



 本文介绍了一种不依赖光流或递归神经网络的视频目标检测方法,通过全局聚类和序列级的语义聚合模块(SELSA)来增强特征表示。这种方法能够处理快速运动物体和视频的丰富视觉信息,解决外观退化问题。SELSA模块利用广义余弦相似度进行特征聚合,提高了对姿态变化、运动模糊等的鲁棒性。实验表明,这种方法在视频检测任务中表现出色,特别是在处理不可见目标时,优于传统方法。特征聚合的采样策略对性能影响显著,整个序列的聚合优于仅依赖附近帧的聚合。相比依赖后处理的方案,该方法能直接捕获序列信息,简化管道并提高效率。
本文介绍了一种不依赖光流或递归神经网络的视频目标检测方法,通过全局聚类和序列级的语义聚合模块(SELSA)来增强特征表示。这种方法能够处理快速运动物体和视频的丰富视觉信息,解决外观退化问题。SELSA模块利用广义余弦相似度进行特征聚合,提高了对姿态变化、运动模糊等的鲁棒性。实验表明,这种方法在视频检测任务中表现出色,特别是在处理不可见目标时,优于传统方法。特征聚合的采样策略对性能影响显著,整个序列的聚合优于仅依赖附近帧的聚合。相比依赖后处理的方案,该方法能直接捕获序列信息,简化管道并提高效率。
【亮点概述】
1.不依赖光流或递归神经网络进行特征聚合,不强调时间上相邻的帧,而是进行全局聚类。
2.在整个视频序列上聚集特征,将视频视为一包无序的帧,去学习每种类别的表示,可以理解为多镜头检测任务(视频由多组对象组成,对象的外观退化表现为类内特征变化较大),解决了无法在固定的时间范围之外利用视频的丰富信息的问题。
3.设计了新的序列级的语义聚合模块(SELSA)。
4.不需要复杂的后处理,管道简单干净。
后处理方法:试图通过设计复杂的规则连接静态图像检测器生成的边界框,从而整合视频级别的信息。
管道:指的是视频对每个目标在每一帧提取的检测框按照时间序列的顺序连接在一起,就构成了一个管道。
【面临问题】

