









CVPR2019:UIC
- 题目
Unsupervised Image Captioning
下载链接
出自腾讯AI实验室
模型名称UIC我自己起的,文中没给出模型名称。 - 动机
已有的模型都需要标注好的image-sentence数据进行训练,需要高昂的人力进行数据标注。

- 贡献
- 提出第一个无监督的image captioning方法,不依赖image-sentence pairs。
- 提出训练image captioning模型的三个目标。
- 提出一种使用无监督数据对模型初始化的全新方法,利用visual concept detector对于每张image生成伪造的sentence,并使用伪造的image-sentence pairs对模型进行初始化。
- 在网上爬了超过200万的sentences,用于训练,最终得到的模型结果很好。
- 方法
方法的整体框架如图所示:

具体流程为:首先,输入image,经过CNN提取特征。然后,将得到的特征输入到Generator中,得到sentence。最后,将生成的sentence输入Discriminator,判断sentence是否合理。
在训练过程中,提出三个训练目标:1. 通过Generator生成的sentence要human-like,这一点通过Discriminator实现,Discriminator会判断生成的sentence是出自Generator还是网上爬取的语料库。2. 由于使用的sentences是从网上爬取的,和image没有什么关联,通过visual concept将二者关联起来。先使用visual concept detector得到image的concept,然后判断Generator生成的sentence中是否包含image的concept,如果包含,就给予concept reward。3. image captioning模型应该能理解更多的image中的语义concept,且目前为止,生成的sentence的质量只由visual concept detector决定,故作者使用了Image Reconstruction和Sentence Reconstruction来让生成的sentence和image更贴近。具体的方法如下图所示,其实就是无监督中常用的重构,双向反复重构。

- 实验
本文模型生成的sentence如下图所示:

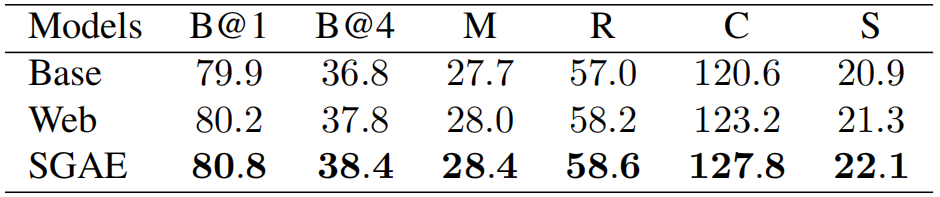
下面是实验结果:


训练过程中,生成正确concept个数的趋势。可以看出,初始化与否,在经过一定的iterations后,模型的能力不会差太多。

CVPR2019:SGAE
- 题目
Auto-Encoding Scene Graphs for Image Captioning
下载链接
南洋理工大学张含望老师组的工作. - 动机
在已有的image captioning工作中,模型生成的sentences不够human-like。本文提出了共享字典,将共享字典在文本语料库上预训练,并与captioning模型结合,引入共享字典的先验知识。这相当于在模型中结合了inductive bias,使其能生成更加human-like的sentences。

- 贡献
- 提出使用SGAE(场景图自编码器)学习language inductive bias的特征表达。
- 使用MGCN网络修正场景图到visual representation。
- 使用带有字典的、基于SGAE的、编码-解码的image captioner来引导language decoding。
-
方法
传统方法(top)和本文方法(bottom)的对比如下图所示:

在上图中,我们可以很清楚的看出,对于传统方法而言,生成sentences的过程遵循公式(1)。而对于本文提出的方法,生成sentences的过程遵循公式(4)。其中,字典D是在文本语料库上预训练得到的,来帮助MGCN对image feature进行re-encode,降低vision和language之间的gap。
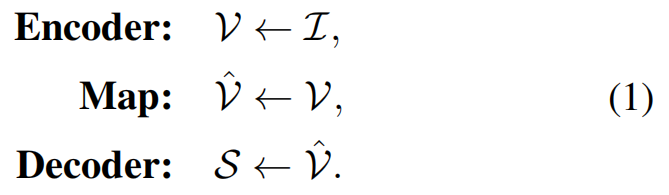
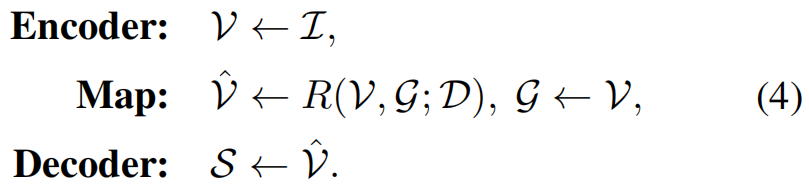
对于SGAE部分,实际操作形如公式(5)。

