









中科大:一种用于野外面部表情识别的统一视觉语言框架
论文链接:https://arxiv.org/pdf/2303.00193.pdf
学术分享,如若侵权,联系删除~
疑问记录:METD学习到的文本描述词是来源于某种文本库吗?
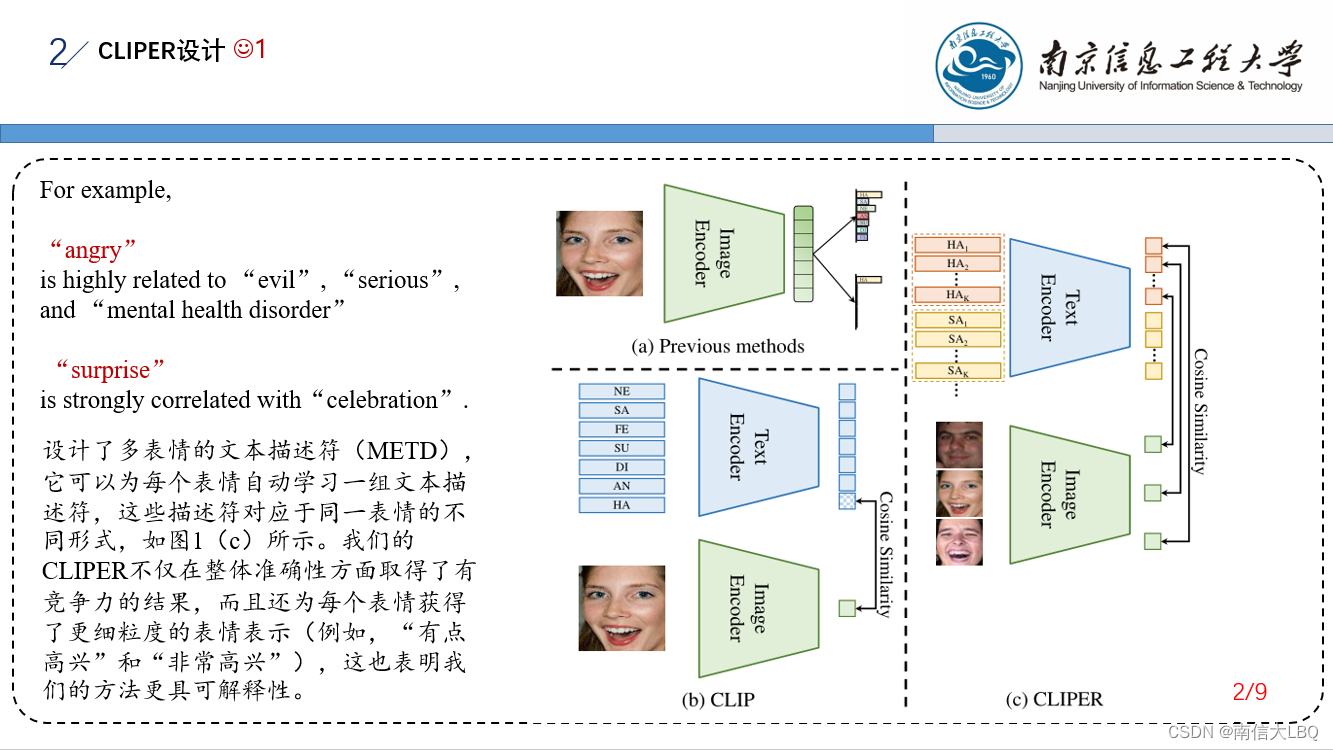
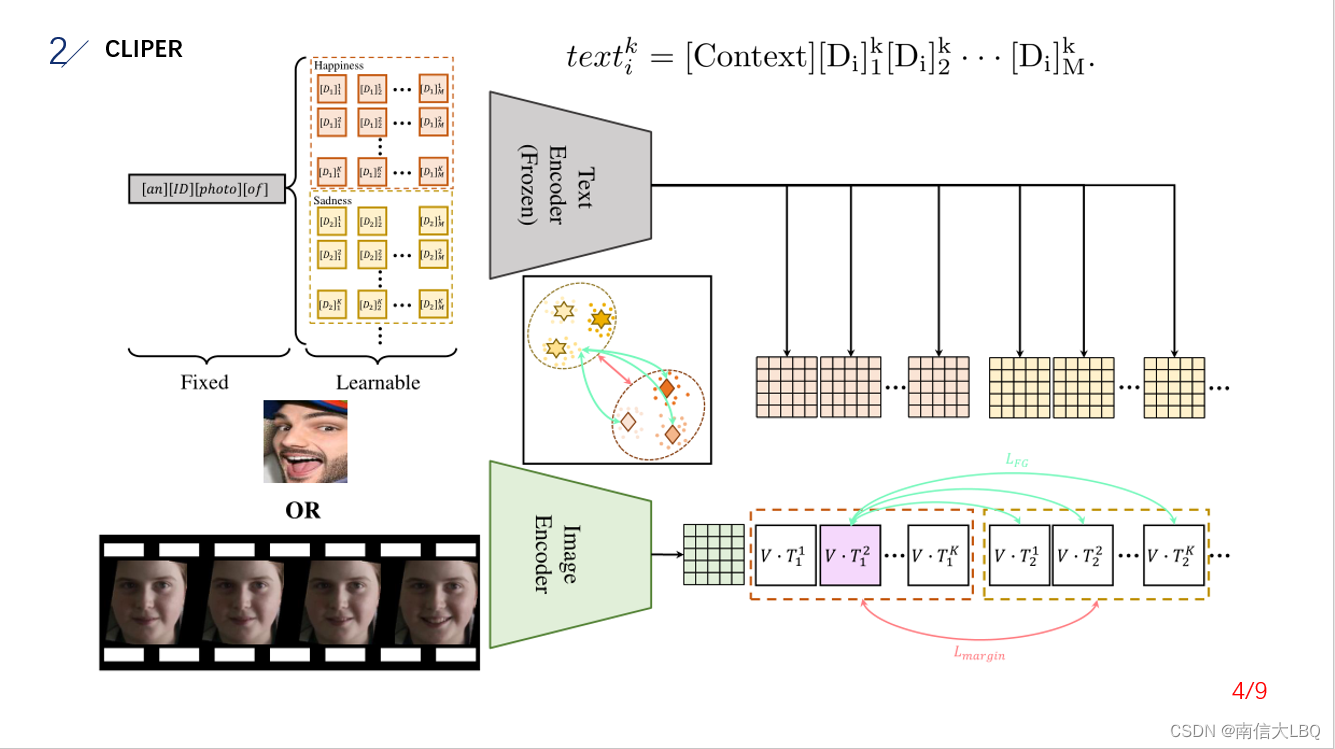
阅读提示:METD学习过程中,Text Encoder和Image Encoder参数固定,所以文本单词和图片都可以在空间中得到固定映射。学习METD的过程就是匹配空间中的单词token和图片token的过程,有点类匹配对齐的含义,或者理解为将表情图片产生的超类作为C个聚类核心点,将单词作为待聚类的点的含义。最终,表情图片的C个超类附近,都各自聚集了M个子类,每个子类包括K个点即K个单词。
PPT简述:
























 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









