






单目深度估计基础理论和论文学习总结

一、背景知识:
三维刚体运动的数学表示:旋转平移矩阵、旋转向量、欧拉角、四元数、轴角模型、齐次坐标、各种变换等
照相机模型:单目/双目模型,单目中的世界坐标系/相机坐标系/图像坐标系的互相转换、畸变与矫正,双目涉及的视差和深度的反比关系、基线,鱼眼模型和校正等
图像变换:线性变换、仿射变换、透视(投影变换)
图像相似度评价指标:SSIM/PSNR/MSE、平滑损失、ξ等。
参考:《视觉SLAM十四讲》
二、综述类文章:
1、基于深度学习的单目深度估计综述
一篇中文的比较全的综述,每一项介绍的比较简单,适合复习的时候看,包括背景介绍、有监督无监督方法、数据集、相关工作等。
2、Deep Learning based Monocular Depth Prediction: Datasets, Methods and Applications
英文的极其全的综述,非常好
3、深度学习之单目深度估计(上、下)
桔子毛:深度学习之单目深度估计 (Chapter.1):基础篇
桔子毛:深度学习之单目深度估计 (Chapter.2):无监督学习篇
这一套比较详细地讲了理论,收获很大,了解了有监督方法的网络架构设计:couse-fine网络设计、基于FCN和更深的resnet50的设计,和无监督方法具体用的损失函数如光度重建误差的含义、SSIM指标含义、齐次坐标的含义、利用立体图像重建的naïve方法的思路、左右视图重建方式改变的NOLR方法的好处(可以一一对应没有空洞)、基于左右一致性的monodepth思路和他的损失函数的设计、视差图和深度图的关系、半监督的方法、基于视频重建方法的思路和他针对运动物体设计的mask约束的思路等等,但因为是2017年写的,后面的就没有了,monodepth2的改进要另外查。
三、视频课程:
1)付费课程:单目深度估计方法: 理论与实战
https://app0s6nfqrg6303.h5.xiaoeknow.com/v1/goods/goods_detail/p_6172be24e4b0cf90f9bca141?type=3
还没更完,比较全面系统,提供了一些参考资料和论文目录
2)免费课程::
主要讲无监督:
主要讲有监督:
四、基础论文阅读收获总结:
1、监督方法:
Depth Map Prediction from a Single Image using a Multi-Scale Deep Network (2014 NIPS)
Eigen组做的初次尝试,backbone使用AlexNet,分为course-fine两个网络,采用全局-局部策略,损失函数RMSE,全连接层输出。
上一篇的拓展,backbone换成VGG16,增加了一个fine网络,同时预测深度、发现和label
Deeper Depth Prediction with Fully Convolutional Residual Networks(FCRN)
第一次使用DCN进行深度估计,backbone使用RESNET50,但由于深度深,效果比较平滑,不如VGG输出的轮廓清晰。
2、无监督方法:
(1)使用立体图像重建损失:
Naïve方法:使用正向投射的方法计算重建损失
Unsupervised CNN for Single View Depth Estimation: Geometry to the Rescue(ECCV 2016)
使用目标图像到源图像的逆投射重建,损失函数使用L1损失和平滑损失,逆投射可以保证原图和重建图可以一一对应,不会出现空洞。
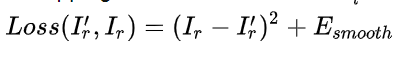
Monodepth: Unsupervised Monocular Depth Estimation with Left-Right Consistency(2017 CVPR)
使用左右一致性损失,用SSIM和L1相结合的损失函数,网络在多个尺度输出深度图
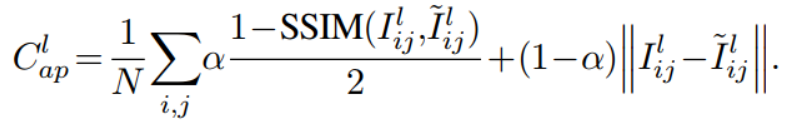