关于 G ← S G \leftarrow S G←S,文中给出了一个图片的例子,如下图所示。将每个object、attribute和relation都视为node。如果object具有某种attribute,则将两个节点连接一条有向边;如果两个object之间具有某种relation,则每个object和该relation连接一条有向边。关于 X ← G X \leftarrow G X←G,文中使用的是embedding,也是如下图所示。这一步的目的是,让原始的三类node转化到context-aware的embedding空间 X X X。

关于re-encoder部分,即公式中的 R ( ) R() R(),直观的表现如下图所示。途中红线代表未经过re-encode生成的sentence,绿线代表经过re-encode生成的sentence。可以看出,经过re-encode后,确实更human-like。

-
实验
MS-COCO Karpathy split

使用不同语料库
使用不同场景图的实验结果,和captions展示


online MS-COCO test server

结果展示

CVPR2019:RND
- 题目
Reflective Decoding Network for Image Captioning
下载链接
香港科技大学+腾讯 - 动机
已有的image captioning方法大多关注于提升visual feature的质量,而忽略了language的固有属性,本文以此为切入点,提出RDN方法。 - 贡献
- 和传统的caption decoder相比,本文提出的RDN可以有效地提升长序列的建模能力。
- 通过考虑long-term textual attention,可以显示地探索单词之间的连贯性,并在文本域可视化单词决策过程,从新颖的角度解释了框架的原理和结果。
- 本文设计了一个新颖的positional module,使得本文的RDN方法可以分析caption中的每个word的相对位置,来达到对句法范式的更好理解。
- 本文提出的RDN方法在COCO数据集上可以达到state-of-the-art,并且在hard cases上的表现更为突出。
- 方法
本文方法的整体框架如下图所示。

整体上来看,本文方法共包括两个主要部分,分别是:Object-Level Encoder和Reflective Decoder。前者通过Faster R-CNN实现,对于image I I I,获得其regional visual representation R I = { r i } i = 1 k R_I=\{ r_i \}_{i=1}^{k} RI={ri}i=1k。后者用于解码,获得sentences (captions)。
Reflective Decoder共包含三个部分,分别是:Attention-based Recurrent Module(基于注意力的循环模块)、Reflective Attention Module(反射注意模块,ps:姑且这么叫)和Reflective Position Module(反射定位模块)。其中,Attention-based Recurrent Module指的是图中的第一个LSTM层(图片下方的那个)和 A t t v i s Att_{vis} Attvis层,用于自上而下地计算visual attention。Reflective Attention Module指的是图中的第二个LSTM层和 A t t r e f Att_{ref} Attref层(图中的RAM层),用于输出language description。Reflective Position Module指的是图中的RPM层,用于注入每个单词的位置信息,通过最小化 I r t I_r^t Irt和 I p t I_p^t Ipt之间的差距来达到, I r t I_r^t Irt是作者为每个单词的位置设计的标签, I p t I_p^t Ipt代表Reflective Position Module的输出,具体的定义形如公式(8)。
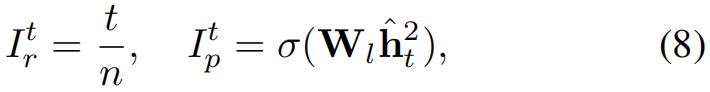
- 实验
MSCOCO Karpathy test split, single model.

MSCOCO Karpathy test split, ensemble models. 本文方法使用6个single modle进行ensemble。

COCO Leaderboard

在hard cases上的对比

captioning结果展示

对Reflective Position Module的结果进行可视化

ICCV2019:CNM
- 题目
Learning to Collocate Neural Modules for Image Captioning
下载链接
南洋理工大学张含望老师组的工作. - 动机
动机可以用下图表示. 由于在训练过程中, 数据集内不同单词的出现频率并不相同, 会导致学到的模型存在bias, 即: 预测训练集中出现频率多的词的概率较大.

- 贡献
- 本文提出了第一个用于image captioning的module network.
- 本文提出了在partially observed sentences情况下进行有效的模块搭配训练的方法.
- 使用本文方法后, 实验结果有显著提升, 本文方法是一个通用且有效的方法.
- 方法
本文的整体框架如图所示:

对于输入的image, 首先使用CNN进行特征提取, 然后将CNN特征转化到四个不同的特征集, 分别是: Object, Attribute, Relation, Function. 其中, Object中包含物体的类别, Attribute包含一些形容词, Relation包含一些物体之间的相互作用, 如: on, between等, Function包含一些功能词, 如: a, an等.
然后,将转化后的四类特征输入到Controller, 其内部具体的操作如下图所示:

首先, 使用三个网络结构相同, 但不共享权值的网络得到三类Attention, 具体的操作如公式(7)所示. 然后, 经过LSTM和Softmax对四类转化特征生成weights, 即上图中的"Soft weights generation"部分, 这部分的具体操作如公式(8)所示, 其中, c代表RNN网络的输出. 最后, 即得到了融合后的特征.
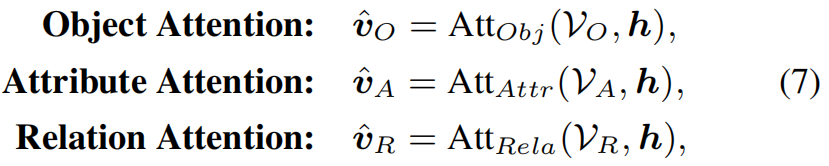

