









1.什么是图?
在一个社交网络中,每个帐号和他们之间的关系构成了一张巨大的网络,就像下面这张图:

那么在电脑中,我们要用什么样的数据结构来保存这个网络呢?这个网络需要用一个之前课程里未提到过的数据结构,也就是接下来要讲解的图结构来保存。
到底什么是图?图是由一系列顶点和若干连结顶点集合内两个顶点的边组成的数据结构。数学意义上的图,指的是由一系列点与边构成的集合,这里我们只考虑有限集。通常我们用 G=(V,E) 表示一个图结构,其中 V 表示点集,E 表示边集。
在顶点集合所包含的若干个顶点之间,可能存在着某种两两关系——如果某两个点之间的确存在这样的关系的话,我们就在这两个点之间连边,这样就得到了边集的一个成员,也就是一条边。对应到社交网络中,顶点就是网络中的用户,边就是用户之间的好友关系。
如果用边来表示好友关系的话,对于微信这种双向关注的社交网络没有问题,但是对于微博这种单向关注的要如何表示呢?
于是引出了两个新的概念:有向边和无向边。
简而言之,一条有向边必然是从一个点指向另一个点,而相反方向的边在有向图中则不一定存在;而有的时候我们并不在意构成一条边的两个顶点具体谁先谁后,这样得到的一条边就是无向边。就像在微信中,A 是 B 的好友,那 B 也一定是 A 的好友;而在微博中,A 关注 B 并不意味着 B 也一定关注 A。
对于图而言,如果图中所有边都是无向边,则称为无向图,反之称为有向图。
实际上,无向图可以由有向图来表示。如果 AB 两个点之间存在无向边的话,那用有向图也可以表示为:AB 两点之间同时存在 A 到 B 与 B 到 A 两条有向边。
一些有向图的例子:
1.生物学中的由食物链构成的食物网
2.程序的函数依赖图
3.微博的用户关系图
2.图的常用概念:
这一节课我们来学习图的几个常用概念。有很少边或弧(如 e < nlogn,e 指边数,n 指点数)的图称为稀疏图,反之称为稠密图。对应到微博里,如果在一个圈内,大家都互相关注,则我们可以认为该关系图是一个稠密图,如果只有几个人关注了别人,则我们可以认为这是一个稀疏图。
顶点的度是指依附于某个顶点的边数。
注意在有向图中对度有不同的描述:
在有向图中,我们需要学习顶点的入度和出度这两个概念。顶点的入度是指以顶点为弧头的弧的数目,也就是以该顶点为终点的弧的数目;顶点的出度是指以顶点为弧尾的弧的数目,也就是以该顶点为起点的弧的数目。需要注意的是,在有向图里,顶点的度为入度与出度之和。
例如:在有向图里,已知一个顶点的入度为 3,出度为 4,则该顶点的度为 7
图论中一个非常重要的定理:
握手定理:在图里,图的边数等于所有顶点度数和的一半(有向图和无向图均适用)
此定理引申出的推论:
握手定理的推论 任何图(无向的或有向的)中,奇度顶点的个数是偶数。
3.图的存储
图的两种常见的存储结构——邻接矩阵和邻接表。
(1).邻接矩阵
邻接矩阵存储结构就是用一维数组存储图中顶点的信息,用矩阵表示图中各顶点之间的邻接关系。
有向图以及无向图的实例:
对于有n个顶点的有向图G=(V,E)来说,我们可以用一个n*n的矩阵 A 来表示图G中各顶点的相邻关系
如果Vi和Vj之间存在边(或弧),则 A[i][j] = 1,否则 A[i][j] = 0。
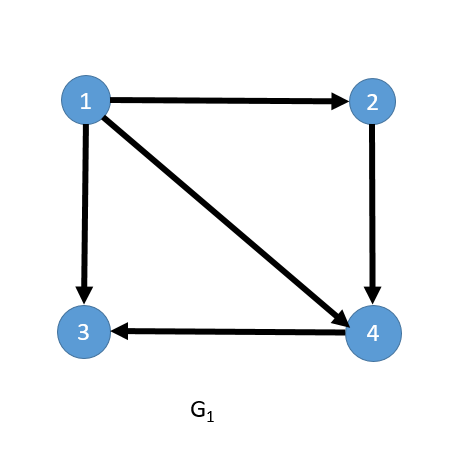
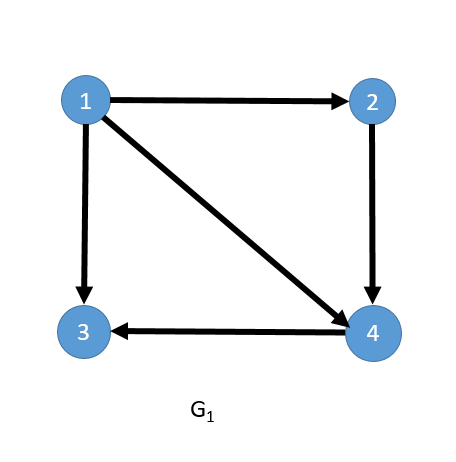
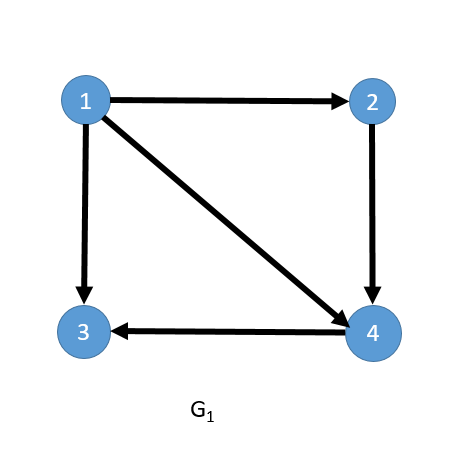
下图为有向图 G1 以及对应的邻接矩阵。

下图为无向图 G2以及对应的邻接矩阵。
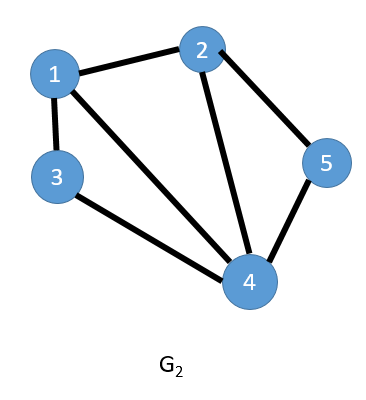
