









摘要:
在注意力机制中,多层的作用通常指的是将注意力机制堆叠在多个层上,这在深度学习模型中被称为“深度”或“多层”注意力网络。通过这种设计,每一层都在前一层的基础上提炼和组合特征,形成更加高级的表示。残差连接和层归一化确保了信息可以有效地在多层之间传递,同时避免了梯度消失的问题。这种多层结构使得注意力模型能够捕捉序列数据中的长距离依赖关系,极大地提高了模型的性能。
1.多层的作用
在注意力机制中,多层的作用通常指的是将注意力机制堆叠在多个层上,这在深度学习模型中被称为“深度”或“多层”注意力网络。这种多层结构的作用和实现过程如下:
-
逐层抽象:每一层都可以捕捉到输入数据的不同层次的特征和上下文信息。较低层次可能捕捉到更细节的信息,而较高层次可能捕捉到更抽象、更全局的上下文信息。
-
增强表达能力:通过多层结构,模型能够学习到更加复杂和丰富的数据表示。每一层都可以在前一层的基础上进一步提炼和组合特征,形成更高级的表示。
-
逐步注入上下文信息:在每一层中,注意力机制都会计算一个上下文向量,该向量是输入序列的加权表示,其中权重由查询向量和键向量之间的相似性决定。在多层注意力网络中,这个过程会重复进行:
- 在第一层,模型计算得到初步的上下文向量。
- 第二层的输入是第一层的输出,再次应用注意力机制,进一步提炼上下文信息。
- 这个过程在所有层中重复,每一层都在前一层的基础上进一步注入上下文信息。
-
实现过程:在实际操作中,每一层的注意力机制都使用自己的参数(即自己的查询、键和值矩阵 \( W^Q \),\( W^K \),和 \( W^V \))。输入数据在每一层中都会被转换成查询、键和值,然后通过标准的注意力计算过程生成上下文向量,该向量作为下一层的输入。
-
信息流动:在多层注意力网络中,信息在层间的流动是通过上层的注意力机制对下层的输出进行加权求和来实现的。这样,每一层都能够在不同程度上关注输入序列的不同部分,并将这些关注点逐步传递到模型的深层。
-
训练过程:在训练多层注意力网络时,所有的层都是联合训练的。通过反向传播算法,从最后一层开始,梯度会依次传递到前面的每一层,更新每一层的参数。
通过这种多层结构,注意力模型不仅能够捕捉局部的上下文信息,还能够建立跨较远距离的依赖关系,这是处理长序列数据和复杂任务的关键能力。
2.数学描述
在多层注意力模型中,每一层都建立在前一层的基础上,逐步提炼和组合特征。这个过程可以通过以下数学描述来理解:
假设我们有一个序列 \( X \),它将通过 \( L \) 层注意力机制进行处理。每一层 \( l \) 的处理包括以下几个步骤:
第 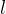 层的自注意力机制:
层的自注意力机制:
1. **计算查询(Query)、键(Key)、值(Value)**:
\[ Q_l = X_{l-1}W^{Q}_l \]
\[ K_l = X_{l-1}W^{K}_l \]
\[ V_l = X_{l-1}W^{V}_l \]
其中,\( X_{l-1} \) 是第 \( l-1 \) 层的输出,\( W^{Q}_l \),\( W^{K}_l \),和 \( W^{V}_l \) 是第 \( l \) 层的可训练权重矩阵。
2. **计算注意力分数**:
\[ \text{score}_{ij}^l = Q_{li} K_{lj}^T \]
这里,\( \text{score}_{ij}^l \) 表示第 \( l \) 层中,第 \( i \) 个查询和第 \( j \) 个键之间的相似度分数。
3. **缩放点积注意力**:
\[ \text{score}_{ij}^{\text{scaled}, l} = \frac{\text{score}_{ij}^l}{\sqrt{d_k}} \]
其中,\( d_k \) 是键向量的维度。
4. **归一化注意力分数**:
\[ \alpha_{ij}^l = \frac{\exp(\text{score}_{ij}^{\text{scaled}, l})}{\sum_{j=1}^{n}\exp(\text{score}_{ij}^{\text{scaled}, l})} \]
这里,\( \alpha_{ij}^l \) 是归一化后的注意力权重,通过softmax函数计算得到。
5. **计算上下文向量**:
\[ C_{li}^l = \sum_{j=1}^{n} \alpha_{ij}^l V_{lj} \]
对于序列中的每个查询 \( i \),\( C_{li}^l \) 是通过注意力权重 \( \alpha_{ij}^l \) 加权的值 \( V_{lj} \) 的和。
