






问题引入
问题1:越深越好?
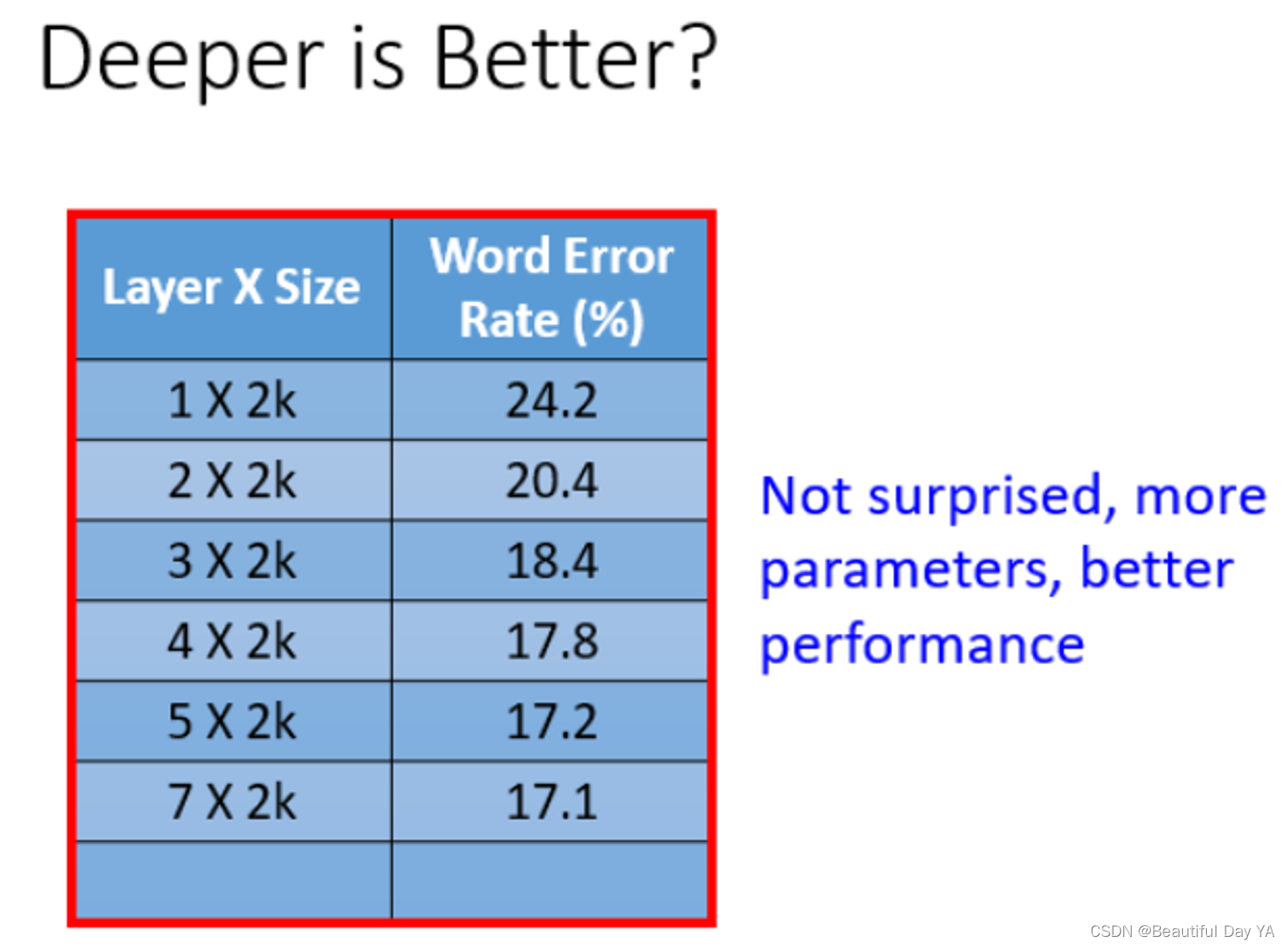 learning从一层到七层,error rate在不断的下降。能看出network越深,参数越多,performance较也越好
learning从一层到七层,error rate在不断的下降。能看出network越深,参数越多,performance较也越好
问题2:矮胖结构 v.s. 高瘦结构

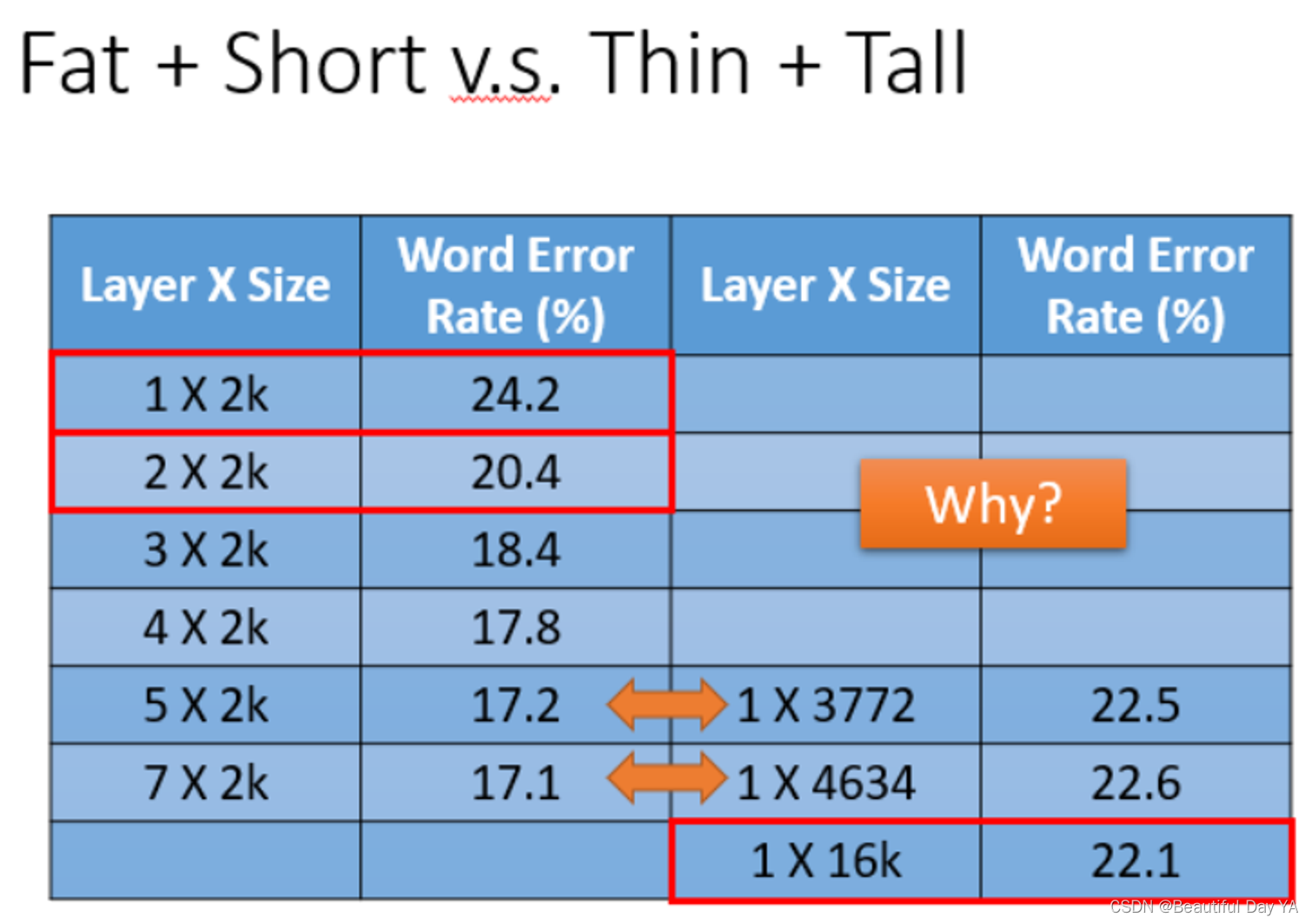
所以在参数两相同的情况下如果把network变高对performance是很有帮助的,network变宽对performance帮助没有那么好的
为什么变高比变宽好呢?
