






一、解题思路:
回归问题
- 输入:每一个样本对应的485512个位点的甲基化数据与患病情况
- 输出:年龄
特征维数高(485512维)
- 特征选择:覆盖率、相关性、特征重要性
- 直接使用部分特征,后续考虑添加更多特征
模型选择
- 机器学习:效果较稳定
- 深度学习:需填充缺失值、进行数据标准化,尝试搭建各种网络
二、Baseline实践与精读
Baseline使用机器学习方法
1.导入模块
# 导入numpy库,用于进行数值计算
import numpy as np
# 导入pandas库,用于数据处理和分析
import pandas as pd
# 导入polars库,用于处理大规模数据集
import polars as pl
# 导入collections库中的defaultdict和Counter,用于统计
from collections import defaultdict, Counter
# 导入xgboost库,用于梯度提升树模型
import xgb
# 导入lightgbm库,用于梯度提升树模型
import lgb
# 导入CatBoostRegressor库,用于梯度提升树模型
from catboost import CatBoostRegressor
# 导入StratifiedKFold、KFold和GroupKFold,用于交叉验证
from sklearn.model_selection import StratifiedKFold, KFold, GroupKFold
# 导入mean_squared_log_error,用于评估模型性能
from sklearn.metrics import mean_squared_log_error
# 导入sys、os、gc、argparse和warnings库,用于处理命令行参数和警告信息
import sys, os, gc, argparse, warnings
# 忽略警告信息
warnings.filterwarnings('ignore')
2.数据探索(探索数据的结构和规律)
先验假设:尽量少
手段:作图、制表、方程拟合、计算特征量
目的:更好地进行特征工程、建立模型
① 使用reduce_mem_usage_pl函数转换数据类型,减少内存
def reduce_mem_usage(df, verbose=True):
#数值类型的列进行降级处理
numerics = ['int16', 'int32', 'int64', 'float16', 'float32', 'float64']
#1MB=1024KB=1024*1024B,便于输出初始内存占用信息
start_mem = df.memory_usage().sum() / 1024**2
#遍历每列
for col in df.columns:
col_type = df[col].dtypes # 获取该列的数据类型
if col_type in numerics: # 如果是int或float
#寻找该列数据最值
c_min = df[col].min()
c_max = df[col].max()
#从占用内存最少的类型开始对比,若范围满足要求,则进行转换
#int类型
if str(col_type)[:3] == 'int':
if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max:
df[col] = df[col].astype(np.int8)
elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max:
df[col] = df[col].astype(np.int16)
elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max:
df[col] = df[col].astype(np.int32)
elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max:
df[col] = df[col].astype(np.int64)
#float类型
else:
if c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max:
df[col] = df[col].astype(np.float16)
elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max:
df[col] = df[col].astype(np.float32)
else:
df[col] = df[col].astype(np.float64)
end_mem = df.memory_usage().sum() / 1024**2
#函数参数verbose设置是否显示内存占用变化
if verbose: print('Mem. usage decreased to {:5.2f} Mb ({:.1f}% reduction)'.format(end_mem, 100 * (start_mem - end_mem) / start_mem))
return df② 数据预处理(转置)
③ 保存为pickle文件,减少重复预处理工作
# 读取数据
path = 'ai4bio'
# 可能因为内存问题所导致数据读取困难,可以选择放弃部分特征,仅读取部分行,baseline仅读取前10000行
#根据自己的算力情况,适当读取数据