6. **输出层**:
\[ O_{l} = C_{l}W^{O}_l \]
其中,\( W^{O}_l \) 是第 \( l \) 层的输出权重矩阵,\( O_{l} \) 是第 \( l \) 层的最终输出。
7. **残差连接和层归一化**:
\[ X_{l} = \text{LayerNorm}(X_{l-1} + O_{l}) \]
其中,\( \text{LayerNorm} \) 是层归一化操作,有助于稳定训练过程。
下一层的输入:
\( X_{l} \) 将作为下一层 \( l+1 \) 的输入,重复上述步骤。
最终输出:
经过所有 \( L \) 层的处理后,\( X_{L} \) 可以被用作进一步的下游任务,如分类、生成等。
通过这种设计,每一层都在前一层的基础上提炼和组合特征,形成更加高级的表示。残差连接和层归一化确保了信息可以有效地在多层之间传递,同时避免了梯度消失的问题。这种多层结构使得注意力模型能够捕捉序列数据中的长距离依赖关系,极大地提高了模型的性能。
3.多层结构使得注意力模型能够学习到更加复杂和丰富的数据表示
在多层注意力机制中,每一层都在前一层的基础上提炼和组合特征,形成更加高级和抽象的表示。这种逐步抽象和提炼的过程,使得模型能够捕捉到数据中更加复杂和深层的模式。以下是这个过程的详细解释:
1. 逐层抽象和特征提取
在多层注意力模型中,每一层都对输入数据进行处理,以提取不同层次的特征:
- 第一层可能捕捉到序列中相邻元素之间的局部关系,如单个词或相邻词之间的关系。
- 中间层开始捕捉更复杂的模式,如短语或句子成分之间的关系。
- 高层可能抽象出更高级的概念,如整个句子或段落的主题和意图。
2. 上下文信息的累积
每一层的注意力机制都考虑了序列中所有元素的信息,生成一个上下文向量。随着层数的增加,这些上下文向量累积了越来越多的上下文信息:
- 第一层的上下文向量主要反映了局部上下文。
- 后续层在此基础上进一步整合信息,捕捉更广泛、更全局的上下文。
3. 局部到全局的信息捕捉:
-
局部特征捕捉:在较低层次的注意力模型中,每个注意力头可能专注于捕捉序列中相邻元素之间的局部关系,如单个词或相邻词组的语义关系。
-
中间层次的特征整合:随着层数的增加,注意力机制开始整合来自较低层次的信息,捕捉更广泛的上下文,如短语或句子成分之间的联系。
-
全局特征抽象:在更高层次上,注意力模型能够抽象出整个序列的全局特征,如段落或整个文档的主题和意图。
4. 残差连接和层归一化
- 残差连接允许从较低层次直接传递信息到更高层次,这有助于梯度在训练过程中更有效地反向传播。
- 层归一化有助于稳定训练,确保每一层的输入分布保持相对稳定。
5. 前馈网络
进一步的特征转换:在自注意力之后,每个层的输出还会通过一个前馈网络(通常包含一个ReLU激活函数),进一步提取和组合特征。
6. 端到端学习
联合优化:所有层的参数都是通过反向传播算法端到端联合训练的,从最后一层的输出开始,梯度会依次传递到前面的每一层,更新每一层的参数。
数学描述
以 Transformer 模型为例,其第 \( l \) 层的处理可以用以下数学公式描述:
1. **自注意力**:
\[ \text{Attention}^l(X^{l-1} ) = \text{softmax}\left(\frac{Q^l K^{l,T}}{\sqrt{d_k}}\right) V^l \]
2. **残差连接和层归一化**:
\[ X'^l = \text{LayerNorm}(X^{l-1} + \text{Attention}^l(X^{l-1})) \]
3. **前馈网络**:
\[ O^l = \text{FFN}(X'^l) \]
4. **最终层输出**:
\[ X^l = \text{LayerNorm}(X'^l + O^l) \]
其中,\( Q^l \),\( K^l \),\( V^l \) 是通过输入 \( X^{l-1} \) 与层特异性权重矩阵 \( W^{Q}_l \),\( W^{K}_l \),\( W^{V}_l \) 相乘得到的,\( \text{FFN} \) 表示前馈网络,通常是一个带有ReLU激活函数的全连接层。
通过这种方式,多层注意力模型能够逐步提炼和组合特征,形成从局部到全局的多级表示,从而捕捉数据中的复杂关系和模式。















 10万+
10万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









