







 本文详细解析了超几何分布的概念,包括其定义、检验方法及其在生物学中的应用案例,同时介绍了基于超几何分布的Fisher精确检验原理及R语言中的实现方式。
本文详细解析了超几何分布的概念,包括其定义、检验方法及其在生物学中的应用案例,同时介绍了基于超几何分布的Fisher精确检验原理及R语言中的实现方式。
1,超几何分布的定义
总共有N件产品,其中M件次品,现在从中抽取n件做检查,抽到k件次品的概率分布服从超几何分布。
P
(
k
,
N
,
M
,
n
)
=
(
(
M
k
)
)
∗
(
(
N
−
M
n
−
k
)
)
(
N
n
)
,
其
中
k
=
0
,
1
,
2
,
.
.
.
M
P(k, N, M, n) = \frac{\left(M \choose k \right)*\left(N-M \choose n-k \right)}{N \choose n},其中k = 0, 1, 2, ...M
P(k,N,M,n)=(nN)((kM))∗((n−kN−M)),其中k=0,1,2,...M
2,超几何分布检验
给定一个超几何分布,算出比某个事件更极端的概率,可以称为超几何分布检验。
比如在两个圈的venn图中,想要计算overlap是否显著:
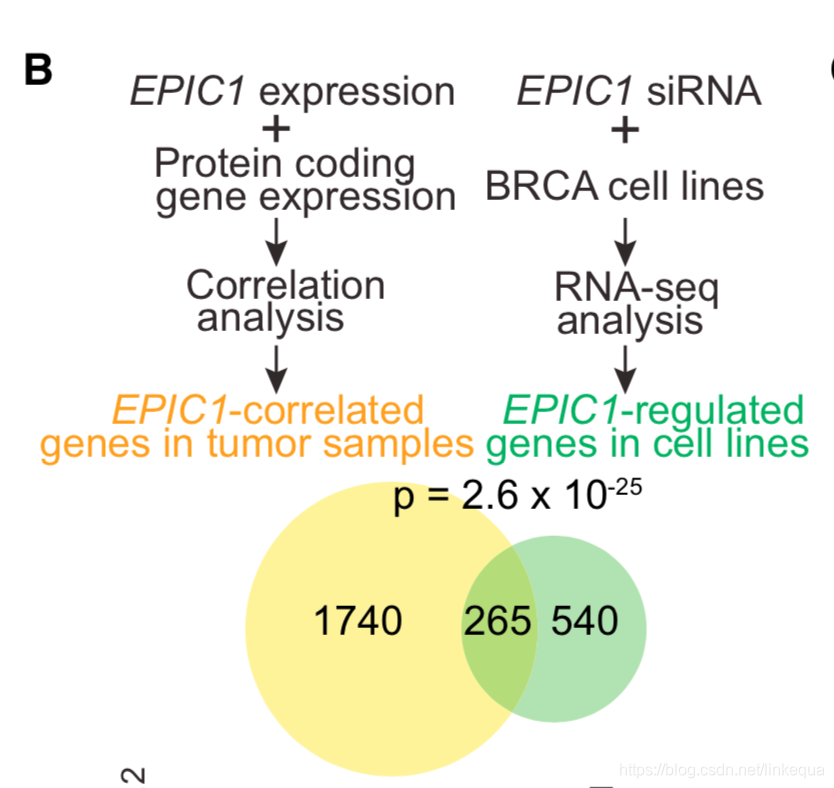
假设总共的基因个数为20000个,图中左边圈总数3005可以看成是次品的总个数,现从中抽取805个产品,需要计算得到次品个数大于等于265的概率。
思考过程:在次品个数是少数的情况下,overlap越高,从超几何分布来看,发生的概率越小。现在的overlap是265,可能会是过高的那种情况,那么现在计算overlap是265以及大于265的概率之和,如果这个概率很小,那就说明发生265这个事件不是随机的,进而就推出来了overlap为265是显著性高的一个事件。
3,fisher精确检验(Fisher exact-test)的原理基于超几何分布,实际就是超几何分布检验。
4,R包中实现
R中自带超几何分布的检验(stats包)
4.1 方法1
phyper(q-1, m, n, k, lower.tail=F) #备择假设为"more"的情况
4.2 方法2
1 - phyper(q-1, m, n, k) #备择假设为"more"的情况
Note:两种方法的参数如下:
q = the number of white balls drawn from the urn (without replacement)
q对应到抽样问题,为k
m = the number of white balls in the urn
m对应到抽样问题,为M
n = the number of black balls in the urn
n对应到抽样问题,为N-M
k = the number of balls drawn from the urn (sample size)
k对应到抽样问题,为n
Note: lower.tail使用的逻辑为: if TRUE (default), probabilities are P[X ≤ x], otherwise, P[X > x].
1, 当备择假设为"less"时,即关心左端的那一部分(overlap小的那一端),无论怎么设置lower.tail,q不用q-1替代;
2,当加上lower.tail=F参数时,备择假设为"more"时,即关心右端的那一部分(overlap大的那一端),无论怎么设置lower.tail,q必须用q-1替代。

















 828
828

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









