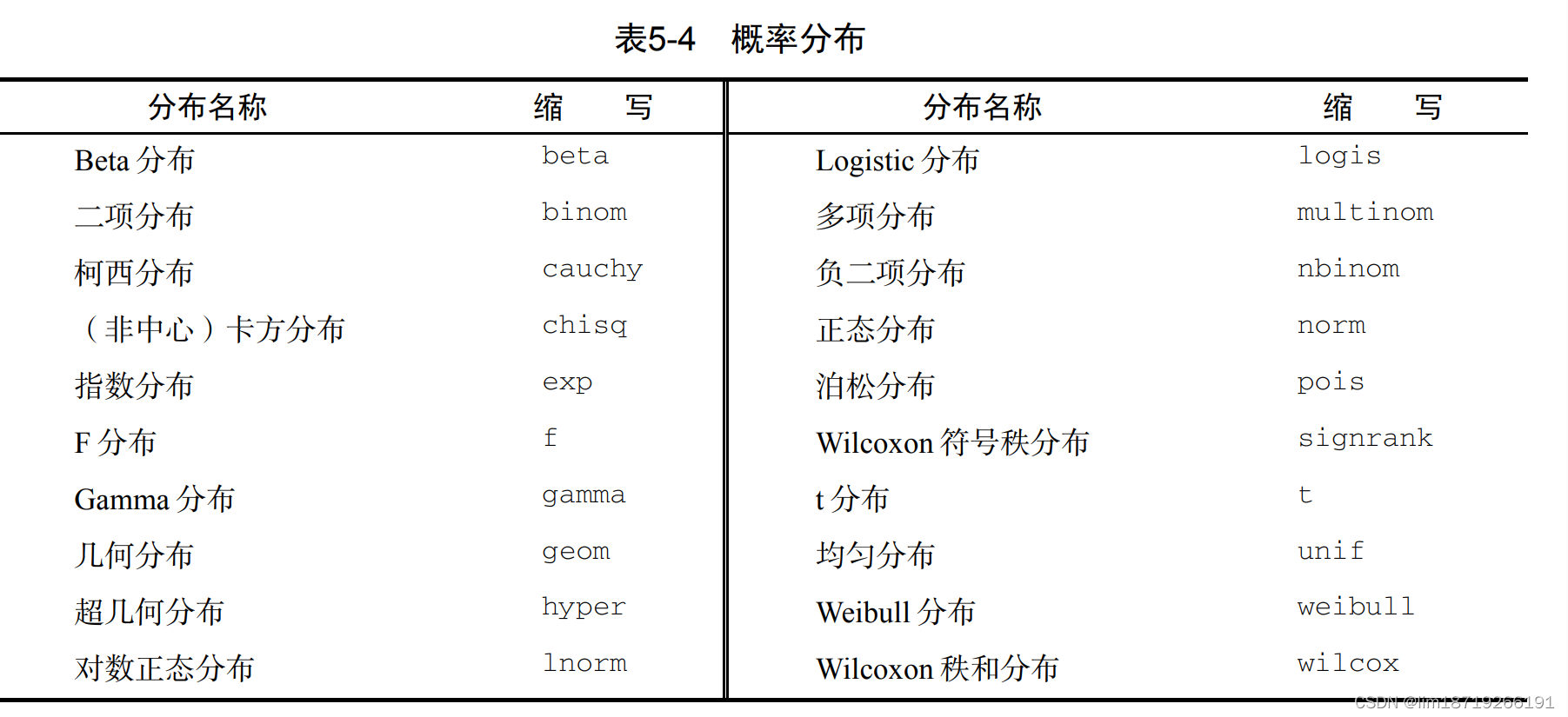
1. 设定随机数种子
在每次生成伪随机数的时候,函数都会使用一个不同的种子,因此也会产生不同的结果。你 可以通过函数set.seed()显式指定这个种子,让结果可以重现(reproducible)。代码清单5-2给 出了一个示例。这里的函数runif()用来生成0到1区间上服从均匀分布的伪随机数。
通过手动设定种子,就可以重现你的结果了。这种能力有助于我们创建会在未来取用的,以 及可与他人分享的示例。
例子
> runif(5)
[1] 0.8725344 0.3962501 0.6826534 0.3667821 0.9255909
> runif(5)
[1] 0.4273903 0.2641101 0.3550058 0.3233044 0.6584988
> set.seed(1234)
> runif(5)
[1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154
> set.seed(1234)
> runif(5)
[1] 0.1137034 0.6222994 0.6092747 0.6233794 0.8609154 2. 生成多元正态数据
mvrnorm(n, mean, sigma)其中n是你想要的样本大小,mean为均值向量,而sigma是方差协方差矩阵(或相关矩阵)。
从一个参数如下所示的三元正态分布中抽取500个观测

> library(MASS)
> options(digits=3)
> set.seed(1234)
> mean <- c(230.7, 146.7, 3.6)
> sigma <- matrix(c(15360.8, 6721.2, -47.1,
6721.2, 4700.9, -16.5,
-47.1, -16.5, 0.3), nrow=3, ncol=3)
> mydata <- mvrnorm(500, mean, sigma)
> mydata <- as.data.frame(mydata)
#为了处理方便,将矩阵换成了数据框
> names(mydata) <- c("y","x1","x2")
> dim(mydata)
[1] 500 3
> head(mydata, n=10)
y x1 x2
1 98.8 41.3 4.35
2 244.5 205.2 3.57
3 375.7 186.7 3.69
4 -59.2 11.2 4.23
5 313.0 111.0 2.91
6 288.8 185.1 4.18
7 134.8 165.0 3.68
8 171.7 97.4 3.81
9 167.3 101.0 4.01
10 121.1 94.5 3.76注意大小写!!MASS与mass不一样
5.2.4 字符处理函数

正则表达式:
请注意,函数grep()、sub()和strsplit()能够:
搜索某个文本字符串(fixed=TRUE)
或
某个正则表达式(fixed=FALSE,默认值为FALSE)。
5.2.5 其他实用的函数

转义字符:
\n表示新行,\t为制表符,\' 为单引号,\b为退格
键入?Quotes以了解更多
name <- "Bob"
cat( "Hello", name, "\b.\n", "Isn\'t R", "\t", "GREAT?\n") 
换行之后还退了一格,是通过\b.\n做到的
5.2.6 将函数用于矩阵和数据框 apply()
例子:将函数应用于数据对象
> a <- 5
> sqrt(a)
[1] 2.236068
> b <- c(1.243, 5.654, 2.99)
> round(b)
[1] 1 6 3
> c <- matrix(runif(12), nrow=3)
> c
[,1] [,2] [,3] [,4]
[1,] 0.4205 0.355 0.699 0.323
[2,] 0.0270 0.601 0.181 0.926
[3,] 0.6682 0.319 0.599 0.215
> log(c)
[,1] [,2] [,3] [,4]
[1,] -0.866 -1.036 -0.358 -1.130
[2,] -3.614 -0.508 -1.711 -0.077
[3,] -0.403 -1.144 -0.513 -1.538
> mean(c)
[1] 0.444函数mean()求得的是 矩阵中全部12个元素的均值。
但如果希望求的是各行的均值或各列的均值呢? R中提供了一个apply()函数,可将一个任意函数“应用”到矩阵、数组、数据框的任何维 度上。
apply()函数的使用格式为:
apply(x, MARGIN, FUN, ...)x为数据对象,MARGIN是维度的下标,FUN是由你指定的函数,而...则包括了任何想传 递给FUN的参数。
在矩阵或数据框中,MARGIN=1表示行,MARGIN=2表示列。
> mydata <- matrix(rnorm(30), nrow=6)
> mydata
[,1] [,2] [,3] [,4] [,5]
[1,] 0.71298 1.368 -0.8320 -1.234 -0.790
[2,] -0.15096 -1.149 -1.0001 -0.725 0.506
[3,] -1.77770 0.519 -0.6675 0.721 -1.350
[4,] -0.00132 -0.308 0.9117 -1.391 1.558
[5,] -0.00543 0.378 -0.0906 -1.485 -0.350
[6,] -0.52178 -0.539 -1.7347 2.050 1.569
#每行的均值
> apply(mydata, 1, mean)