# traindata.csv、testdata.csv 每列代表一个样本,需转置为每行一个样本
# trainmap.csv、testmap.csv 每行代表一个样本
traindata = pd.read_csv(f'{path}/traindata.csv', nrows=10000)
trainmap = pd.read_csv(f'{path}/trainmap.csv')
testdata = pd.read_csv(f'{path}/ai4bio_testset_final/testdata.csv', nrows=10000)
testmap = pd.read_csv(f'{path}/ai4bio_testset_final/testmap.csv')
# 压缩内存,因时间较长,所以暂时注释掉,按自身情况选择使用
# traindata = reduce_mem_usage(traindata)
# testdata = reduce_mem_usage(testdata)
# 数据预处理
traindata = traindata.set_index('cpgsite') # 设为索引
traindata = traindata.T # 转置后,每行一个样本
traindata = traindata.reset_index() # 重置索引,因为有时候对dataframe做处理后索引可能是乱的
traindata = traindata.rename(columns={'index':'sample_id'}) # 以字典形式赋予索引新的值
traindata.columns = ['sample_id'] + [i for i in range(10000)] # 设置列标签名为0-9999
traindata.to_pickle(f'{path}/traindata.pkl') # 保存为pickle文件
testdata = testdata.set_index('cpgsite')
testdata = testdata.T
testdata = testdata.reset_index()
testdata = testdata.rename(columns={'index':'sample_id'})
testdata.columns = ['sample_id'] + [i for i in range(10000)]
testdata.to_pickle(f'{path}/testdata.pkl')处理前
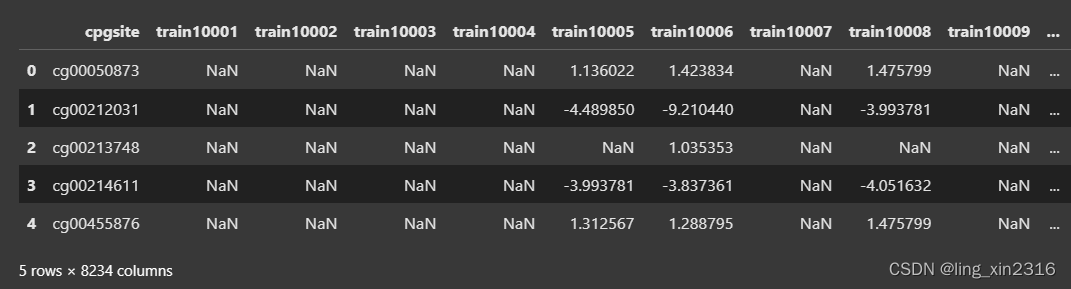
处理后
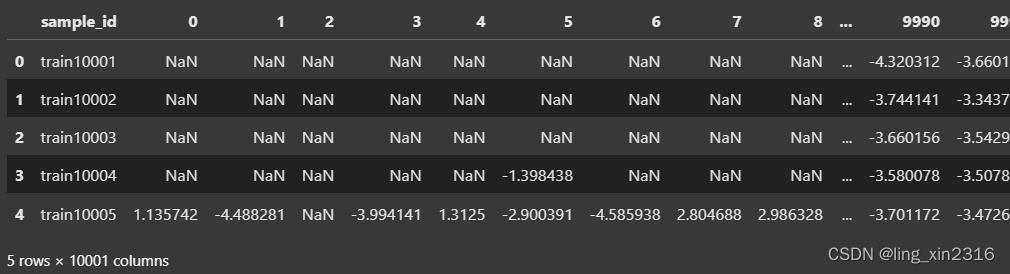
有个疑问:压缩空间时是按列压缩,按理应该是一行为一个样本时,各个特征分开压缩,但traindata和testdata转置前后压缩的结果都相同,是数据范围的原因?还是行列并没有什么影响?

④查看数据特征
- 查看基本信息:trainmap中字符串类型的gender、sample_type、disease需要转换为数值类型
trainmap.head()
traindata.head()
traindata.info()- 查看特征缺失率:部分特征缺失率较高
# 查看前十个特征的缺失率
for i in range(10):
# isnull判断是否为空值(是为1),sum求和,除以总数后即为缺失率
null_cnt = traindata[i].isnull().sum() / traindata.shape[0]
print(f'特征{i},对应的缺失率为{null_cnt}')- DataFrame的corr()查看特征间相关性系数:展示前1000个特征之间的相关性分数,正数正相关,负数负相关
# corr计算列间相关系数矩阵
traindata[[i for i in range(1000)]].corr()3.数据清洗(将脏数据转化为满足数据质量要求的数据)
- 方式:数理统计、数据挖掘、预定义的清理规则
- 流程:缺失值处理、异常值处理、数据分桶、特征归一化/标准化
catboost模型不需要处理缺失值,仅需转换数据类型
# 数据拼接 merge合并data和map
traindata = traindata.merge(trainmap[['sample_id', 'age', 'gender', 'sample_type', 'disease']],on='sample_id',how='left')
testdata = testdata.merge(testmap[['sample_id', 'gender']],on='sample_id',how='left')
# 进行字典映射的方式,将对应字符转换为对应数值
disease_mapping = {
'control': 0,
"Alzheimer's disease": 1,
"Graves' disease": 2,
"Huntington's disease": 3,
"Parkinson's disease": 4,
'rheumatoid arthritis': 5,
'schizophrenia': 6,
"Sjogren's syndrome": 7,
'stroke': 8,
'type 2 diabetes': 9
}
sample_type_mapping = {'control': 0, 'disease tissue': 1}
gender_mapping = {'F': 0, 'M': 1}
