







遗传规划(Genetic Programming,GP)
其他的进化算法(如GA)是将的单个结构(参数)定义为一个串(二进制串或实数串),但GP是将计算机程序以树结构表示,从而进行处理,每个染色体代表一个程序(树结构)。此外,其他进化算法的个体结构都是固定长度的,但通过GP进化的程序在大小、形状和复杂度上都是不同的。
GP可以看做是遗传算法GA在执行程序进化时的特例,但它和一般的GA算法的不同之处在于:
- 执行结构(程序)的成员不再是字符串或实数变量;
- GP的每个种群个体的适应度是通过执行它来测定的;
- 对于具体问题需要定义相应的语法。
用GP进化程序的目的是在给定输入的情况下对潜在的程序空间进行搜索,从而获得一个渴望得到的输出(即实现计算机的自动编程)。在GP中,每个程序都由一个解析树构成,其中,树的内部节点(根节点及非叶节点)是与问题相关的函数运算,树的外部节点(叶子节点)是变量和相关常数,因此,生成的计算机程序使得遗传规划具有等级性。
例如,
y
:
=
x
⋅
l
n
(
a
)
+
s
i
n
(
z
)
/
e
−
x
−
3.4
y:=x\cdot ln(a)+sin(z)/e^{-x}-3.4
y:=x⋅ln(a)+sin(z)/e−x−3.4 的树结构表达:
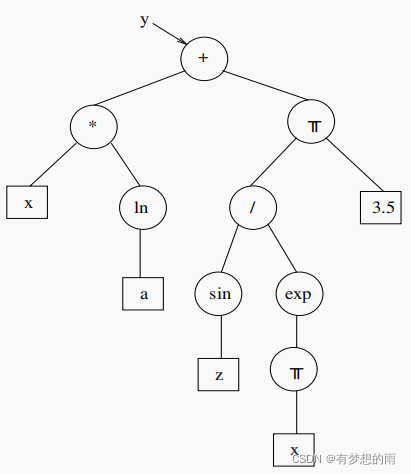
GP的准备
-
指定终端集(与问题或系统相关的变量或常数);
-
指定函数集(数学运算 [ + , − , ∗ ; e t c ] [+,-,*;etc] [+,−,∗;etc] / 数学函数 [ c o s , e x p ; e t c ] [cos,exp;etc] [cos,exp;etc] / 布尔运算 [ a n d , n o t ; e t c ] [and,not;etc] [and,not;etc] / 条件运算[if-then-else] / 迭代 / 递归等):
函数集中的每个函数需要固定的参数数量,指定函数集的任务之一就是选择最小的能够完成任务的集合。在GP的应用中,终端集和函数集需要具备两个属性:封闭性和充分性,其目的在于使得终止集中的任意类型任意值的成员都能在函数集中的每个函数都能成功执行。
封闭性:对于函数运算,有一些特殊情况需要定义(eg,一个数除0可以将其定义为一个常数;若对于条件操作返回的布尔值是不可接受的,则可以考虑将其重新定义为:(1)将布尔值(F或T)定义为0或1;(2)条件分支和条件比较运算符可以定义为根据涉及外部状态或条件的测试的评估或根据比较测试结果执行它们的一个参数)。
-
指定适应度度量方法:适应度值和程序输出产生的误差成反比;或者是例如程序在一个游戏中获得的分数。
-
选择参数控制系统;主要的控制参数是种群大小和最大迭代次数,其他的参数包括复制率、交叉率以及初始/最终程序允许的最大规模等。
