









一. 经典网络介绍
首先介绍目前比较主流的几种经典网络,AlexNet[2012]、VGG16[2014]、GoogLeNet[2014]、ResNet[2015]。
这几种网络都是在 ILSVRC 比赛中脱颖而出的,越往后网络越复杂, ResNet 为152层结构,测试错误率为 3.57%。
为了能给大家一个更宏观的视图,作者将目前CNN在多个领域的应用整理了一张图来说明:
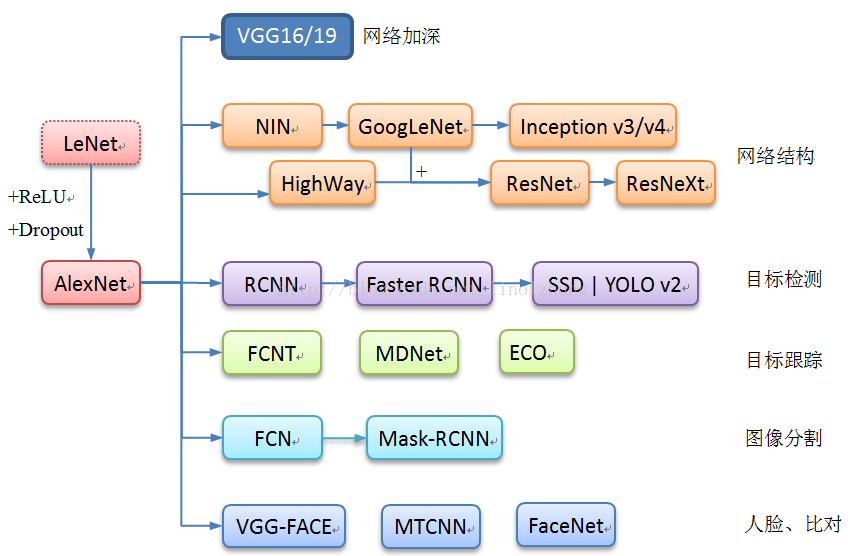
下面我们重点关注和讲解的仍是之前提到的四种主流模型,主要应用聚焦在分类,当然其他方向的应用都是以此为基础,希望有时间可以在后续的文章中展开。
二. AlexNet
在 LeNet 基础上,AlexNet 加入了ReLU层和DropOut,有效解决了大规模数据训练的震荡问题,因此也开启了一个里程碑,AlexNet 可以看作是深度学习的一个起点,网络分为5个卷积层+3个全连接层,来看网络结构图(这张结构图比较经典,双GPU实现):
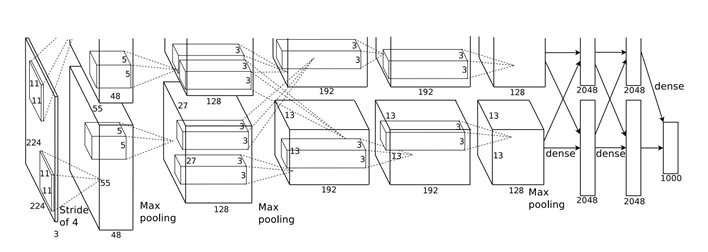
AlexNet 贡献是非常大的,描述为以下几点:
● 采用 ReLU 替代了sigmoid,提高了网络的非线性;
● 引入Dropout 训练方式,增强了网络的健壮性;
● 通过 LRN(Local Responce Normalization)提高了网络适应性;
目前LRN已经不怎么使用,基本被BN取代
● 通过Data Augmentation 证明了大量数据对于模型的作用。
来看 AlexNet 在 TensorFlow 下的时间评测代码:
#coding=utf-8
from datetime import datetime
import math
import time
import tensorflow as tf
batch_size = 32
num_batches = 100
# define print shape
def print_activations(t):
print(t.op.name,' ',t.get_shape().as_list())
# conv1
def inference(images):
parameters = []
with tf.name_scope('conv1') as scope:
kernel = tf.Variable(tf.truncated_normal([11,11,3,64],dtype=tf.float32,stddev=1e-1), name='weights')
wx = tf.nn.conv2d(images,kernel,[1,4,4,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[64],dtype=tf.float32),trainable=True,name='biases')
wx_add_b = tf.nn.bias_add(wx,biases)
conv1 = tf.nn.relu(wx_add_b,name=scope)
parameters += [kernel,biases]
print_activations(conv1)
lrn1 = tf.nn.lrn(conv1,4,bias=1.0,alpha=0.001/9,beta=0.75,name='lrn1')
pool1 = tf.nn.max_pool(lrn1,ksize=[1,3,3,1],strides=[1,2,2,1],padding='VALID',name='pool1')
print_activations(pool1)
# conv2
with tf.name_scope('conv2') as scope:
kernel = tf.Variable(tf.truncated_normal([5,5,64,192],dtype=tf.float32,stddev=1e-1), name='weights')
wx = tf.nn.conv2d(pool1,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[192],dtype=tf.float32),trainable=True,name='biases')
wx_add_b = tf.nn.bias_add(wx,biases)
conv2 = tf.nn.relu(wx_add_b,name=scope)
parameters += [kernel,biases]
print_activations(conv2)
lrn2 = tf.nn.lrn(conv2,4,bias=1.0,alpha=0.001/9,beta=0.75,name='lrn2')
pool2 = tf.nn.max_pool(lrn2,ksize=[1,3,3,1],strides=[1,2,2,1],padding='VALID',name='pool2')
print_activations(pool2)
# conv3
with tf.name_scope('conv3') as scope:
kernel = tf.Variable(tf.truncated_normal([3,3,192,384],dtype=tf.float32,stddev=1e-1), name='weights')
wx = tf.nn.conv2d(pool2,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[384],dtype=tf.float32),trainable=True,name='biases')