#'disease'用disease_mapping字典进行映射
traindata['disease'] = traindata['disease'].map(disease_mapping)
traindata['sample_type'] = traindata['sample_type'].map(sample_type_mapping)
traindata['gender'] = traindata['gender'].map(gender_mapping)
testdata['gender'] = testdata['gender'].map(gender_mapping)4.特征工程(把原始数据转变为模型训练数据)
- 目的:获取更好的训练数据特征,提升模型性能
原始字段特征以连续型数值为主→按行聚合统计→构建常见数值统计特征
traindata['max'] = traindata[[i for i in range(10000)]].max(axis=1) # 最大值
traindata['min'] = traindata[[i for i in range(10000)]].min(axis=1) # 最小值
traindata['std'] = traindata[[i for i in range(10000)]].std(axis=1) #标准差
traindata['var'] = traindata[[i for i in range(10000)]].var(axis=1) # 方差
traindata['skew'] = traindata[[i for i in range(10000)]].skew(axis=1) # 数据偏度
traindata['mean'] = traindata[[i for i in range(10000)]].mean(axis=1) # 均值
traindata['median'] = traindata[[i for i in range(10000)]].median(axis=1) # 中位数
testdata['max'] = testdata[[i for i in range(10000)]].max(axis=1)
testdata['min'] = testdata[[i for i in range(10000)]].min(axis=1)
testdata['std'] = testdata[[i for i in range(10000)]].std(axis=1)
testdata['var'] = testdata[[i for i in range(10000)]].var(axis=1)
testdata['skew'] = testdata[[i for i in range(10000)]].skew(axis=1)
testdata['mean'] = testdata[[i for i in range(10000)]].mean(axis=1)
testdata['median'] = testdata[[i for i in range(10000)]].median(axis=1)
# 入模特征选择
cols = [i for i in range(10000)] + ['gender','max','min','std','var','skew','mean','median']5.模型训练与验证
baseline方案使用catboost模型,K折交叉验证
# 模型训练与验证
def catboost_model(train_x, train_y, test_x, seed = 2023):
folds = 5 # 折数
# 折数为folds,每次进行洗牌,随机结果可复现
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
oof = np.zeros(train_x.shape[0])
test_predict = np.zeros(test_x.shape[0]) # 初始化全零数组,长度与test_x行数相同
cv_scores = [] #空列表用于存储交叉验证得分
# 遍历kf每个折叠
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
# 根据索引获取训练集和验证集的特征和标签
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
# CatBoostRegressor模型的参数设置
params = {'learning_rate': 0.1, # 学习率
'depth': 5, # 树的深度
'bootstrap_type':'Bernoulli', # 对象权重采样方法为伯努利,还有贝叶斯、MVS、泊松等
'random_seed':2023, # 随机数种子
'od_type': 'Iter', # 迭代次数优化方法,通过多次迭代寻找最优的迭代次数。
'od_wait': 100, # 迭代次数优化方法等待时间,较长可以加快收敛速度,但可能导致过拟合
'allow_writing_files': False, # 是否允许写入文件。False不保存参数,返回模型对象。
'task_type':"GPU", # 任务类型,模型运行在GPU还是CPU上
'devices':'0:1' # 设备列表,使用哪些GPU设备。"0:1"只使用第一个GPU设备。}