浅层理解:模块化,不要把所有都放在main函数中
深层理解:(举例)
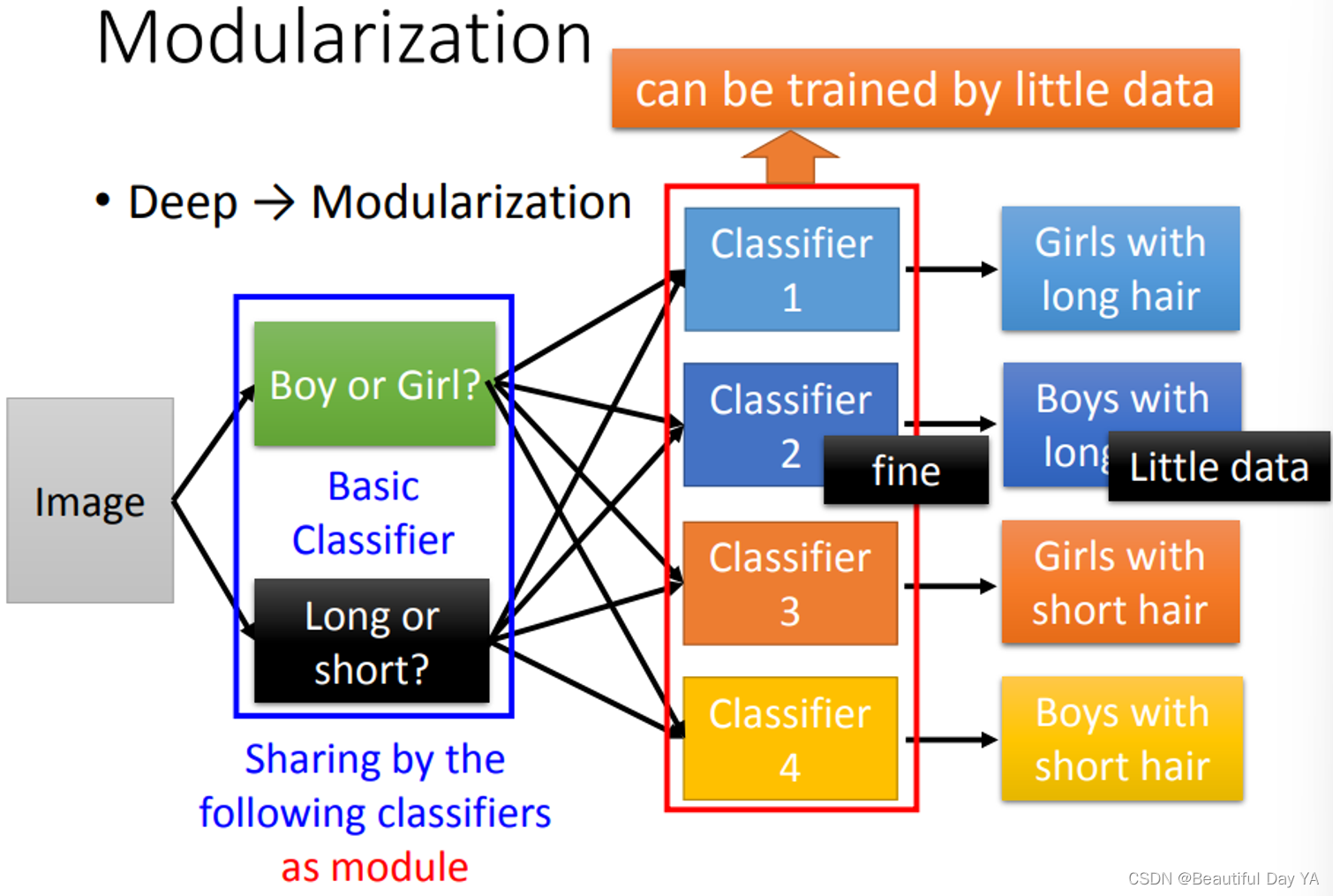 如果要分出长发女、长发男、短发女、短发男,长发男的样本明显要少一些。此时做分类,先将他们分成男生和女生在进行长发短发的分类比直接进行四种的分类准确率明显要高很多。相当于加了一个基础的分类器。后面的分类器可以利用前面的结果,所以它就可以用比较少的训练数据就可以把结果训练好。
如果要分出长发女、长发男、短发女、短发男,长发男的样本明显要少一些。此时做分类,先将他们分成男生和女生在进行长发短发的分类比直接进行四种的分类准确率明显要高很多。相当于加了一个基础的分类器。后面的分类器可以利用前面的结果,所以它就可以用比较少的训练数据就可以把结果训练好。
深度学习和模块化
深度学习和模块化有什么关系?