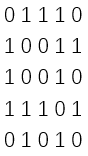
图的邻接矩阵是唯一的,矩阵的大小只与顶点个数 N 有关,是一个 N∗N 的矩阵。前面我们已经介绍过,在无向图里,如果顶点 vi 和 vj 之间有边,则可认为顶点 vi到 vj有边,同时顶点 vj到 vi也有边。对应到邻接矩阵里,则有 A[i][j]=A[j][i]=1。因此我们可以发现,无向图的邻接矩阵是一个对称矩阵。
在邻接矩阵上,我们可以直观的看出两个顶点之间是否有边(或弧),并能容易求出每个顶点的度,入度和出度。
这里我们以上图 G1 为例,演示下如何利用邻接矩阵计算顶点的入度和出度。顶点的出度,即为邻接矩阵上点对应行上所有值的总和,比如顶点 1 对应的出度即为 0+1+1+1=3;而每个点的入度即为点对应列上所有值的总和,比如顶点 3对应的入度即为 1+0+0+1=2。
邻接矩阵的优缺点:
优点:邻接矩阵存储结构最大的优点就是简单直观,易于理解和实现。其适用范围广泛,有向图、无向图、混合图、带权图等都可以直接用邻接矩阵表示。另外,对于很多操作,比如获取顶点度数,判断某两点之间是否有连边等,都可以在常数时间内完成。
缺点:对于一个有 n 个顶点的图,邻接矩阵总是需要 n2 的存储空间。当边数很少的时候,就会造成空间的浪费。
(2).邻接表
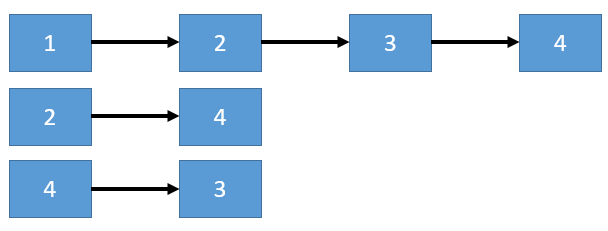
在无向图的邻接表中,顶点 vi 的度为第 i 个单链表中的结点数;而在有向图中,第 i 个单链表中的结点数表示的是顶点 vi的出度,如果要求入度,则要遍历整个邻接表。
具体使用哪一种存储方式,要根据图的特点来决定:如果是稀疏图,我们一般用邻接表来存储,这样可以节省空间;
如果是稠密图,考虑到邻接表中要附加链域,我们一般用邻接矩阵来存储。
4.邻接矩阵和邻接表的构造与使用代码实现:
(1).邻接矩阵
在实际应用中,如果所需空间不是非常大的话,则可以直接声明一个二维数组用来存储图的各顶点之间的邻接关系。
在这里,示例一种用二级指针实现的办法(C++实现):
/*针对有向图的邻接矩阵的存储方式,对于有n个顶点的有向图G=(V,E)来说,我们可以用一个n*n的矩阵 A 来表示图G中各顶点的相邻关系
*如果Vi和Vj之间存在边(或弧),则 A[i][j] = 1,否则 A[i][j] = 0。
*/
#include <iostream>
#include <cstring>
using namespace std;
class Graph {
private:
int **mat; //邻接矩阵,mat是二级指针,mat是指向指针的指针
int n;
public:
Graph(int input_n) {
n = input_n; //n表示顶点个数
mat = new int*[n]; //mat初始化指向总共有n个元素的指针数组
for (int i = 0; i < n; ++i) {
mat[i] = new int[n]; //mat[i] = *(mat+i),初始化每一列
memset(mat[i], 0, sizeof(int) * n); //初始化
}
}
~Graph() {
for (int i = 0; i< n; ++i) {
delete[] mat[i]; //先删除指针数组中每一个指针指向的列元素
}
delete[] mat; //然后再删除mat指向的指针数组
}
void insert(int x, int y) {
mat[x][y] = 1; //对于有向图,表示有向图中增加了一条由x→y的有向边
}
void output() {
for(int i = 0;i < n;++i){
for(int j = 0;j < n;++j){
