







 本文探讨自动驾驶中BEV(Bird's Eye View)的核心技术——BEVformer,它通过特征融合、时空注意力机制实现资源优化。BEVformer利用可变注意力机制Deformable-attention进行特征简化,降低计算量,并通过时间注意力模块处理时间对齐问题,提高物体检测的准确性。此外,文章还介绍了Deformable-attention的工作原理,强调其在CV领域的前景。
本文探讨自动驾驶中BEV(Bird's Eye View)的核心技术——BEVformer,它通过特征融合、时空注意力机制实现资源优化。BEVformer利用可变注意力机制Deformable-attention进行特征简化,降低计算量,并通过时间注意力模块处理时间对齐问题,提高物体检测的准确性。此外,文章还介绍了Deformable-attention的工作原理,强调其在CV领域的前景。
自动驾驶 BEV 的核心技术有些什么
附赠自动驾驶最全的学习资料和量产经验:链接
这篇就是介绍BEVformer是个啥
先给个定义,BEVformer就是个基本框架:
1-通过多个摄像头来进行特征融合,纯视觉方案
2-通过特征对齐,将attention应用于时间与空间维度
3-Attention也是极简attention,抛弃多余的特征,在允许的范围内,尽量的粗粒度分布的空间(省资源)
4-Deformable-attention(这个估计大概率得开一门新篇了,这里就简单介绍一下)
举些例子说明它怎么做到的以上的能力和思路
老图新改
按照下图说,比如我要求橙色箭头上对应的这个点的特征,那如果我想求出这个点的特征,要和其他6个矩阵中的哪几个矩阵去做乘法呢(没错其实就可以简单理解成矩阵乘),如果我要全做,那这个框架等于没意义
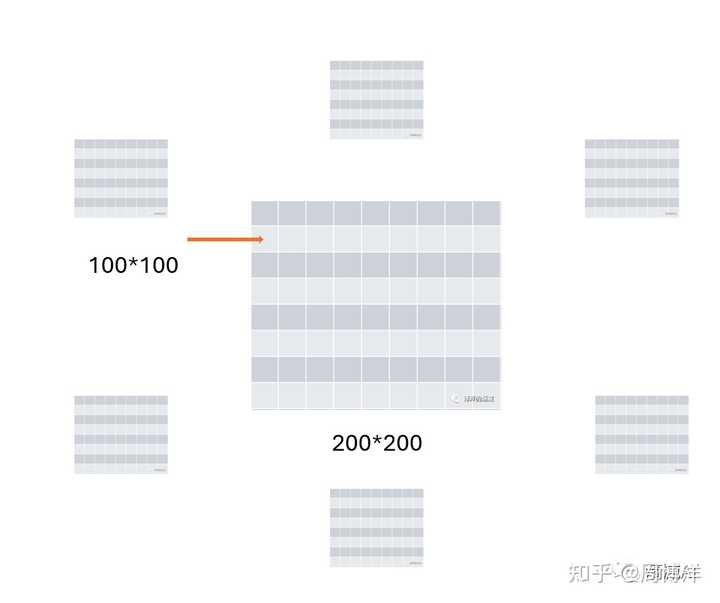

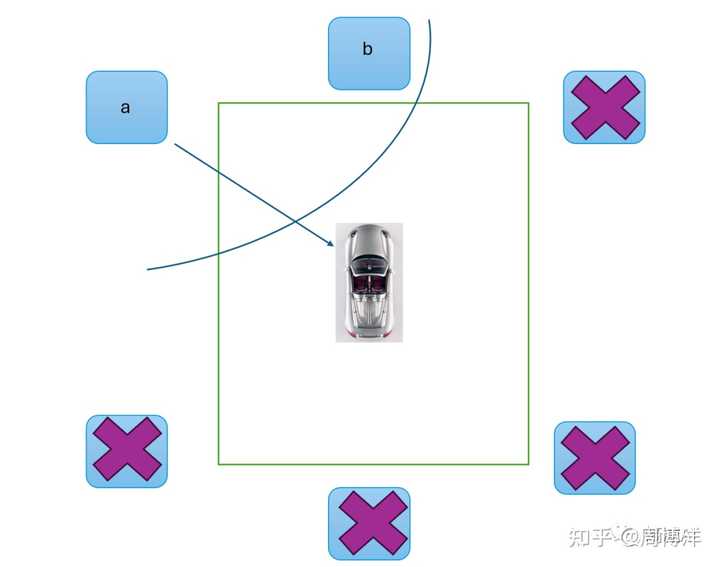
然后我们判断一下,这个点对应的实际上在物理世界里是前面和左前方摄像头的位置,跟其他额外的四个不发生关系
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 789
789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