在做deep learning的时候,如何做模组化这件事,是机器自动学到的。
做modularization这件事,把我们的模型变简单了(把本来复杂的问题变得简单了),把问题变得简单了,就算训练数据没有那么多,我们也就可以把这个做好
模块化
使用语音识别举例: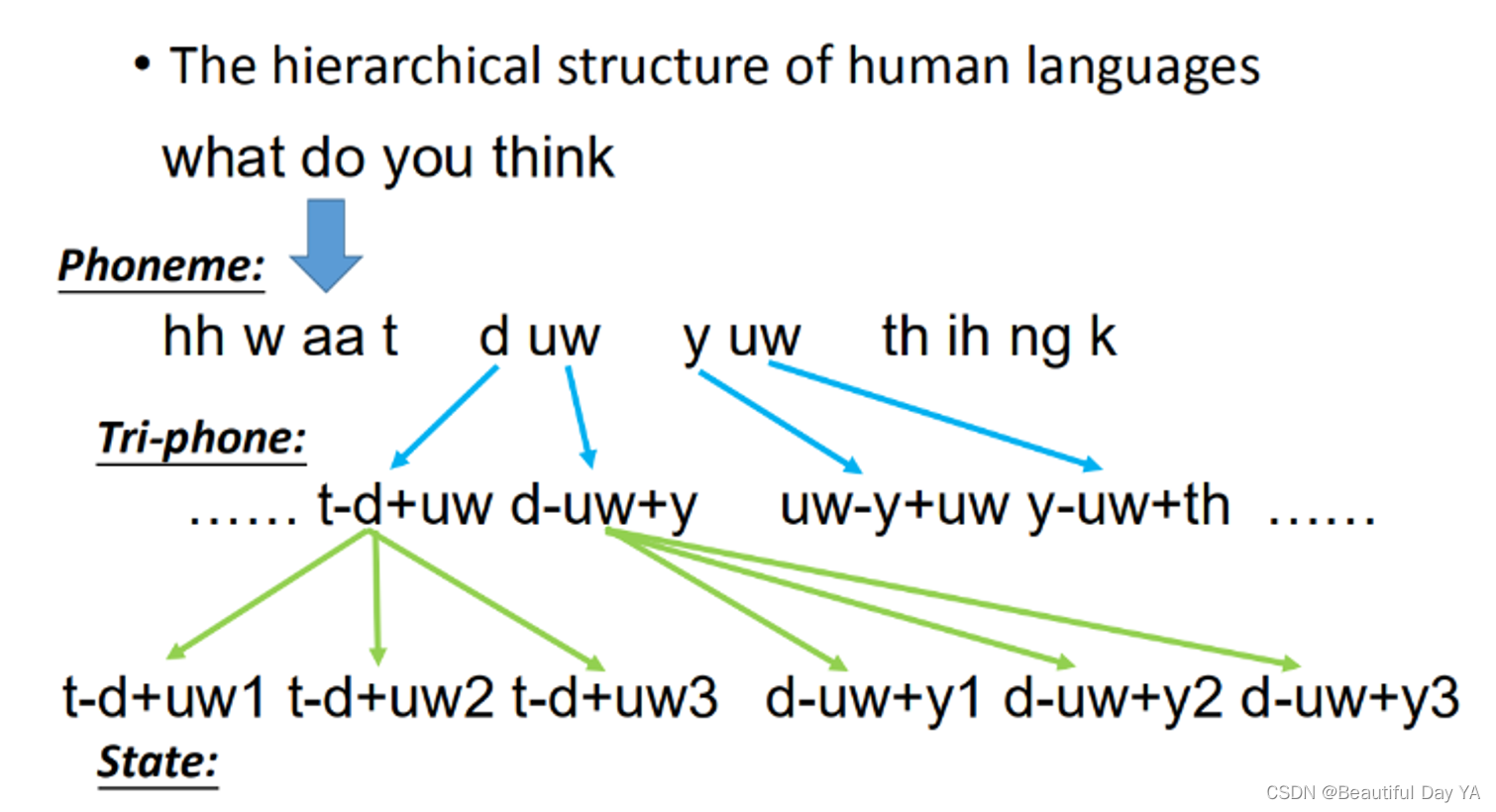
首先当你说一句:1. what do you think,这句话其实就是由一组phoneme(音素)所组成的。2. 同样的phoneme可能会有不太一样的发音,因为人类发音口腔器官的限制,你的phoneme发音会受到前后的影响。为了表达这件事情,我们会给同样的phoneme不同的model,这就是Tri-phone。现在一个phoneme用不同的model来表示,一个phoneme它的constant phone不一样,我们就要不同model来模拟描述这个phoneme。3. 一个phoneme可以拆成几个state,state有几个通常自己定义,通常就定义为三个state