wx_add_b = tf.nn.bias_add(wx,biases)
conv3 = tf.nn.relu(wx_add_b,name=scope)
parameters += [kernel,biases]
print_activations(conv3)
# conv4
with tf.name_scope('conv4') as scope:
kernel = tf.Variable(tf.truncated_normal([3,3,384,256],dtype=tf.float32,stddev=1e-1), name='weights')
wx = tf.nn.conv2d(conv3,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256],dtype=tf.float32),trainable=True,name='biases')
wx_add_b = tf.nn.bias_add(wx,biases)
conv4 = tf.nn.relu(wx_add_b,name=scope)
parameters += [kernel,biases]
print_activations(conv4)
# conv5
with tf.name_scope('conv5') as scope:
kernel = tf.Variable(tf.truncated_normal([3,3,256,256],dtype=tf.float32,stddev=1e-1), name='weights')
wx = tf.nn.conv2d(conv4,kernel,[1,1,1,1],padding='SAME')
biases = tf.Variable(tf.constant(0.0, shape=[256],dtype=tf.float32),trainable=True,name='biases')
wx_add_b = tf.nn.bias_add(wx,biases)
conv5 = tf.nn.relu(wx_add_b,name=scope)
parameters += [kernel,biases]
print_activations(conv5)
pool5 = tf.nn.max_pool(conv5,ksize=[1,3,3,1],strides=[1,2,2,1],padding='VALID',name='pool5')
print_activations(pool5)
return pool5,parameters
# define time run
def time_tensorflow_run(session,target,info_string):
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: step %d, duration = %.3f' %(datetime.now(),i-num_steps_burn_in,duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn *mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %(datetime.now(),info_string,num_batches,mn,sd))
# main fun
def run_benchmark():
with tf.Graph().as_default():
image_size = 224
images = tf.Variable(tf.random_normal([batch_size,image_size,image_size,3],dtype=tf.float32,stddev=1e-1))
pool5, parameters = inference(images)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# time
time_tensorflow_run(sess,pool5,"Forward")
objective =tf.nn.l2_loss(pool5)
grad = tf.gradients(objective,parameters)
time_tensorflow_run(sess,grad,"Forward-backward")
# run
run_benchmark()三. VGG16
人们相信,网络层数越多,对应的参数越复杂,所能描述的网络越准确,基于这个假设,将 AlexNet 网络进行扩充,得到了 VGG16/19,这是在当时的条件下能控制住网络震荡最好的网络(预知更多的层,请看之后的分解 ^v^)。
VGG16 的叫法来自于 网络包含 16 层卷积,包括 13层的卷积+3层的全连接。
VGG的网络结构图 【点击查看详图】:
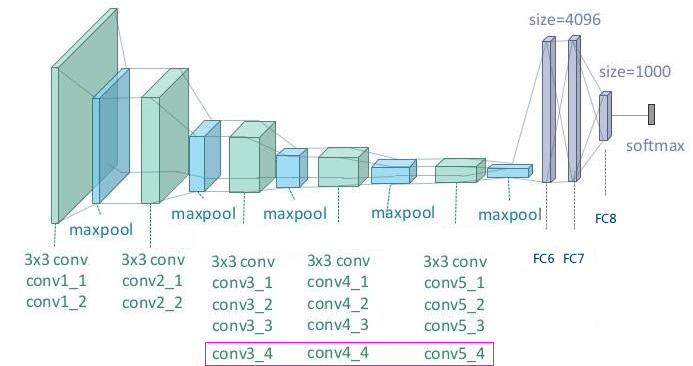
VGG19 是在 conv3、conv4、conv5 三个Group各添加一层卷积(上图红色框)。
#coding=utf-8
from datetime import datetime
import math
import time
import tensorflow as tf
batch_size = 32
num_batches = 100
# define conv
def conv(input,name,kh,kw,n_out,dh,dw,p):