和VQA任务不同的是, 在image captioning任务中, 只有partially observed sentences是可见的. 为了更好的进行reasoning, 将decoder部分重复M次, 尽量观察到更多的sentences, 来得到和图片信息更加相关的caption. - 实验


本文存在的问题

ICCV2019:Graph-Align
- 题目
Unpaired Image Captioning via Scene Graph Alignments
下载链接
本文作者是南洋理工大学的博士生顾久祥。 - 动机
和UIC的动机一样,标注image-sentence pair需要大量的人力,作者提出一种基于场景图的方法,用于unpaired image captioning。 - 贡献
- 提出一种基于场景图的方法,用于unpaired image captioning。
- 提出一种用于跨模态特征对齐的无监督方法,不使用任何paired data。
- 方法
本文方法的整体框架如图所示:

测试时的具体步骤为:首先,将给定的image输入Image Scene Graph Generator,得到image的场景图;然后,对image场景图进行编码,得到image特征;然后,使用Feature Mapping将image特征映射到sentence空间,得到sentence特征;最后,使用解码器对sentence特征进行解码,得到sentence。
传统的基于“编码-解码”的方法中,captioning的整个过程如公式(1)所示。对image I I I编码得到 V V V,然后对 V V V解码得到sentence S S S。本文方法的流程遵循公式(2)和(3),首先基于image I I I得到其场景图,然后将场景图映射为Sentence空间的场景图,最后在解码得到Sentence。在Mapping的过程中,实际上可以将公式(3)进一步分解为公式(4),其中 P ( f S ∣ f I ) P(f^S|f^I) P(fS∣fI)代表跨模态Mapper。
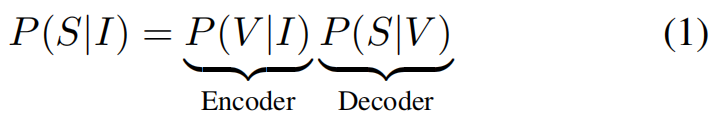
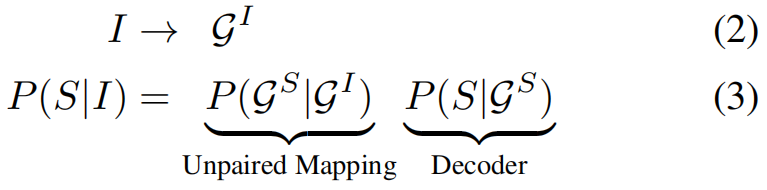
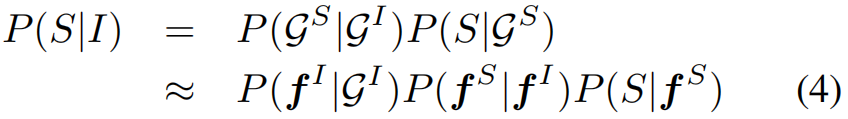
其实本文需要着重理解的便是如何进行跨模态Mapping,这部分又是如何训练呢?作者给了下面这个图,其实质是使用了CycleGAN。CycleGAN是2017年提出的,用来做图片风格迁移,可以将unpaired图片从一个领域迁移到另一个领域。这么一说,是不是通了,作者使用CycleGAN将unpaired数据从image领域迁移到sentence领域。关于这部分的损失设定,大家可以参考原论文,这里不贴出了。

- 实验
MSCOCO test split。表中,Avg表示在进行Object (Relation or Attribute) Embedding的时候使用平均值,Att*表示对Object, Relation and Attribute添加相同的注意力,Att表示对Object, Relation and Attribute添加不同的注意力。

特征可视化:

在GAN部分,使用不同损失对实验结果的影响:

使用不同的mapping方法,在MSCOCO test split上得到的实验结果。其中,Shared GAN表示对于三种特征(object, relation, attribute)共享参数,Single GAN表示将三种特征进行concatenate后再进行mapping。
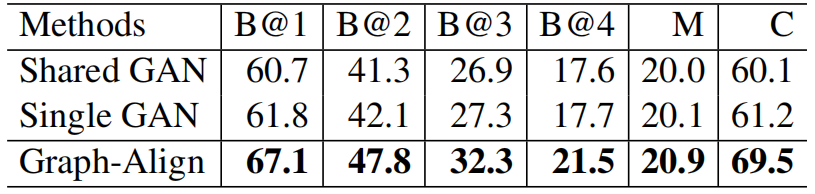
实验结果展示:

一些failed结果:
















 8876
8876











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









