






近期字节跳动开源了一个通过音频驱动人物口型的模型LatentSync,记录一下本地部署的过程。
代码:https://github.com/bytedance/LatentSync
只是用到了inference,没有用到train,所以就只需从https://huggingface.co/chunyu-li/LatentSync下载latentsync_unet.pt 、 tiny.pt这两个模型文件,(setup_env.sh会去下载包括训练在内的所有模型文件)
根据inference.sh设置模型存放路径。
还需依赖其他模型,由于不太喜欢在运行的时候再去下载各种模型,所以提前下载好,并指定位置。(为了简便就直接修改最底层代码了)
有以下3处会去下载模型:
①script/inference.py
下载链接:https://huggingface.co/stabilityai/sd-vae-ft-mse

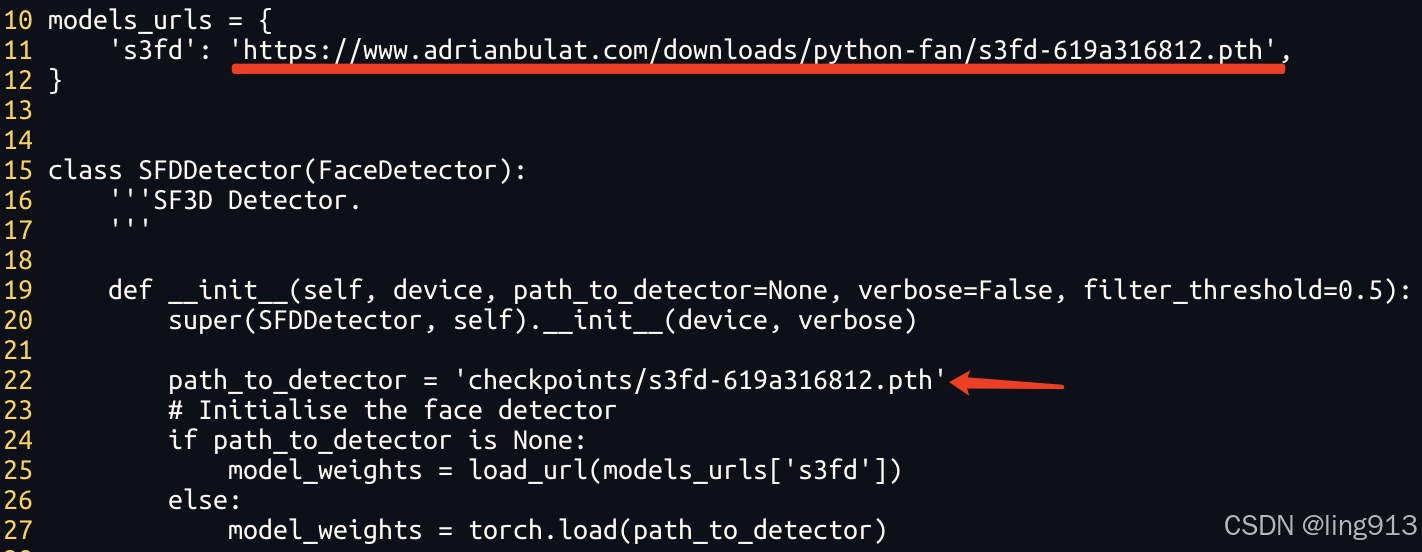
②<your_python_env>/site-packages/face_alignment/detection/sfd/sfd_detector.py
下载链接见下图
③<your_python_env>/site-packages/face_alignment/api.py
下载链接:https://www.adrianbulat.com/downloads/python-fan/2DFAN4-cd938726ad.zip

最后,sh inference.sh
补充:由于开源出来的模型全部是在英文数据集上训练的,经测试在中文上的效果稍有欠缺,要提升在中文上的效果,需要再用中文数据训练。

















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