-
指定终止条件:由最大迭代次数决定。最终程序为所有迭代中产生的最佳程序。
GP的执行
1. 程序初始化:
一般是从包含函数和终端的选定集合中随机初始化程序:即指定一个树的根节点,然后从函数集和终端集中随机选择来生成初始化程序。除了最大深度和层次级别数量外,对程序的大小或形状没有限制。每个程序的根节点是从函数集中随机选择,然后可根据两种方法来建立整个程序树:深度优先策略和广度优先策略。
深度优先方法中,从根节点出发沿着一个分支线从函数集和终止集的组合集中随机选择,依次放置在根函数的末尾;若选择的是函数,则返回到组合集中再次选择;若选择的是终端,则建立一个树的叶节点,这样沿着这条线的程序就被确定终止了。使用深度优先方法时,程序树的构造由函数数目和终端数目之比所支配,比值越大,平均每个树枝的深度就越大。
广度优先方法中,程序树的每个分支都延伸到最大深度,在树的每条分支中,只选择函数,直到达到最大深度,再选择终端。因此,使用广度优先方法生成的程序都有着相同结构。
混合法(Ramped half-and-half approach):使用混合法可以解决除了布尔函数之外的所有问题,生成各种尺度和形状的程序种群。该方法生成的程序深度范围为从2到最大深度:eg.若最大深度为5,则深度为2、3、4、5的种群个体数量都为25%,而对每个子种群,一半使用深度优先生成,一半使用广度优先生成。
2. 确定每个程序的适应度:
对每个程序运行一定数量的案例,以这些案例的平均值作为该程序的适应度。应当注意的是,对不同代的不同程序,所使用的案例应当自始至终都是不变的。
适应度可以使用不同方法计算,可用四种适应度矩阵描述:
(1)原始矩阵:
(2)标准化矩阵:使用标准适应度值可以得到更低的值。实际上,经过数学调整,对最小化问题,最优适应度值被设置为0;对最大化问题,标准适应度值是最大适应度值减去原始适应度值。
(3)调整矩阵:由标准适应度值计算得到:
f
a
=
1
/
(
1
−
f
s
)
f_a=1/(1-f_s)
fa=1/(1−fs),其中
f
s
f_s
fs是标准适应度值,
f
a
∈
[
0
,
1
]
f_a\in[0,1]
fa∈[0,1],1是最优值。使用调整适应度的原因是:在最优值附近,标准适应度值的微小变化对调整适应度的影响远大于离最优值远的地方,即标准适应度值起到一个空间范围缩放的作用。
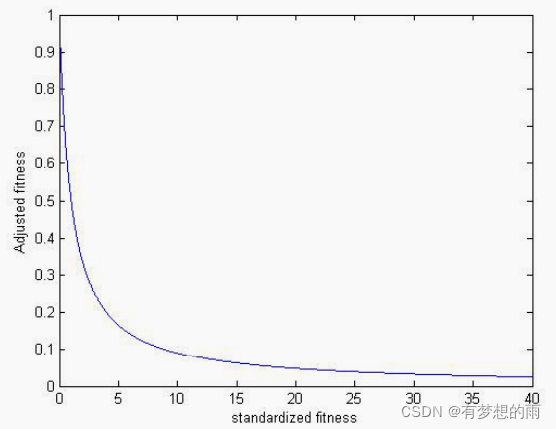
(4)正则化矩阵: 调 整 适 应 度 值 / ∑ 调 整 适 应 度 值 \displaystyle{调整适应度值}\,/\,{\sum调整适应度值} 调整适应度值/∑调整适应度值
3. 根据复制率和适应度值进行复制;
4. 子代程序的遗传操作(交叉、变异等);