#根据自己的算力与精力,调整iterations,V100环境iterations=1000需要跑10min
model = CatBoostRegressor(iterations=500, **params)
# 使用训练集和验证集拟合模型
model.fit(trn_x, trn_y, # 训练集的特征和标签,用于训练
eval_set=(val_x, val_y), # 验证集,评估模型性能
metric_period=500, # 每多少次迭代计算一次评估指标
use_best_model=True, # 训练过程中是否使用验证集上性能最好的模型参数
cat_features=[], # 包含需要转换为类别特征的特征名称,没有所以为空列表
verbose=1 # 日志输出的详细程度,1输出详细信息 )
# 使用模型对测试集预测
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)
# 存储验证集预测结果
oof[valid_index] = val_pred
# 计算并累加K折测试集预测结果的平均值
test_predict += test_pred / kf.n_splits
# 暂时忽略健康样本和患病样本在计算MAE上的差异,仅使用常规的MAE指标
score = mean_absolute_error(val_y, val_pred)
# 将MAE添加到cv_scores列表中
cv_scores.append(score)
print(cv_scores)
# 获取特征重要性打分,便于评估特征
if i == 0:
# 将特征名称和打分存储到DataFrame中
fea_ = model.feature_importances_
fea_name = model.feature_names_
fea_score = pd.DataFrame({'fea_name':fea_name, 'score':fea_})
# 按打分降序排列DataFrame
fea_score = fea_score.sort_values('score', ascending=False)
# 将排序后的DataFrame命名为feature_importances.csv保存
fea_score.to_csv('feature_importances.csv', index=False)
return oof, test_predict
# 调用catboost_model函数,进行模型训练与结果预测
cat_oof, cat_test = catboost_model(traindata[cols], traindata['age'], testdata[cols])6.结果输出
# 输出赛题提交格式的结果
testdata['age'] = cat_test # 将testdata数据框中的age列赋值为cat_test
testdata['age'] = testdata['age'].astype(float) # 将数据类型转换为浮点数
testdata['age'] = testdata['age'].apply(lambda x: x if x>0 else 0.0) #小于等于0则替换为0.0
testdata['age'] = testdata['age'].apply(lambda x: '%.2f' % x) # 转换2位小数的浮点数
testdata['age'] = testdata['age'].astype(str) # 转换为字符串
testdata[['sample_id','age']].to_csv('submit.txt',index=False) # sample_id和age保存到submit.txt,不包含所有三、进阶实践(没跑通,还在尝试中)
- 读取所有特征
- 提取更多特征
- 尝试不同模型
1.特征优化
特征选择:过滤属性唯一、缺失率过高、高相关特征
drop_cols = []
print('过滤异常特征...')
for col in cols:
if testdata[col].nunique()==1: # 属性值唯一
drop_cols.append(col)
if testdata[col].isnull().sum() / test_df.shape[0] > 0.95: # 缺失率大于0.95
drop_cols.append(col)
print('过滤高相关特征...')
def correlation(data, threshold):
col_corr = []
corr_matrix = data.corr()
for i in range(len(corr_matrix)):
for j in range(i):
if abs(corr_matrix.iloc[i,j]) > threshold: # 相关性大于0.98
colname = corr_matrix.columns[i]
col_corr.append(colname)
return list(set(col_corr))
drop_cols += correlation(testdata[cols], 0.98)过滤高相关特征时占用内存过多导致终止
特征提取:PCA、LDA、SVD这类降维特征,合并作为入模特征
# 合并训练数据和测试数据
df = pd.concat([traindata[[i for i in range(10000)]], testdata[[i for i in range(10000)]]], axis=0, ignore_index=True)