语音辨识: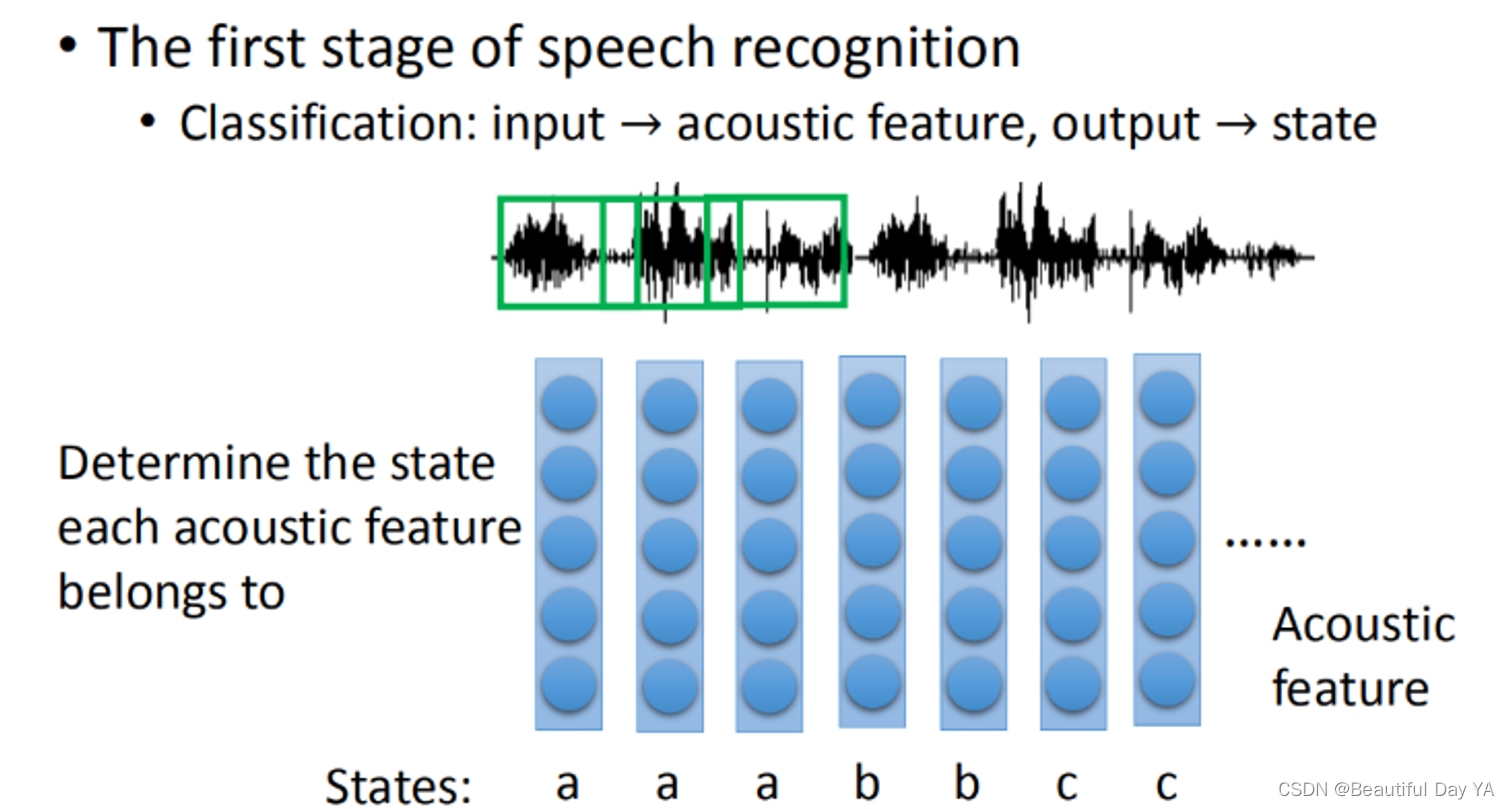
语音辨识特别的复杂:第一步要做的事情就是把acoustic feature(声音讯号发生一段wave phone,这个wave phone通常取一段window(这个window通常不是太大)。一个window里面就用一个feature来描述里面的特性,那这个就是一个acoustic feature)转成state;在语音辨识的第一阶段,你需要做的就是决定了每一个acoustic feature属于哪一个state。把state转成phone,phoneme,在把phoneme转成文字,接下来考虑同音异字的问题
👉🏻对比传统的语音识别和深度学习的实现方法
传统的语音识别HMM-GMM(GNN)