n_in = input.get_shape()[-1].value
with tf.name_scope(name) as scope:
kernel = tf.get_variable(scope+"w",shape=[kh,kw,n_in,n_out],dtype=tf.float32,initializer=tf.contrib.layers.xavier_initializer_conv2d())
conv = tf.nn.conv2d(input,kernel,[1,dh,dw,1],padding='SAME')
bias_init_val = tf.constant(0.0,shape=[n_out],dtype=tf.float32)
biases = tf.Variable(bias_init_val, trainable=True,name='biases')
wx_add_b = tf.nn.bias_add(conv,biases)
relu = tf.nn.relu(wx_add_b,name=scope)
p += [kernel,biases]
return relu
# define fc
def fc(input,name,n_out,p):
n_in = input.get_shape()[-1].value
with tf.name_scope(name) as scope:
kernel = tf.get_variable(scope+"w",shape=[n_in,n_out],dtype=tf.float32,initializer=tf.contrib.layers.xavier_initializer())
biases = tf.Variable(tf.constant(0.1,shape=[n_out],dtype=tf.float32), name="biases")
relu = tf.nn.relu_layer(input,kernel,biases, name = scope)
p += [kernel,biases]
return relu
# define pool
def max_pool(input,name,kh,kw,dh,dw):
return tf.nn.max_pool(input,ksize=[1,kh,kw,1],strides=[1,dh,dw,1],padding='SAME',name=name)
# define inference
def inference(input,keep_prob):
p = []
conv1_1 = conv(input,name="conv1_1",kh=3,kw=3,n_out=64,dh=1,dw=1,p=p)
conv1_2 = conv(conv1_1,name="conv1_2",kh=3,kw=3,n_out=64,dh=1,dw=1,p=p)
pool1 = max_pool(conv1_2, name="pool1",kh=2,kw=2,dw=2,dh=2)
conv2_1 = conv(pool1,name="conv2_1",kh=3,kw=3,n_out=128,dh=1,dw=1,p=p)
conv2_2 = conv(conv2_1,name="conv2_2",kh=3,kw=3,n_out=128,dh=1,dw=1,p=p)
pool2 = max_pool(conv2_2, name="pool2",kh=2,kw=2,dw=2,dh=2)
conv3_1 = conv(pool2,name="conv3_1",kh=3,kw=3,n_out=256,dh=1,dw=1,p=p)
conv3_2 = conv(conv3_1,name="conv3_2",kh=3,kw=3,n_out=256,dh=1,dw=1,p=p)
conv3_3 = conv(conv3_2,name="conv3_3",kh=3,kw=3,n_out=256,dh=1,dw=1,p=p)
pool3 = max_pool(conv3_3, name="pool3",kh=2,kw=2,dw=2,dh=2)
conv4_1 = conv(pool3,name="conv4_1",kh=3,kw=3,n_out=512,dh=1,dw=1,p=p)
conv4_2 = conv(conv4_1,name="conv4_2",kh=3,kw=3,n_out=512,dh=1,dw=1,p=p)
conv4_3 = conv(conv4_2,name="conv4_3",kh=3,kw=3,n_out=512,dh=1,dw=1,p=p)
pool4 = max_pool(conv4_3, name="pool4",kh=2,kw=2,dw=2,dh=2)
conv5_1 = conv(pool4,name="conv5_1",kh=3,kw=3,n_out=512,dh=1,dw=1,p=p)
conv5_2 = conv(conv5_1,name="conv5_2",kh=3,kw=3,n_out=512,dh=1,dw=1,p=p)
conv5_3 = conv(conv5_2,name="conv5_3",kh=3,kw=3,n_out=512,dh=1,dw=1,p=p)
pool5 = max_pool(conv5_3, name="pool5",kh=2,kw=2,dw=2,dh=2)
shp = pool5.get_shape()
flattened_shape = shp[1].value * shp[2].value * shp[3].value