1.处理快速运动的物体:快速运动带来的图像退化是不易观察到的,如运动模糊、相机散焦、姿势变化。
2.处理视频丰富的视觉信息:视频的任何一帧上只要能与感兴趣对象的特征相似度较高,就可能有对整个的目标检测有贡献,当一帧中的目标外观退化严重时,可通过其它特征丰富的帧减轻这种退化。
image degradation unseen:图像在形成、记录、处理和传输过程中,由于成像系统、记录设备、传输介质和处理方法的不完善,导致图像质量的下降,这种现象叫做图像退化。
【基本流程】
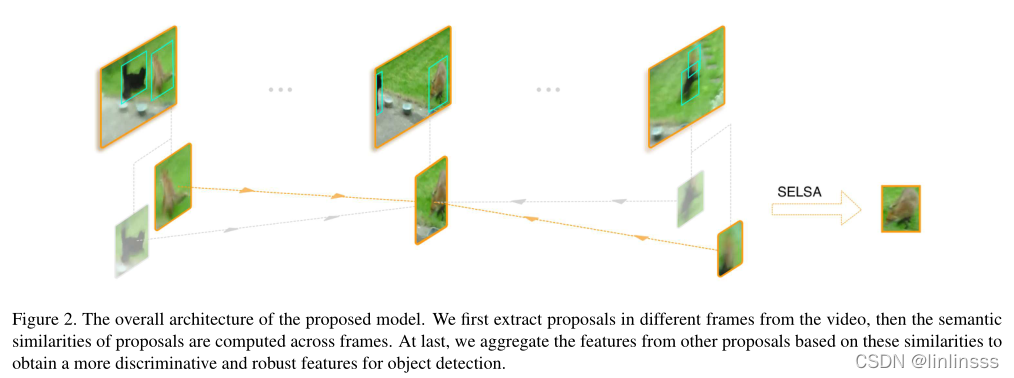
1.从整个视频中提取不同帧的目标
2.聚类,跨帧计算目标的语义相似性,基于相似度聚合其他帧的目标区域特征
3.转换,检测
【SELSA模块】
将跨时空与语义相似联系起来设计了 SELSA模块,代表目标f类的所有帧图像的集合,使用广义余弦相似度衡量
之间的语义相似度,公式如下
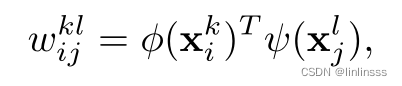
相似度越高代表属于同一类别的可能性越大。
特征聚合,以语义相似度作为参考聚合其他帧目标区域的特征,聚合的新目标特征具有丰富的信息,可以应对姿态变化、运动模糊和对象变形等外观变化影响,此外,特征聚合是在目标区域的特征上进行的,不需要冗余的像素级计算,也更关注感兴趣的区域。从F个帧中聚合,每帧产生N个目标,聚合的特征为
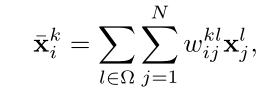
针对视频中感兴趣目标的识别,相比于从附近帧进行小范围的特征聚合,从整个序列上聚集特征将更具识别能力和检测的鲁棒性,因为外观退化可能会跨越一个很宽的时间,短时间内的帧可能具有很高的冗余度,削弱了特征聚合的优势,所以在整个视频帧上利用语义聚合特征,不易受到长时间外观退化的影响。
【使用网络】
1.消融实验主干网络:ResNet-101
2.检测网络:RPN,检测网络RPN应用于CONV4的输出
3.SELSA模块:每一个建立在 Faster R-CNN的一个全连接之后 (FC→SELSA→FC→SELSA),FAST-RCNN应用于CONV5的输出
【消融实验】
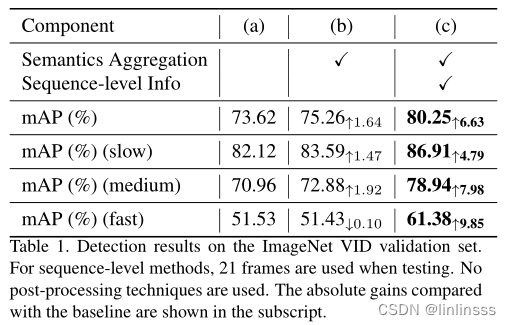
1.b列相当于SELSA的退化版,从同一帧中获取聚合的目标,这导致相比于单帧基线的方法只有1.64的mAP提高。
2.cl列使用SELSA,整体上的识别率都有较大提升,特别是fast部分提升了9.85。
【特征聚合的抽样策略】
特征聚合的采样策略对视频检测很重要,测试期间在特征聚合中使用更多的帧会产生更好的结果,以均匀的步幅对帧进行采样,以提高性能。
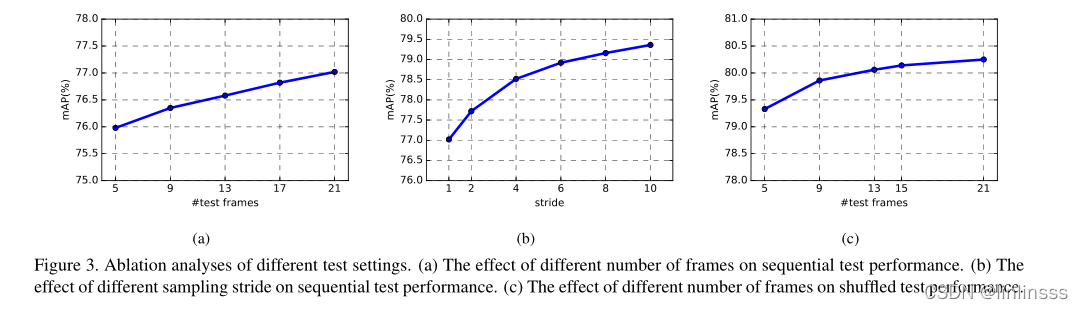 1.从图(a) 可以看出从聚合5帧增加到聚合21帧会有1.04的mAP的提高。
1.从图(a) 可以看出从聚合5帧增加到聚合21帧会有1.04的mAP的提高。
2.从图(b)中,聚合21帧保持不变, 步长从1提升到10,mAP提高到79.36。
3.采样的步长比测试帧的数量相比提升的更大,由于在序列级上处理具有多样性的样本是更加有效的,而光流法和RNN等聚合方法不会因步长有提升。基于光流法中,当帧数超过某个阈值时,性能会随着帧数的增加而下降,而在无序的特征聚合上,如图(c)中使用5帧就能达到之前21帧的水平,优势来自语义邻域的聚合而非时间邻域。
【后处理问题】
不依赖后处理方法整合完整的序列信息,表2中使用Seq-NMS的后处理方法后性能反而下降,说明该方法已经捕获到了完整的序列级的信息。

在相对于其他方法在后处理上能得到大的提升,该方法在扩充数据的处理上会有较大提升,因为丰富了样本的多样性,在整个序列上聚合特征会获得更丰富的信息。并且相比与单独的后处理步骤可能会得到次优结果,端到端的训练可以更好的利用序列信息。
【结果分析】

使用EPIC KITCHENS数据集进行测试,SELSA在可见与不可见的目标分离上比Faster R-CNN提升了1.4/2.94,表明SELSA适用于更复杂的视频检测任务。

















 8801
8801

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