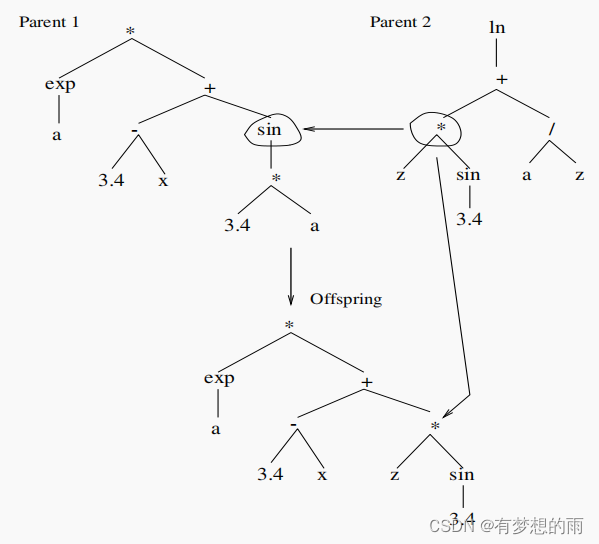
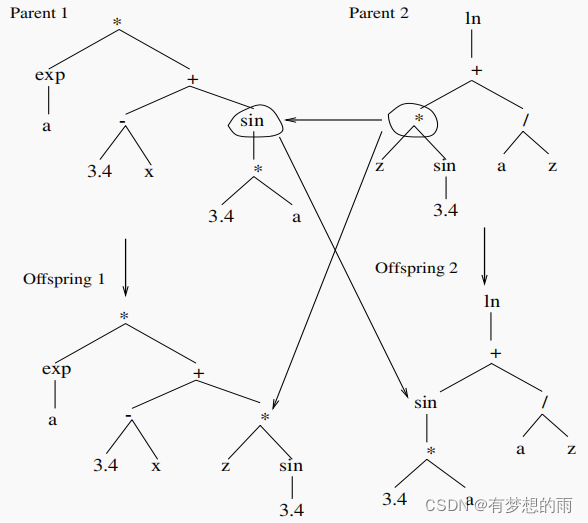
第3步和第4步大多并行执行。复制率与交叉率之和应当为1。当计算出适应度后,根据这些概率来选择执行交叉操作或复制操作。当选择复制时,根据适应度值(正则化适应度值)的轮盘赌法来确定候选程序;当选择交叉时,先使用正则化适应度值选择两个父代,然后随机从两个父代中选择一点作为交叉点(包括根节点和叶节点),整个子程序由两个父代在交叉点交换后得到。若交叉后程序超出了定义的最大深度,则由未更改的程序交叉点之下的部分来替代其他程序交叉点之下的部分。
生成一个子代:
生成两个子代:
变异操作:
GP中变异通常只适用于特殊的应用,但许多GP中的变异操作子大多适用于更一般的GP表达中。利用变异率
p
m
p_m
pm来选择待变异个体,而利用概率
p
n
p_n
pn来选择树的待变异节点,
p
n
p_n
pn越大,个体内部的基因块就越有可能被改变;
p
m
p_m
pm越大,则种群中变异个体的数量会越大。假设原始树如下,变异操作子有:
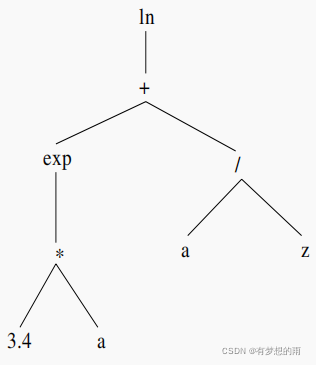
(1)函数节点(非叶节点)变异:随机选择一个非叶节点(函数节点),并从函数集中随机选择一个函数元进行替换,例如:
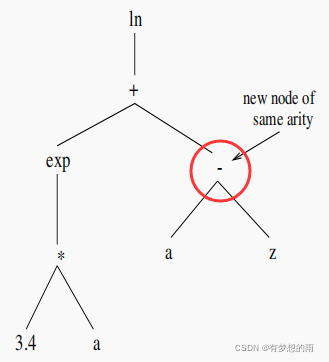
(2)终端节点(叶节点)变异:随机选择一个叶节点(终端节点),并从终端集中随机选择一个终端进行替换,例如:
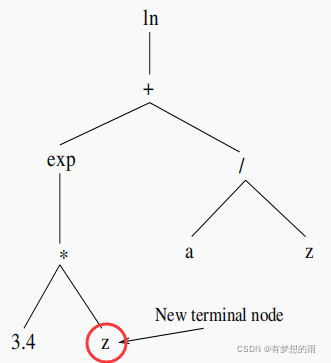
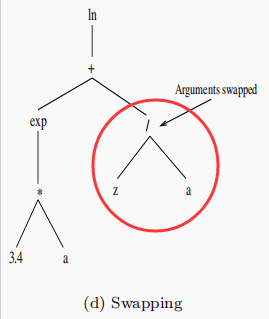
(3)交换变异:随机选择一个函数结点,然后将该节点两侧的进行交换,例如:
(4)增长变异:利用增长变异,选择一个节点,然后用一个随机生成的子树替换,但新生成子树有预先定义的深度限制。例如:
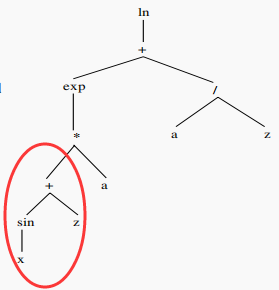
(5)高斯变异:随机选择一个代表常数的叶节点,然后变异(加上一个随机生成的高斯分布常数),例如:
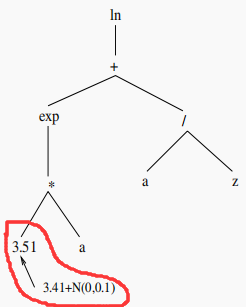
(6)Trunc (剪枝)突变:随机选择一个函数节点(非叶节点),然后用一个随机的终端节点替代。该方法执行的是树结构的剪枝。例如:
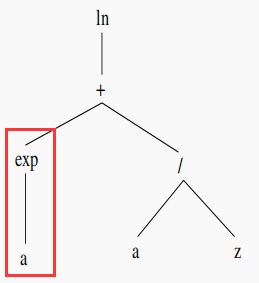

















 255
255

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