[1] -0.155 -0.504 -0.511 0.154 -0.310 0.165
#每列的均值
> apply(mydata, 2, mean)
[1] -0.2907 0.0449 -0.5688 -0.3442 0.1906
# 每行的截尾均值(在本例中,截尾均值基于中间60%的数据,最高和最低20%的值均被忽略)
> apply(mydata, 2, mean, trim=0.2)
[1] -0.1699 0.0127 -0.6475 -0.6575 0.2312 FUN可为任意R函数,这也包括你自行编写的函数(参见5.4节),所以apply()是一种很强 大的机制。
apply()可把函数应用到数组的某个维度上,
lapply()和sapply()则可将函数 应用到列表(list)上。
5.3 数据处理难题的一套解决方案
options(digits=2)
Student <- c("John Davis", "Angela Williams", "Bullwinkle Moose",
"David Jones", "Janice Markhammer", "Cheryl Cushing",
"Reuven Ytzrhak", "Greg Knox", "Joel England",
"Mary Rayburn")
Math <- c(502, 600, 412, 358, 495, 512, 410, 625, 573, 522)
Science <- c(95, 99, 80, 82, 75, 85, 80, 95, 89, 86)
English <- c(25, 22, 18, 15, 20, 28, 15, 30, 27, 18)
roster <- data.frame(Student, Math, Science, English,
stringsAsFactors=FALSE)
roster
z<-scale(roster[,2:4]) #取了roster的2-4列做标准化
z
score<-apply(z,1,mean) #再对标准化后的行做平均
score
roster<-cbind(roster,score)
roster# 计算综合得分
y<-quantile(score,c(.8,.6,.4,.2)) # 取score的百分比
y #score的百分比
roster$grade[score >=y[1]] <-"A"
roster$grade[score < y[1] & score >= y[2]] <- "B"
roster$grade[score < y[2] & score >= y[3]] <- "C"
roster$grade[score < y[3] & score >= y[4]] <- "D"
roster$grade[score < y[4]] <- "F"
#抽取姓氏和名字