首先,假设每一个state都是有固定的分布还有对应的概率,不同的state有不同的GNN对应;可想而知参数十分多。接着人们想到有一些state,让他们共用同一个model distribution,但是分的就会很粗糙。所以就有人开始提一些想法:如何让它部分共用等等
所以DNN更有效率而且效果更好
深度学习的实现方法DNN
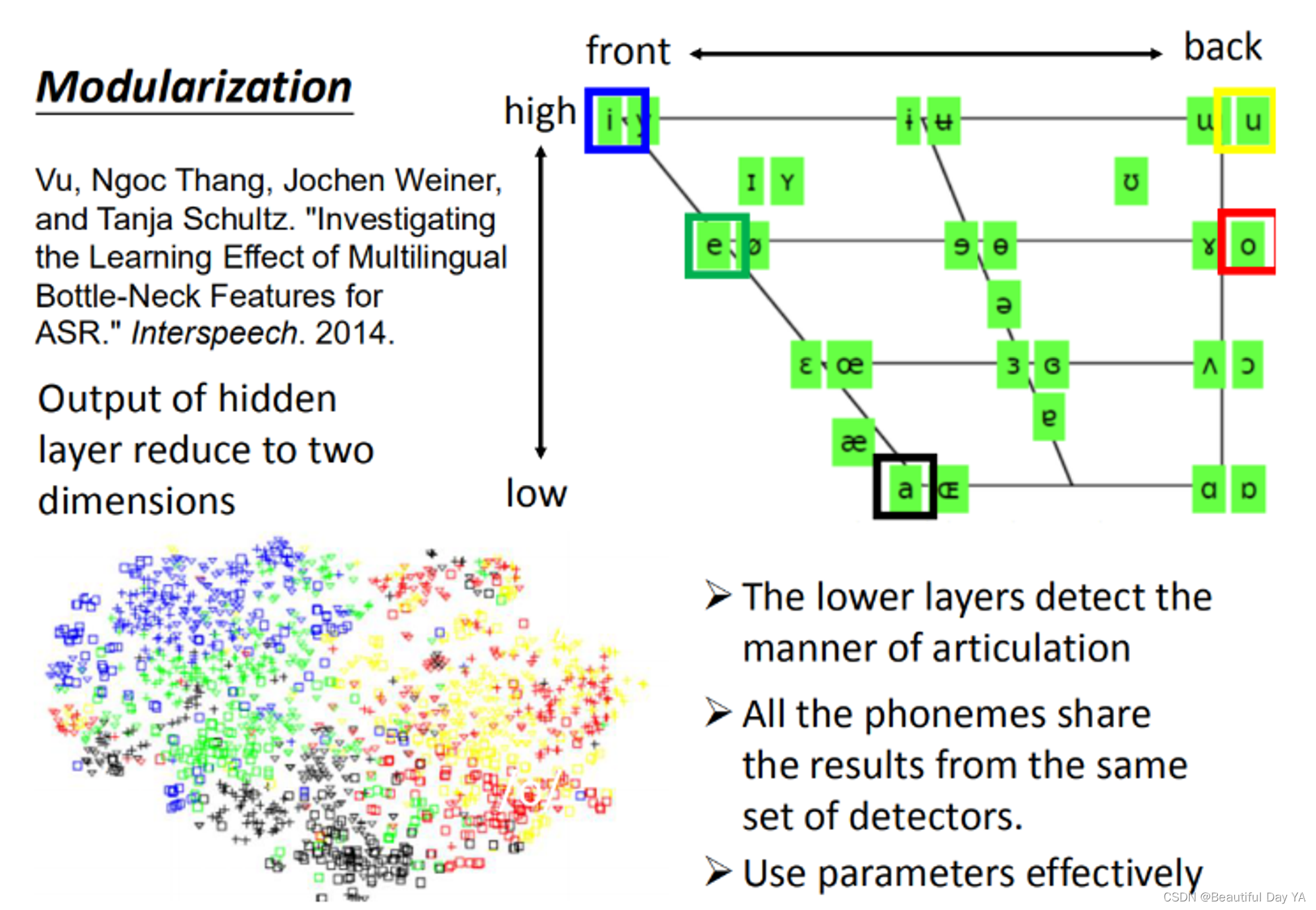
前面的layer先学习到发音的方式(发音时舌头的位置)以后接下来的layer在根据这个结果去说现在的发音是属于哪个state/phone

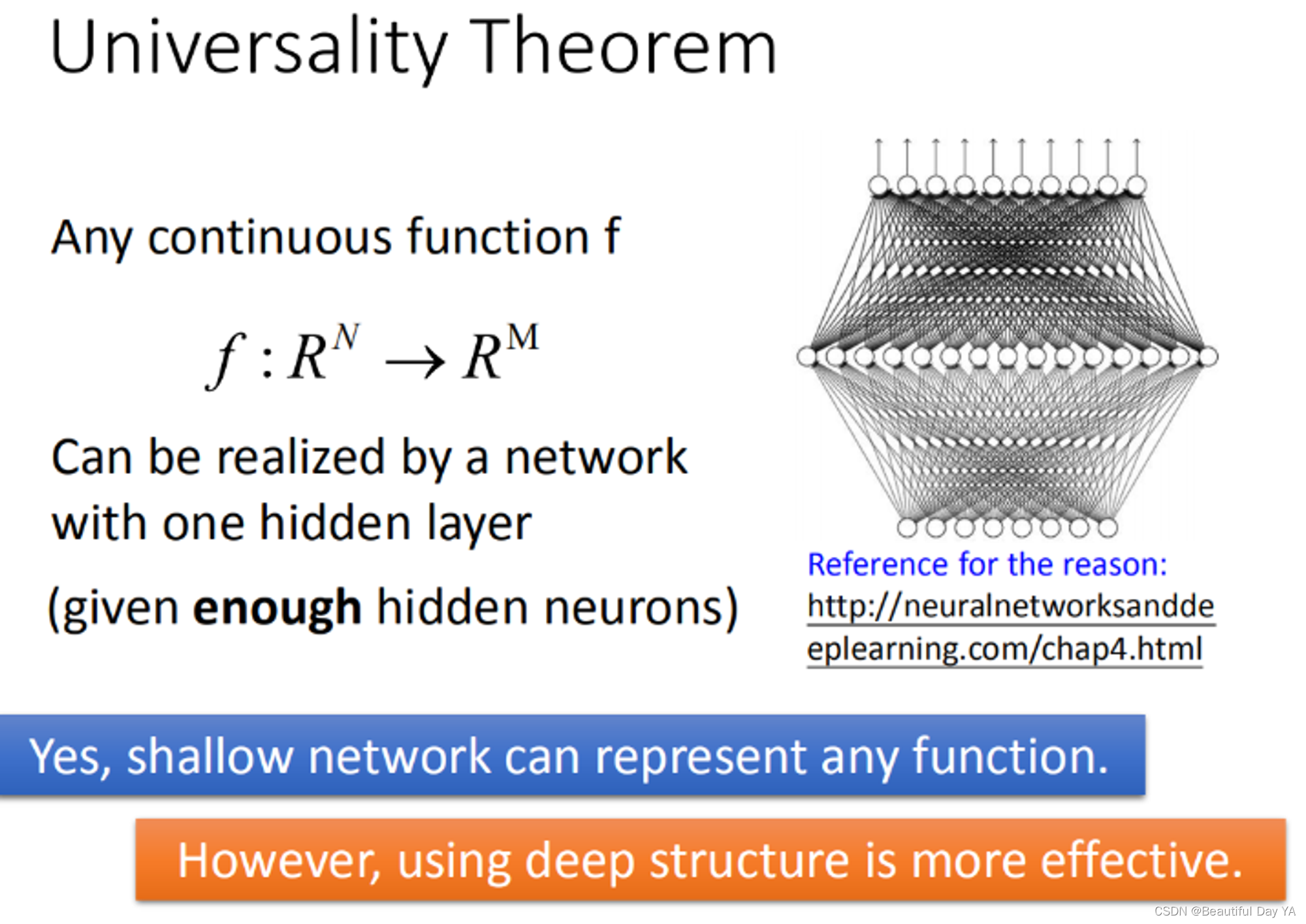
普遍性定理
💚 过去有一个理论告诉我们说,任何continuous function,它都可以用一层neural network来完成(只要那一层只要够宽的话)。
