







注意力机制(Attention Mechanism)的类型
注意力机制是深度学习中的重要概念,最初用于神经机器翻译,如今广泛应用于自然语言处理(NLP)、计算机视觉和语音处理等领域。以下是常见的几类注意力机制:
1. 基本注意力机制(Vanilla Attention)
最早由Bahdanau等人在2014年提出,称为Bahdanau Attention或加性注意力(Additive Attention)。其核心思想是通过计算输入序列中每个位置与当前目标的相关性,生成注意力权重。
原理:
- 使用一个可训练的神经网络计算注意力得分(alignment score)。
- 得分通过softmax函数归一化为权重,再加权求和生成上下文向量。
公式:

应用:
- 机器翻译中的序列到序列(Seq2Seq)模型。
2. 点积注意力(Dot-Product Attention)
又称为缩放点积注意力(Scaled Dot-Product Attention),是Transformer模型中使用的注意力机制。其核心思想是通过计算查询(Query)与键(Key)之间的点积,衡量它们的相似性。
原理:
- 将查询向量 (Q)、键向量 (K) 和值向量 (V) 输入注意力机制。
- 计算 (Q) 和 (K) 的点积,再除以 (\sqrt{d_k}) 进行缩放,最后通过softmax生成权重。
公式:
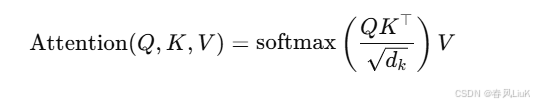
优势:
- 计算高效,适合并行处理。
应用:
- Transformer、BERT、GPT等模型。
3. 多头注意力(Multi-Head Attention)
多头注意力机制是Transformer中的重要创新。它通过多组独立的注意力头从不同的子空间中学习不同的关系,从而增强模型的表达能力。
原理:
- 将输入的查询、键、值分别映射到多个子空间,每个子空间计算一次注意力。
- 将所有头的输出拼接后,再通过线性变换得到最终输出。
公式:
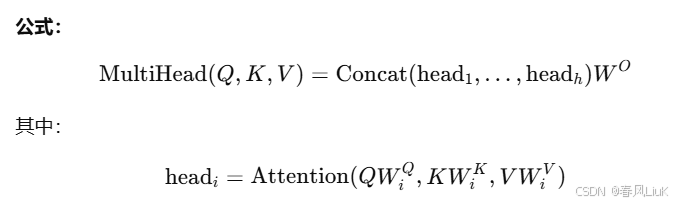
优势:
- 能同时捕获多个层次的特征,提高模型的表达能力。
4. 自注意力(Self-Attention)
自注意力又称为内部注意力(Intra-Attention),用于序列内部的各位置间计算注意力。它让每个位置能够关注序列中的其他位置,捕获全局依赖关系。
原理:
- 对输入序列自身计算注意力,使每个位置的信息融合其他位置的信息。
公式:
与点积注意力公式一致,计算输入序列中每个位置的注意力。
应用:
- Transformer模型的核心机制。
5. 软注意力与硬注意力(Soft Attention & Hard Attention)
5.1 软注意力(Soft Attention)
原理:
软注意力通过为所有输入位置生成一个概率分布,将所有位置的值加权求和来生成上下文向量。它是连续可微的,因此可以使用反向传播进行训练。其核心思想是为每个位置分配权重,权重的总和为1。
公式:

特点:
- 可微,适用于反向传播。
- 应用于大多数自然语言处理(NLP)任务,如机器翻译、文本摘要。
5.2 硬注意力(Hard Attention)
原理:
硬注意力只选择部分位置(通常是一个位置)进行关注,而不是为每个位置分配一个概率权重。它是非连续可微的,因此需要通过强化学习或其他非梯度方法进行训练。
公式:
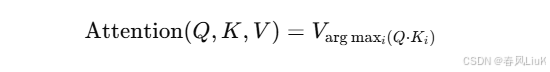
硬注意力选择与查询最相关的位置 (i),并直接返回该位置的值。
特点:
- 非可微,需要强化学习方法,如策略梯度或蒙特卡罗方法进行优化。
- 通常用于视觉任务,如图像中的目标检测或聚焦特定区域。
6. 层次注意力(Hierarchical Attention)
原理:
层次注意力首先在较低级别(如词级别)计算注意力权重,然后在更高级别(如句子级别)计算注意力。这样可以逐层提取不同粒度的上下文信息。
公式:
-
词级注意力:
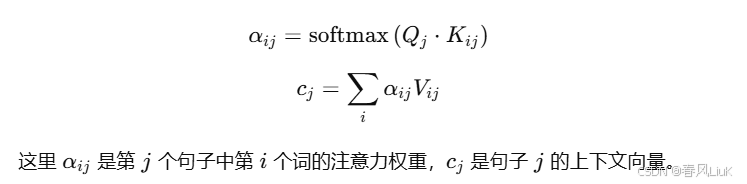
-
句级注意力:

应用:
- 文档分类、文本摘要任务中常用。
7. 记忆网络中的注意力(Memory Networks Attention)
原理:
在端到端记忆网络中,注意力机制用于选择存储在外部记忆中的相关信息。模型根据输入查询选择与其最相关的记忆单元,并提取相应的内容。
公式:

应用:
- 问答系统、语言建模。
8. 时空注意力(Spatio-Temporal Attention)
原理:
时空注意力同时考虑时间维度和空间维度的注意力。它在处理视频或其他时空序列数据时,可以分别计算时间轴上的注意力权重和空间上的注意力权重,从而捕捉动态变化和空间特征。
公式:
-
时间注意力:

-
空间注意力:

应用:
- 视频分类、动作识别等任务。

















 1056
1056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