# 导入TruncatedSVD
from sklearn.decomposition import TruncatedSVD
# 调用TruncatedSVD
svd = TruncatedSVD(n_components = 16, random_state = 2023)
svd_res = svd.fit_transform(df.values)
for i in range(n_components):
df[f'svd_{i}'] = svd_res[:,i]提示range(n_components)的参数未定义
2.模型融合
第一种:多个模型分别输出结果,进行加权平均融合
def cv_model(clf, train_x, train_y, test_x, clf_name, seed = 2023):
'''
clf:调用模型
train_x:训练数据
train_y:训练数据对应标签
test_x:测试数据
clf_name:选择使用模型名
seed:随机种子
'''
folds = 5
kf = KFold(n_splits=folds, shuffle=True, random_state=seed)
oof = np.zeros(train_x.shape[0])
test_predict = np.zeros(test_x.shape[0])
cv_scores = []
for i, (train_index, valid_index) in enumerate(kf.split(train_x, train_y)):
print('************************************ {} ************************************'.format(str(i+1)))
trn_x, trn_y, val_x, val_y = train_x.iloc[train_index], train_y[train_index], train_x.iloc[valid_index], train_y[valid_index]
if clf_name == "lgb":
train_matrix = clf.Dataset(trn_x, label=trn_y)
valid_matrix = clf.Dataset(val_x, label=val_y)
params = {
'boosting_type': 'gbdt',
'objective': 'regression',
'metric': 'mae',
'min_child_weight': 6,
'num_leaves': 2 ** 6,
'lambda_l2': 10,
'feature_fraction': 0.8,
'bagging_fraction': 0.8,
'bagging_freq': 4,
'learning_rate': 0.1,
'seed': 2023,
'nthread' : 16,
'verbose' : -1,
}
model = clf.train(params, train_matrix, 2000, valid_sets=[train_matrix, valid_matrix],
categorical_feature=[], verbose_eval=200, early_stopping_rounds=100)
val_pred = model.predict(val_x, num_iteration=model.best_iteration)
test_pred = model.predict(test_x, num_iteration=model.best_iteration)
if clf_name == "xgb":
xgb_params = {
'booster': 'gbtree',
'objective': 'reg:squarederror',
'eval_metric': 'mae',
'max_depth': 5,
'lambda': 10,
'subsample': 0.7,
'colsample_bytree': 0.7,
'colsample_bylevel': 0.7,
'eta': 0.1,
'tree_method': 'hist',
'seed': 520,
'nthread': 16
}
train_matrix = clf.DMatrix(trn_x , label=trn_y)
valid_matrix = clf.DMatrix(val_x , label=val_y)
test_matrix = clf.DMatrix(test_x)
watchlist = [(train_matrix, 'train'),(valid_matrix, 'eval')]
model = clf.train(xgb_params, train_matrix, num_boost_round=2000, evals=watchlist, verbose_eval=200, early_stopping_rounds=100)
val_pred = model.predict(valid_matrix)
test_pred = model.predict(test_matrix)
if clf_name == "cat":
params = {'learning_rate': 0.1, 'depth': 5, 'bootstrap_type':'Bernoulli','random_seed':2023,