所以那时候多人说做deep是很没有必要的,但是它只告诉我们可能性,但是它没有告诉我们说要做到这件事情到底有多有效率。没错,当你有more layer(high structure)你用这种方式来描述你的function的时候,它是比较有效率的。
类比举例
1️⃣逻辑电路(logistic circuits)跟neural network可以类比。
逻辑电路中其实只要两层逻辑闸你就可以表示任何的Boolean function
同样有一个hidden layer的neural network以表示任何的continue function。
但实际上你在做电路设计的时候,你根本不可能只做两层逻辑闸,因为那样毫无效率。对于neural network也是多层可以用较少的参数完成同样的功能比较少的参数意味着不容易overfitting或者你其实是需要比较少的data进行训练
2️⃣剪窗花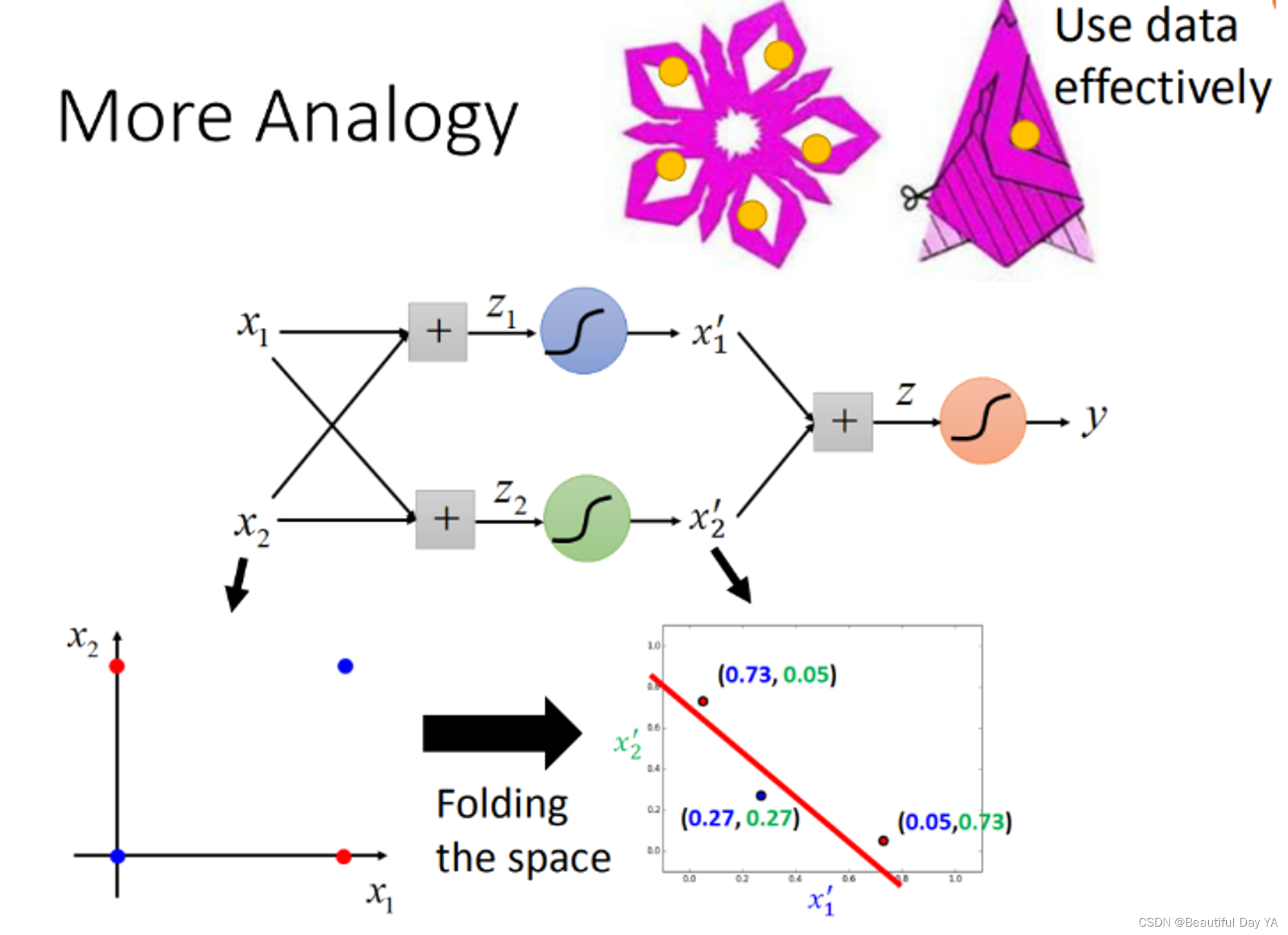