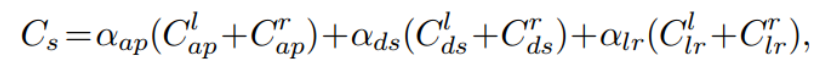
(2)使用视频流重建损失:
Unsupervised Learning of Depth and Ego-Motion from Video(CVPR 2017)
使用pose CNN和depth CNN同时预测位姿和深度,利用前后帧进行重建,还使用了motion explanation mask作为动态目标的处理,预测一个尽可能大的mask,并使重建损失函数最小.
下面公式一相当于两个相机坐标系下的转换,即原图像先用内参的逆转换到他的相机坐标系,再用旋转平移矩阵转到另一个相机坐标系,再用内参转到另一个相机的图像坐标系,注意这里用的也是逆向转换,而深度Z是数乘,可以变换位置。


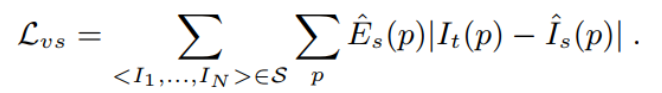
Monodepth2:Digging Into Self-Supervised Monocular Depth Estimation
主要是基于单目视频流的方法,也可加入双目立体图像训练,已精读,总结如下:
主体上继承上一篇的视频无监督方案,加入三点提升。
损失函数:上两篇的结合,主要包括光度重建损失和L1损失的加权、边缘平滑损失


主要提升:
-
一个最小重投影误差,用来提升算法处理遮挡场景的鲁棒性、
-
一种全分辨率多尺度采样方法,可以减少视觉伪影
-
一种_auto-masking loss_,用来忽略训练像素中违反相机运动假设的像素点
第一点意思是其他方法是采用多个输入图片投影误差的均值,这样由于有些像素存在遮挡,找不到对应的像素,导致损失函数惩罚较大,会引起结果边缘不准,本文采用的是多张输入图片中最小的冲投影损失所谓损失函数,可以使深度边缘更清晰,准确性更高。
第二点意思是其他方法是在CNN每一层输出的深度图上直接计算损失,导致低分辨率的深度图可能出现空洞和视觉伪影(texture-copy artifacts.),本文把每一个中间层输出的深度图都用双线性插值上采样到与输入一致的分辨率,减少了视觉伪影。
第三点意思是其他方法是单独计算基于运动物体的mask,有的无法评估,有的用基于光流(optical flow)的比较复杂的方法,本文采用了自动计算的mask,使用二值化的参数μ表示计算简单且结果准确。定义如下:
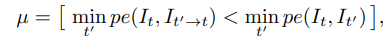
其他问题:
1、 本算法失效的情况:违反朗伯假设的,如畸变的,反光的,饱和度高的区域,和边缘模糊、形状复杂的目标
2、 提到full eigen数据集里面有一些相机静止的序列,依然表现较好,还有一个KITTI补全的数据集评测效果也较好,后面可以看看如何补全。
3、 用了reflection padding代替zero padding,解码器中对于超出边界之外的点用最近的边界像素代替。位姿网络中用轴角表示法,旋转平移矩阵乘以0.01,预测6个自由度的位姿。最后的尺度恢复采用中值缩放的方式,把输出和真值缩放到同样的尺度。真值采用整个测试集的真值尺度。
4、 实验部分围绕三个改进点分别测试。
Featdepth: Feature-metric Loss for Self-supervised Learning of Depth and Egomotion
目前深度估计方法的问题:
虽然重建损失有效,但有问题,因为正确的深度和姿态对于小的光度误差是充分的,但不是必要的 • 例如,即使深度和姿态被错误估计,无纹理像素还是具有小的光度损失
贡献:
学习具有更好梯度的特征表示来克服上述问题,并相应地将光度损失推广到特征损失
提出Feature-metric loss,对特征图计算光度误差,即使在无纹理区域也明确限制其具有判别性
提出FeatureNet(自编码器),利用单视图重构来学习特征表示
结合两个正则化损失,确保在特征表示上定义的损失可以更好的下降

(3)伪监督方法
Pseudo Supervised Monocular Depth Estimation with Teacher-Student Network
伪监督方法(知识蒸馏),用无监督双目训练教师网络,输出单目的伪标签来有监督地训练学生网络,同时加入有监督的语义分割增强器来提升效果,使用遮挡mask处理遮挡问题**(精读)**
3、 半监督方法:
Semi-Supervised Deep Learning for Monocular Depth Map Prediction(2017 CVPR)
稀疏深度真值和自监督结合,但纯自监督的效果不如monodepth














 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