'od_type': 'Iter', 'od_wait': 100, 'random_seed': 11, 'allow_writing_files': False}
model = clf(iterations=2000, **params)
model.fit(trn_x, trn_y, eval_set=(val_x, val_y),
metric_period=200,
use_best_model=True,
cat_features=[],
verbose=1)
val_pred = model.predict(val_x)
test_pred = model.predict(test_x)
oof[valid_index] = val_pred
test_predict += test_pred / kf.n_splits
score = mean_absolute_error(val_y, val_pred)
cv_scores.append(score)
print(cv_scores)
return oof, test_predict
# 选择lightgbm模型
lgb_oof, lgb_test = cv_model(lgb, traindata[cols], traindata['label'], testdata[cols], 'lgb')
# 选择xgboost模型
xgb_oof, xgb_test = cv_model(xgb, traindata[cols], traindata['label'], testdata[cols], 'xgb')
# 选择catboost模型
cat_oof, cat_test = cv_model(CatBoostRegressor, traindata[cols], traindata['label'], testdata[cols], 'cat')
# 进行取平均融合
final_test = (lgb_test + xgb_test + cat_test) / 3提示lgb模型中“verbose_eval=200, early_stopping_rounds=100”两参数不存在
第二种:stacking融合
学习手册里的有些简略,可以参考【机器学习】集成学习——Stacking模型融合(理论+图解)
然后我自己又捋了一遍
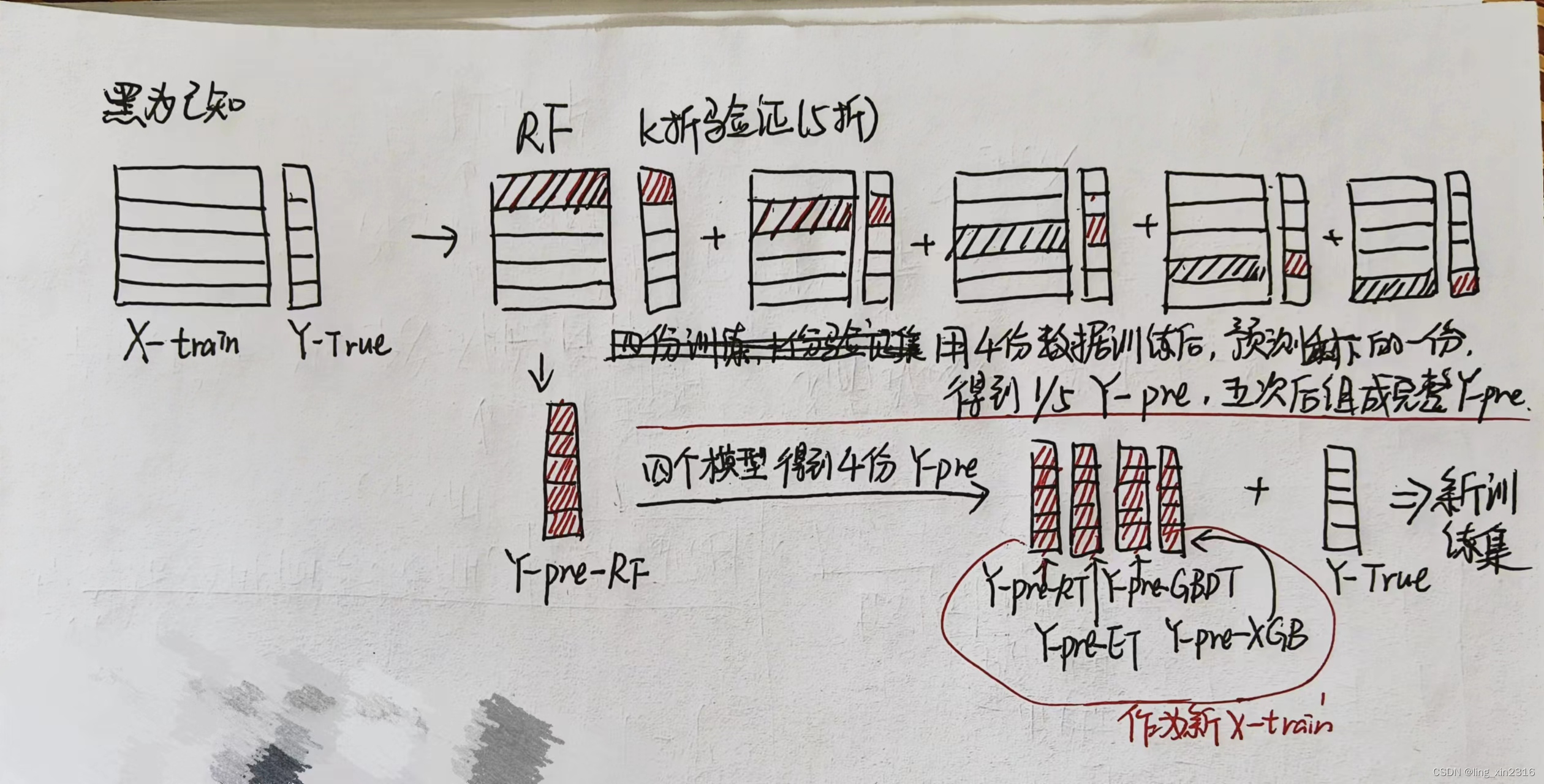


def stack_model(oof_1, oof_2, oof_3, predictions_1, predictions_2, predictions_3, y):
'''
输入的oof_1, oof_2, oof_3可以对应lgb_oof,xgb_oof,cat_oof
predictions_1, predictions_2, predictions_3对应lgb_test,xgb_test,cat_test
'''
train_stack = pd.concat([oof_1, oof_2, oof_3], axis=1)
test_stack = pd.concat([predictions_1, predictions_2, predictions_3], axis=1)
oof = np.zeros((train_stack.shape[0],))
predictions = np.zeros((test_stack.shape[0],))
scores = []
from sklearn.model_selection import RepeatedKFold
folds = RepeatedKFold(n_splits=5, n_repeats=2, random_state=2021)
for fold_, (trn_idx, val_idx) in enumerate(folds.split(train_stack, train_stack)):
print("fold n°{}".format(fold_+1))
trn_data, trn_y = train_stack.loc[trn_idx], y[trn_idx]
val_data, val_y = train_stack.loc[val_idx], y[val_idx]
clf = Ridge(random_state=2021)
clf.fit(trn_data, trn_y)
oof[val_idx] = clf.predict(val_data)
predictions += clf.predict(test_stack) / (5 * 2)
score_single = mean_absolute_error(val_y, oof[val_idx])
scores.append(score_single)
print(f'{fold_+1}/{5}', score_single)
print('mean: ',np.mean(scores))
return oof, predictions
stack_oof, stack_pred = stack_model(lgb_oof, xgb_oof, cat_oof, lgb_test, xgb_test, cat_test, traindata['age'])














 367
367











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