name<-strsplit((roster$Student),"")
Lastname <- sapply(name, "[", 2)
Firstname <- sapply(name, "[", 1)
roster <- cbind(Firstname,Lastname, roster[,-1])
# 根据姓氏和名字排序
roster <- roster[order(Lastname,Firstname),]
roster- 函数quantile()给出了学生综合得分的百分位数。可以看到,成绩为A的分界点为 0.74,B的分界点为0.44,等等。
- 通过使用逻辑运算符,你可以将学生的百分位数排名重编码为一个新的类别型成绩 变量。下面在数据框roster中创建了变量grade。
你将使用函数strsplit()以空格为界把学生姓名拆分为姓氏和名字。把 strsplit()应用到一个字符串组成的向量上会返回一个列表:
- 你可以使用函数sapply()提取列表中每个成分的第一个元素,放入一个储存名字 的向量Firstname,并提取每个成分的第二个元素,放入一个储存姓氏的向量Lastname。
- 你将使用cbind()把它们添加到花名册中。由于已经不再需要student变量,可以将其丢弃:(在下标中使用–1)。
5.4 控制流
概念:
语句(statement)是一条单独的R语句或一组复合语句(包含在花括号{ }中的一组R 语句,使用分号分隔);
条件(cond)是一条最终被解析为真(TRUE)或假(FALSE)的表达式;
表达式(expr)是一条数值或字符串的求值语句;
序列(seq)是一个数值或字符串序列。
5.4.1 重复和循环
1. for结构
for循环重复地执行一个语句,直到某个变量的值不再包含在序列seq中为止。
语法为: for (var in seq) statement
2. while结构
while循环重复地执行一个语句,直到条件不为真为止。
语法为: while (cond) statement
在处理大数据集中的行和列时,R中的循环可能比较低效费时。只要可能,最好联用R中的 内建数值/字符处理函数和apply族函数。
5.4.2 条件执行
1. if-else结构
控制结构if-else在某个给定条件为真时执行语句。也可以同时在条件为假时执行另外的语 句。
语法为:
if (cond) statement
if (cond) statement1 else statement2
2. ifelse结构
ifelse结构是if-else结构比较紧凑的向量化版本,其语法为: ifelse(cond, statement1, statement2)
3. switch结构
switch根据一个表达式的值选择语句执行。语法为: switch(expr, ...) 其中的...表示与expr的各种可能输出值绑定的语句。
例子:
