







一、偏倚(bias)和方差(variance)
在讨论线性回归时,我们用一次线性函数对训练样本进行拟合(如图1所示);然而,我们可以通过二次多项式函数对训练样本进行拟合(如图2所示),函数对样本的拟合程序看上去更“好”;当我们利用五次多项式函数对样本进行拟合(如图3所示),函数通过了所有样本,成为了一次“完美”的拟合。
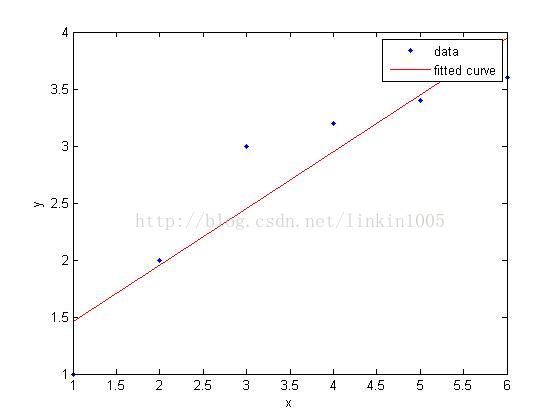
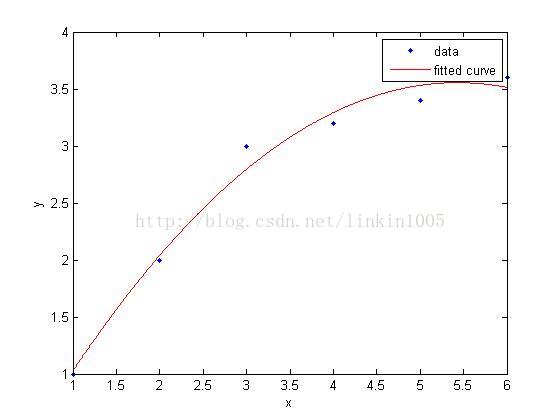
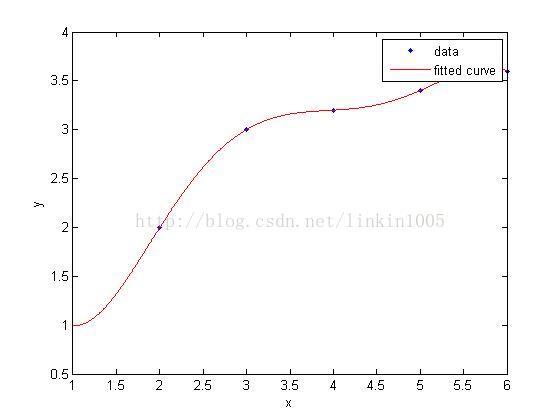
图3建立的模型,在训练集中通过x可以很好的预测y,然而,我们却不能预期该模型能够很好的预测训练集外的数据。换句话说,这个模型没有很好的泛化能力。因此,模型的泛化误差(generalization error)不仅包括其在样本上的期望误差,还包括在训练集上的误差。
图1和图3中的模型都有较大的泛化误差,然而他们的误差原因却不相同。图1建立了一个线性模型,但是该模型并没有精确的捕捉到训练集数据的结构,我们称图1有较大的偏倚(bias),也称欠拟合;图3通过5次多项式函数很好的对样本进行了拟合,然而,如果将建立的模型进行泛化,并不能很好的对训练集之外数据进行预测,我们称图3有较大的 ,也称过拟合。
通常,在偏倚和方差之间,这样一种规律:如果模型过于简单,其具有大的偏倚,而如果模型过于复杂,它就有大的方差。调整模型的复杂度,建立适当的误差模型,就变得极其重要了。
二、预备知识
首先我们先介绍两个非常有用的引理:
引理1:一致限(the union bound)令为k个不同的事件(不一定相互独立),那么有:
一致限说明:k个事件中任一个事件发生的概率小于等于这k个事件发生的概率和(等号成立的条件为这k个事件相两两互斥)。
引理2:Hoeffding 不等式(Hoeffding inequality)令为m个独立同分布的随机变量,由参数为 的伯努利分布(即
)生成。令
,为这些随机变量的均值,对于任意
有:
在机器学习中,引理2称为Chernoff边界(Chernoff bound),它说明:假设我们用随机变量的均值去估计参数
,估计的参数和实际参数的差超过一个特定数值的概率有一确定的上界,并且随着样本量m的增大,
与
很接近的概率也越来越大。
通过以上两个引理,我们能够引出机器学习中很重要结论。
为简单起见,我们只讨论二分类问题,即类标签为 。
假设给定的训练集为,且各训练样本
独立同分布,皆为某个特定分布D生成。对于一个假设函数(hypothesis),定义训练误差(training error)(也称为经验风险(empirical risk)或经验误差(empiriacal error))为:
训练误差为模型在训练样本中的错分类的比例,如果我们要强调是依赖训练集的,也可以将其写作
。
我们再定义泛化误差(generalization error):
这里得到的是一个概率,表示通过特定的分布D生成的样本(x,y)中的y与通过预测函数h(x)生成的结果不同的概率。
注意,我们假设训练集的数据是通过某种分布D生成的,我们以此为依据来衡量假设函数。这里的假设有时称为PAC(probablyapproximately correct)假设。
在线性分类中,假设函数中参数
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