这个例子来看,一笔data,就可以发挥五笔data效果。所以,你在做deep learning的时候,你其实是在用比较有效率的方式来使用你的data
3️⃣使用二位坐标进行举例
端到端的学习
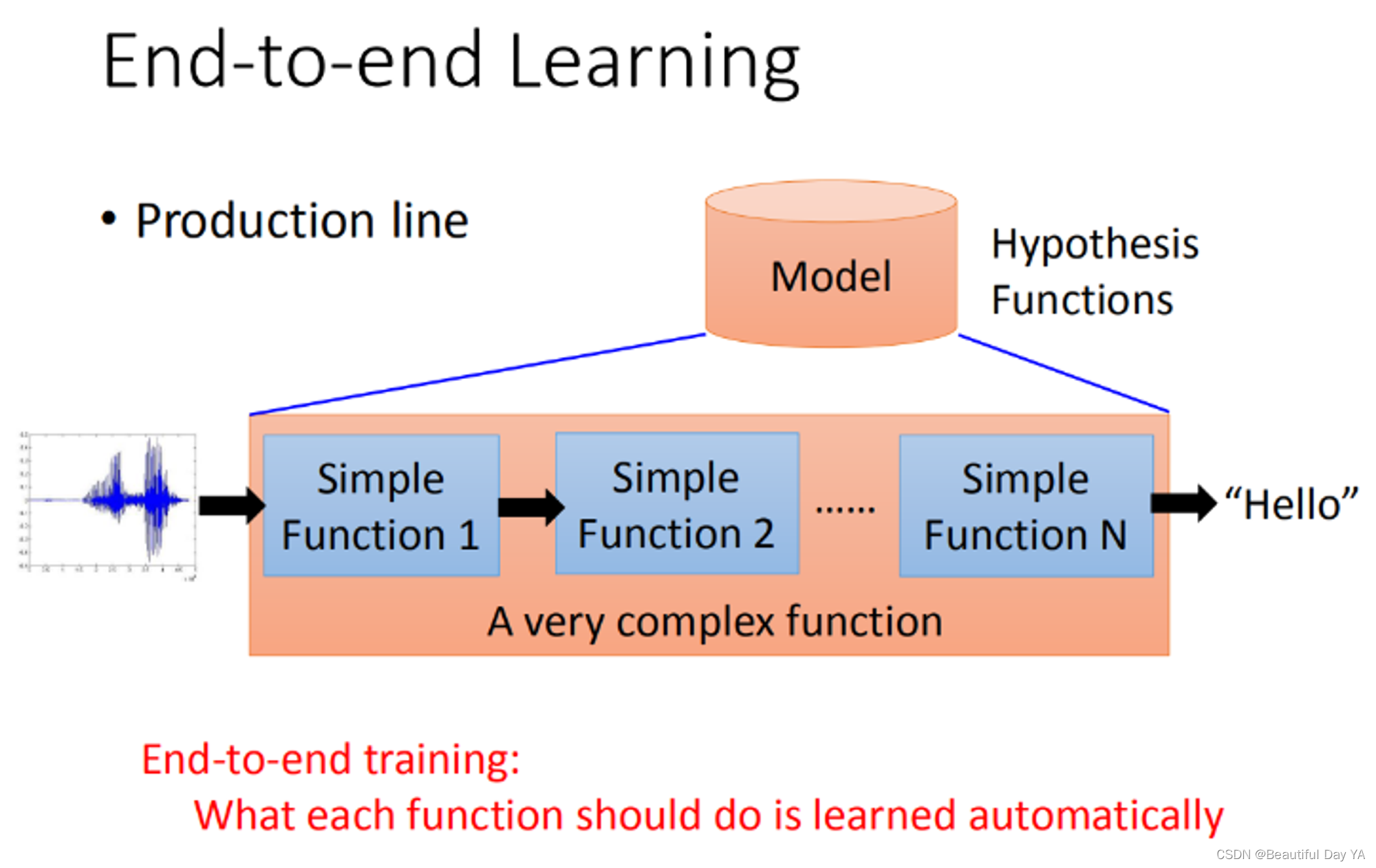
End-to-end learning,意思就是说你只给你的model input跟output,你不告诉它说中间每一个function要咋样分工(只给input跟output,让它自己去学),让它自己去学中间每一个function(生产线的每一个点)应该要做什么事情。现在的deep learning就是每一层就会学到说自己要做什么样的事情。
1️⃣语音识别:
原来的语音识别只有最后的HMM时数据训练出来的,前面的都是人为定的,现在用neural network把它取代掉,它可以自己学习到怎么做。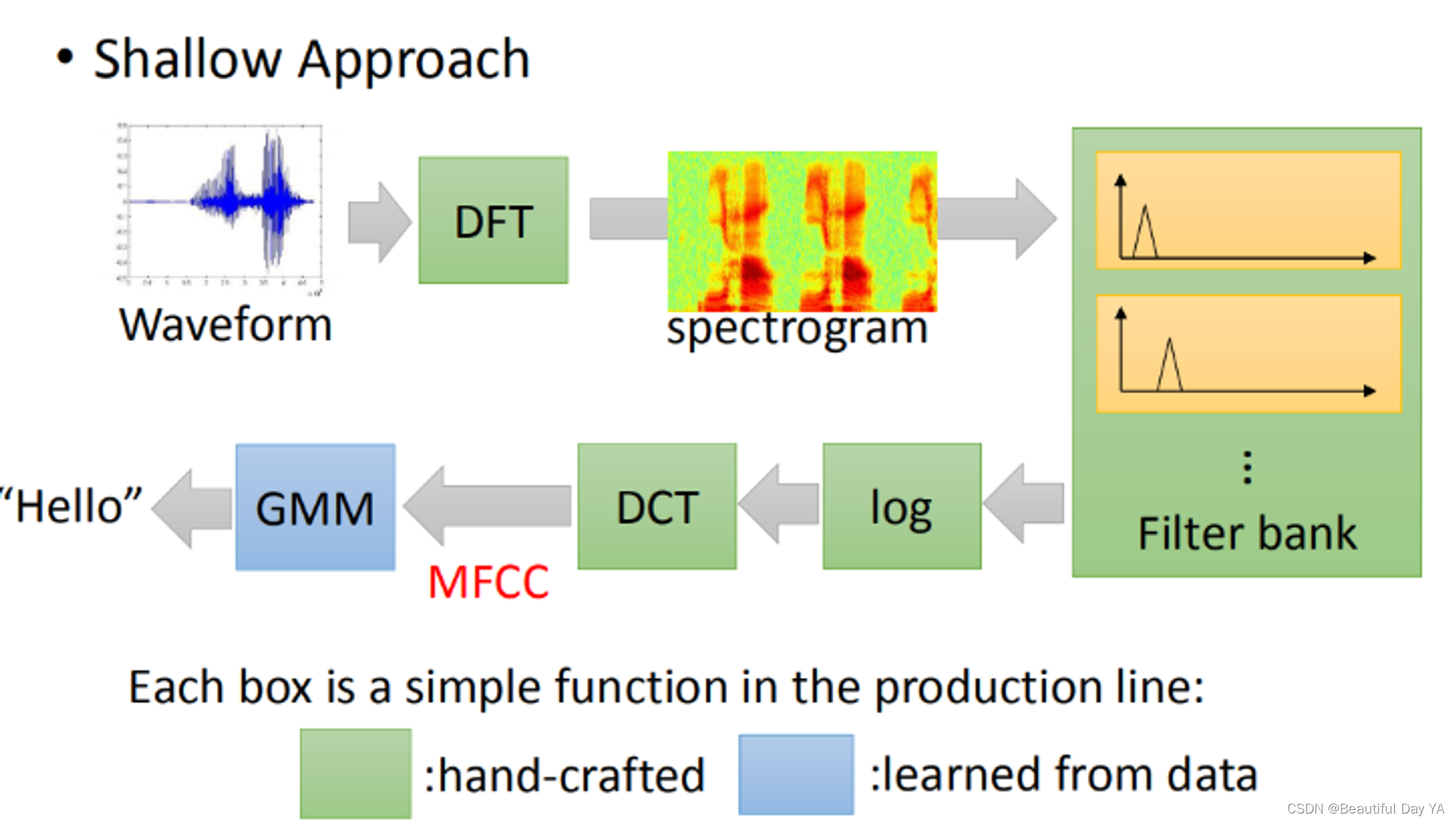