> feelings <- c("sad", "afraid")
> for (i in feelings)
print(
switch(i,
happy = "I am glad you are happy",
afraid = "There is nothing to fear",
sad = "Cheer up",
angry = "Calm down now"
)
)
[1] "Cheer up"
[1] "There is nothing to fear"5.5 用户自编函数
一个函数的结构看起来大致如此:函数中的对象只在函数内部使用。返回对象的数据类型是任意的,从标量到列表皆可。
myfunction <- function(arg1, arg2, ... ){
statements
return(object)
}一个由用户编写的描述性统计量计算函数:
mystats <- function(x, parametric=TRUE, print=FALSE) {
if (parametric) {
center <- mean(x); spread <- sd(x)
} else {
center <- median(x); spread <- mad(x)
}
if (print & parametric) {
cat("Mean=", center, "\n", "SD=", spread, "\n")
} else if (print & !parametric) {
cat("Median=", center, "\n", "MAD=", spread, "\n")
}
result <- list(center=center, spread=spread)
return(result)
} 例子:
mydate <- function(type="long") {
switch(type,
long = format(Sys.time(), "%A %B %d %Y"),
short = format(Sys.time(), "%m-%d-%y"),
cat(type, "is not a recognized type\n")
)
} 结果:函数cat()仅会在输入的日期格式类型不匹配"long"或"short"时执行。使用一个表达式来捕获用户的错误输入的参数值通常来说是一个好主意。

注意
用来为函数添加错误捕获和纠正功能。你可以使用:
函数warning()来生成一 条错误提示信息,
message()来生成一条诊断信息,
stop()停止当前表达式的执行并提 示错误。
在创建好自己的函数以后,你可能希望在每个会话中都能直接使用它们。附录B描述了如何 定制R环境,以使R启动时自动读取用户编写的函数。我们将在第6章和第8章中看到更多的用户 自编函数示例
5.6 整合与重构
整合:将多组观测替换为根据这些观测计算的描述性统计量