resh1 = tf.reshape(pool5,[-1,flattened_shape], name = "resh1")
fc6 = fc(resh1,name="fc6",n_out=4096,p=p)
fc6_drop = tf.nn.dropout(fc6,keep_prob,name="fc6_drop")
fc7 = fc(fc6_drop,name="fc7",n_out=4096,p=p)
fc7_drop = tf.nn.dropout(fc7,keep_prob,name="fc7_drop")
fc8 = fc(fc7_drop,name="fc8",n_out=1000,p=p)
softmax = tf.nn.softmax(fc8)
predit = tf.argmax(softmax,1)
return predit,softmax,fc8,p;
# define time run
def time_tensorflow_run(session,target,feed,info_string):
num_steps_burn_in = 10
total_duration = 0.0
total_duration_squared = 0.0
for i in range(num_batches + num_steps_burn_in):
start_time = time.time()
_ = session.run(target, feed_dict=feed)
duration = time.time() - start_time
if i >= num_steps_burn_in:
if not i % 10:
print('%s: step %d, duration = %.3f' %(datetime.now(),i-num_steps_burn_in,duration))
total_duration += duration
total_duration_squared += duration * duration
mn = total_duration / num_batches
vr = total_duration_squared / num_batches - mn *mn
sd = math.sqrt(vr)
print('%s: %s across %d steps, %.3f +/- %.3f sec / batch' %(datetime.now(),info_string,num_batches,mn,sd))
# main func
def run_benchmark():
with tf.Graph().as_default():
image_size = 224
images = tf.Variable(tf.random_normal([batch_size,image_size,image_size,3],dtype=tf.float32,stddev=1e-1))
keep_prob = tf.placeholder(tf.float32)
predictions,softmax,fc8,p=inference(images,keep_prob)
init = tf.global_variables_initializer()
sess = tf.Session()
sess.run(init)
# time
time_tensorflow_run(sess,predictions, {keep_prob:1.0}, "Forward")
objective =tf.nn.l2_loss(fc8)
grad = tf.gradients(objective,p)
time_tensorflow_run(sess,grad, {keep_prob:0.5}, "Forward-backward")
# run
run_benchmark()四. GoogLeNet
VGG16 以来,深度网络面临的问题比较突出:
1. 深度网络规模越来越大,一味的加深层数使得网络震荡,结果难以收敛,对精度提升并没有作用;
2. 网络深度增加导致参数也越来越多,容易产生过拟合的问题;
3. 网络层数的提高带来计算量增加,严重影响网络性能;
针对上述问题,Google 提出了一个22层的深度网络 GoogLeNet,将 Top5 错误率降低到 6.67%,获得了2014年 ILSVRC 的冠军。
(PS:为了纪念 LeNet,Google 搞了个大写)。
这是一个 Inception module的概念,采用不同尺度的卷积核进行特征提取(对应下面左图的1*1,3*3,5*5),增加单层网络的特征提取能力;另外,通过 1*1 的卷积核(对应右图)进行降维,如下图所示:
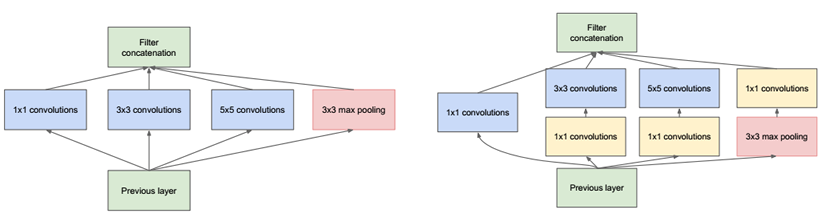
完整的 GoogLeNet 是多个 Inception Module 的组合,如下图所示:
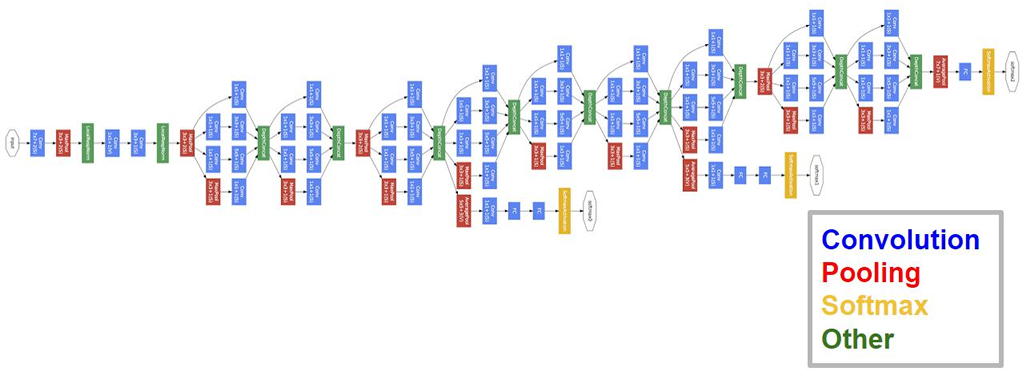
TensorFlow 实现 Google Inception V3 可以参考 Tensorflow 的开源实现,代码量比较大,这里就不再贴出来了。
Github地址:https://github.com/tensorflow/models/blob/master/slim/nets/inception_v3.py















 2471
2471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