初始语音识别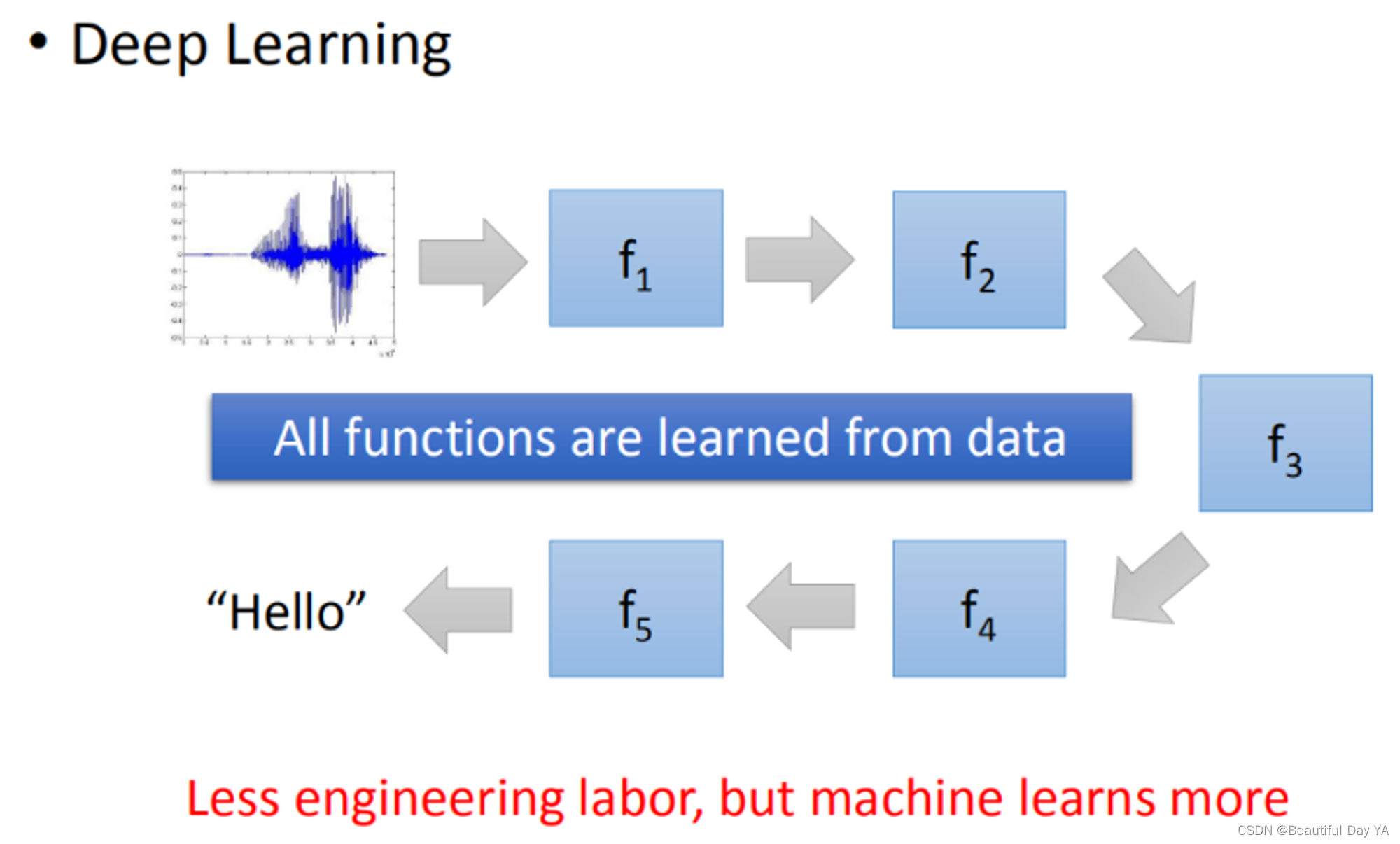
现在的语音识别DNN
2️⃣图像识别
过去影像也是手动叠很多很多的graph在最后一层用比较简单的classifier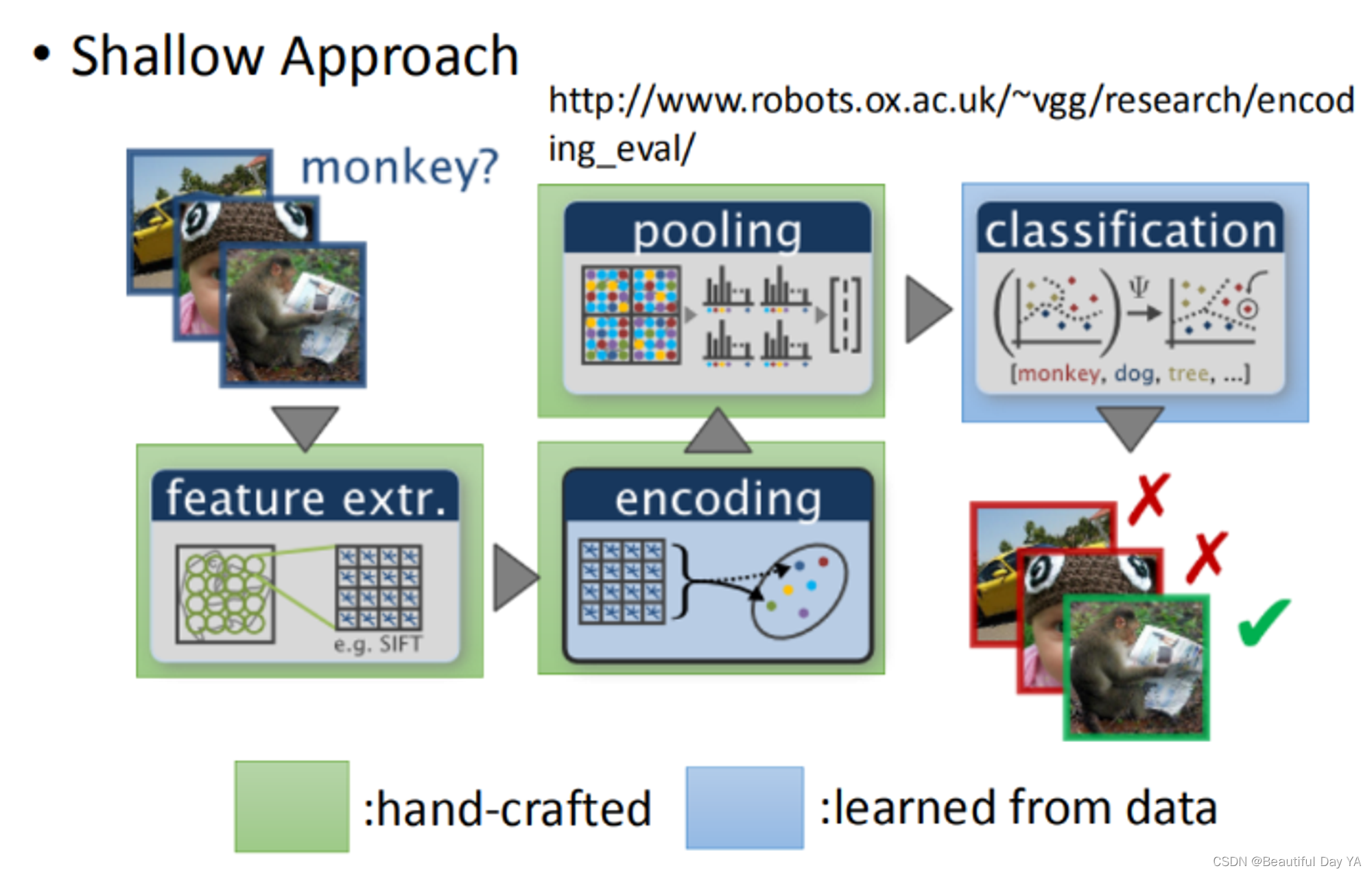

3️⃣更复杂的任务
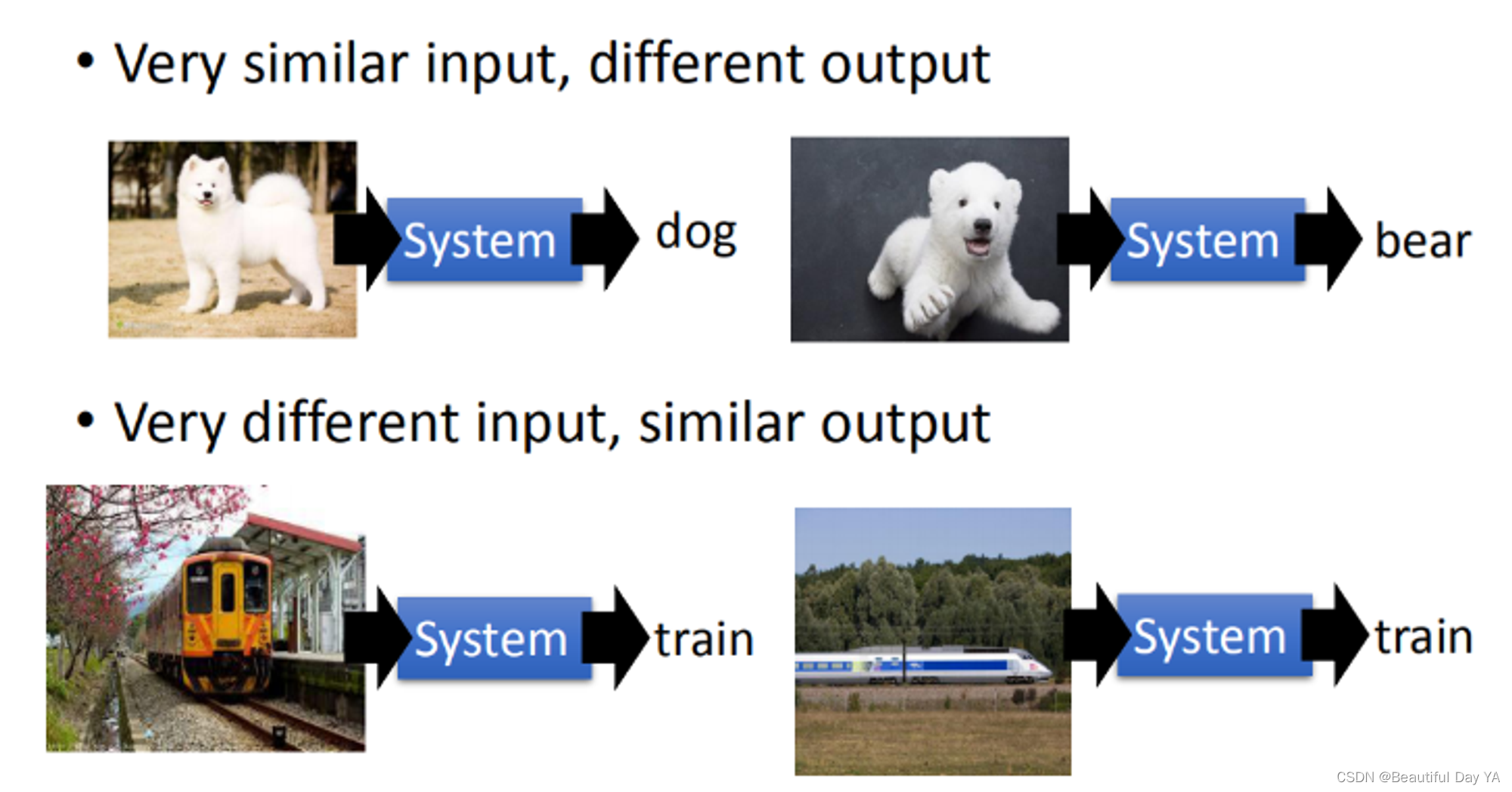
原来input很像的东西结果看起来很不像,把不一样的东西变的很像,你要做很多层次的转换。这也是deep learning做的
左下方手写数字辨识的例子原始4跟9几乎是叠在一起的(4跟9很像,几乎没有办法把它分开)。但是当层数边多原来很像的input 最后要分的很开。
 |  |















 5万+
5万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