重塑:通过修改数据的 结构(行和列)来决定数据的组织方式。
5.6.1 转置:t()
使用函数t()即可 对一个矩阵或数据框进行转置。对于后者,行名将成为变量(列)名。
5.6.2 整合数据:aggregate(x, by, FUN)
其中x是待折叠的数据对象,by是一个变量名组成的列表,这些变量将被去掉以形成新的观测, 而FUN则是用来计算描述性统计量的标量函数,它将被用来计算新观测中的值。
在R中使用一个或多个by变量和一个预先定义好的函数来折叠(collapse)数据
例子:将车子的数据按cyl和gear聚合,计算均值
options(digitals=3)
attach(mtcars)
aggdata<-aggregate(mtcars,by=list(cyl,gear),FUN=mean,na.rm=TRUE)
aggdata5.6.3 reshape2包 (更高级的)
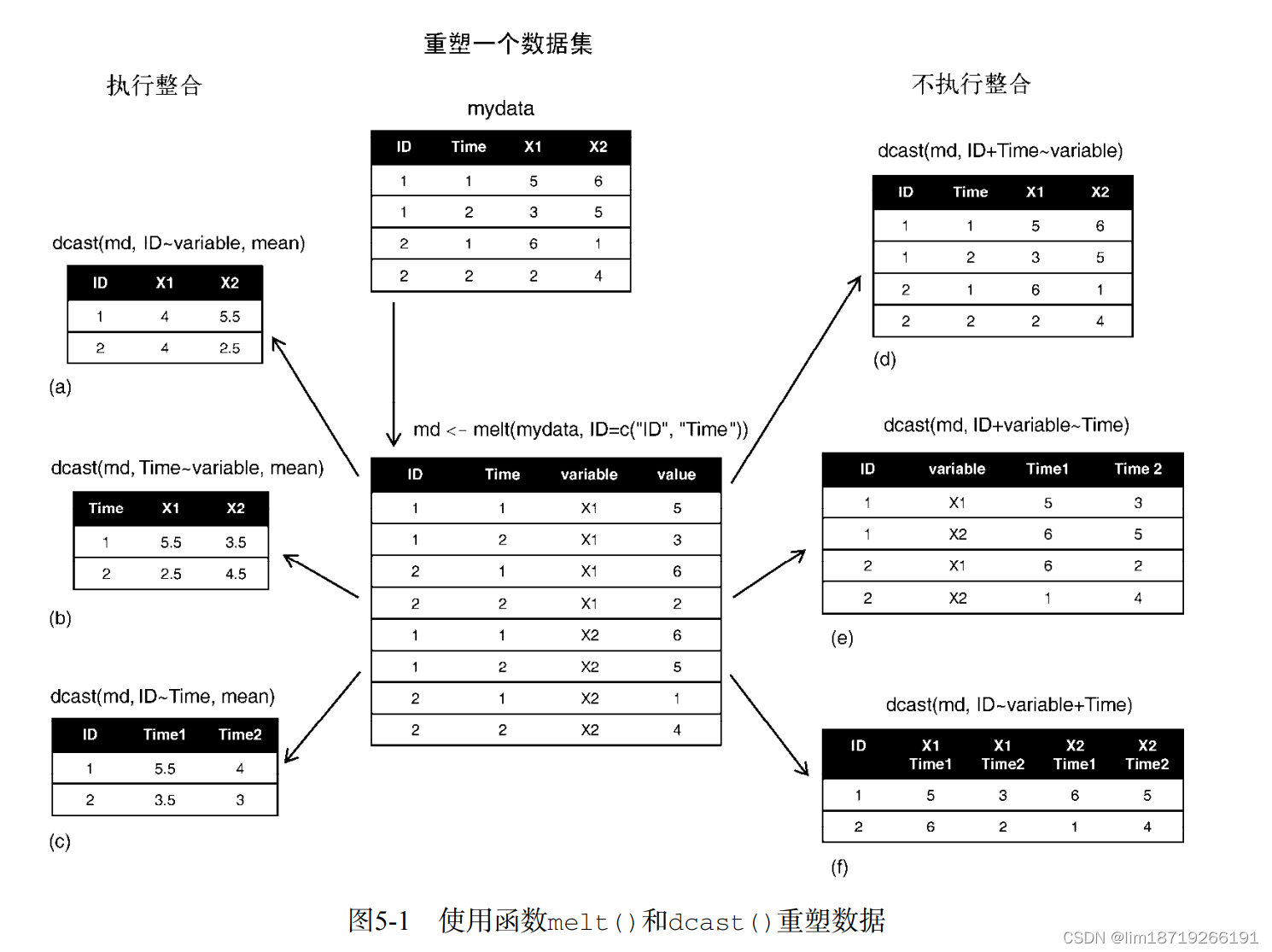
大致说来,你需要首先将数据融合(melt),以使每一行都是唯一的标识符变量组合。然后 将数据重铸(cast)为你想要的任何形状。在重铸过程中,你可以使用任何函数对数据进行整合。
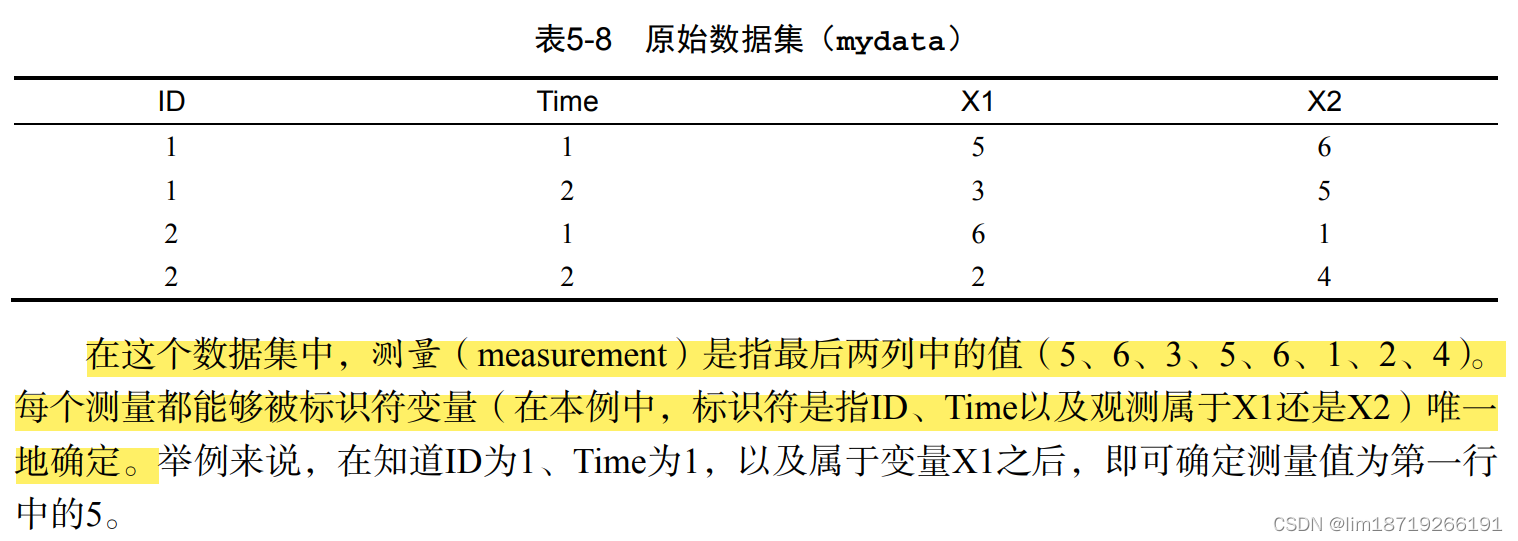
1.融合:melt()将它重构为这样一种格式:每个测量变量独占一行,行中带有要唯一确定这 个测量所需的标识符变量
library(reshape2)
md <- melt(mydata, id=c("ID", "Time"))注意,必须指定要唯一确定每个测量所需的变量(ID和Time),而表示测量变量名的变量(X1 或X2)将由程序为你自动创建。
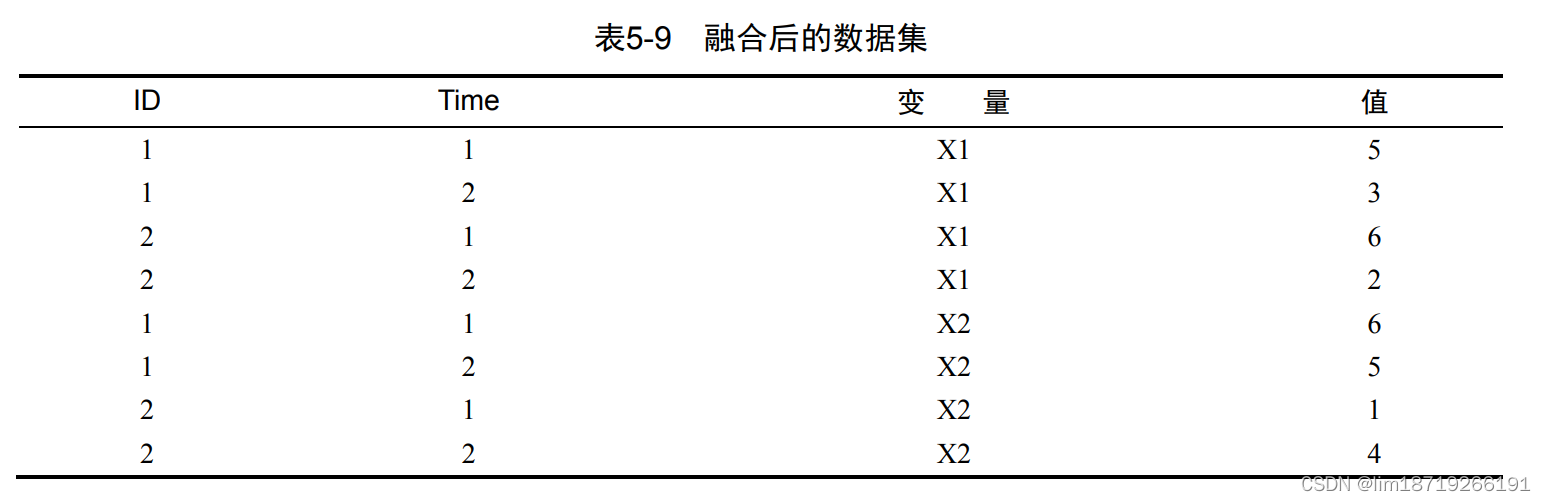
2. 重铸:dcast():读取已融合的数据,并使用你提供的公式和一个(可选的)用于整合数据的函 数将其重塑。
newdata <- dcast(md, formula, fun.aggregate) 其中的md为已融合的数据,formula描述了想要的最后结果,而fun.aggregate是(可选 的)数据整合函数。

结果:
- 由于右侧(d、e和f)的公式中并未包括某个函数,所以数据仅被重塑了
- 反之,左侧的示例(a、b和c)中指定了mean作为整合函数,从而就对数据同时进行了重塑与整合。
- 例如,示例 (a)中给出了每个观测所有时刻中在X1和X2上的均值;
- 示例(b)则给出了X1和X2在时刻1和时刻2 的均值,对不同的观测进行了平均;
- 在(c)中则是每个观测在时刻1和时刻2的均值,对不同的X1 和X2进行了平均。
















 3479
3479











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