cout << mat[i][j] << " "; //顶点i和j之间是否含有边
}
cout << endl;
}
}
};
int main() {
int n, m, x, y;
cin >> n >> m;
Graph g(n);
for (int i = 0; i < m; ++i) {
cin >> x >> y;
g.insert(x, y);
}
g.output();
return 0;
}
#include <iostream>
using namespace std;
//链表的节点类,用于存储每个链表的节点信息
class LinkedListNode {
public:
int vertex;
LinkedListNode *next;
LinkedListNode(int vertex_input) {
vertex = vertex_input;
next = NULL;
}
};
//链表类,为图的每个顶点建立起一个单链表
class LinkedList {
public:
LinkedListNode *head;
LinkedList() {
head = NULL;
}
~LinkedList() {
while (head != NULL) {
LinkedListNode *delete_node = head;
head = head->next;
delete delete_node; //销毁整个链表
}
}
void insert(int vertex) { //每次读入新的边时,将新的边y作为顶点x单链表的头结点,这样的话简化了
//记录新的邻接边的过程(不用每次都循环到链表的尾部),因为在记录顶点x邻接边时是与顺序无关的
LinkedListNode *node = new LinkedListNode(vertex);
node->next = head;
head = node;
}
};
class Graph {
private:
LinkedList *edges; //声明一个指向LinkedList类的指针
int n;
public:
Graph(int input_n) {
n = input_n;
edges = new LinkedList[n]; //edges指向n个LinkedList类型的数组,表示为图的每个顶点都建立起一个单链表
}
~Graph() {
delete[] edges;
}
void insert(int x, int y) {
edges[x].insert(y);
}
void output() {
for(int i = 0;i < n;++i){
cout << i << ":";
for(auto j = edges[i].head;j != NULL;j = j -> next){
cout << j -> vertex << " ";
}
cout << endl;
}
}
};
int main() {
int n, m, x, y;
cin >> n >> m;
Graph g(n);
for (int i = 0; i < m; ++i) {
cin >> x >> y;
g.insert(x, y);
}
g.output();
return 0;
}
邻接表效果示意图:
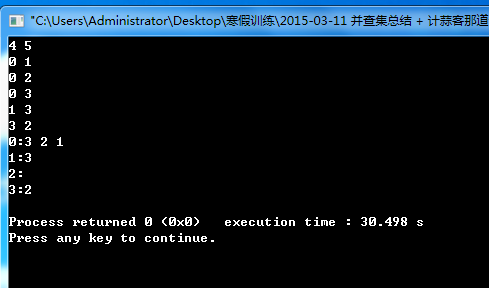
总结:图论是数据结构以及计算机科学中非常重要的知识,要多回顾,多练习。
如有错误,还请指正,O(∩_∩)O谢谢















 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









