






BEV感知综述
随着自动驾驶传感器配置多模态化、多源化,将多源信息在unified View下表达变得更加关键。BEV视角下构建的local map对于多源信息融合及理解更加直观简洁,同时对于后续规划控制模块任务的开展也更为方便。BEV感知的核心问题是:
- 如何利用缺失3D信息的PV视角来构建BEV视角;
- 如何获取BEV表达下的真值标注;
- 如何有效融合不同模态及视角的传感器数据;
- 不同车型、场景下传感器配置各不相同,如何能够实现Onetrack的能力;
本文回溯了近期BEV感知领域的最新进展,并对各类解决方案进行了深入分析。对于工业界流行的解决方案也进行了详细的阐述,并指明了未来该领域的研究方向。以期更多的研发资源能够推动该领域快速发展。
自动驾驶感知模块的任务就是对物理世界的3D重建。随着智驾车辆传感器配置多样化丰富化,BEV对于多源多视觉信息的汇聚融合具有天然的优势。BEV视角下解决了2D前视视角存在的遮挡、尺度等问题,同时动目标、地图要素等可直接用于下游的规划和控制模块。
- BEV Camera:纯视觉;
- BEV LiDAR:激光;
- BEV Fusion:多传感器,包括视觉、激光、轮速、IMU等;
BEV感知研究动机
重要性
目前Nuscence和Waymo数据集的排行榜可知,视觉相比激光仍然存在20-30%的差距,那纯视觉的效果能否追平甚至超越激光的效果呢?这个问题对于学术界,是如何将2D的视觉信息像LiDAR一样精确的转换到BEV空间中;而对于工业界来说,相机相比LiDAR具有更低的成本,且在远处更稠密更丰富的纹理信息。另外一个问题是如何融合两种传感器的优势,形成更为强大的融合结果。
空间
对于激光传感器易获得深度信息,而对于单目相机要获得深度信息是非常挑战的任务。如何对多模态数据进行融合,包括前融合、后融合等,其中后融合阶段来自于视觉和激光的深度信息误差或配准都会导致性能降低。
准备度
当前公开的数据集是否能够支撑BEV感知的进一步研究?在数据集方面:Nusence及Waymo数据集提供了高质量的标注及多模态数据对齐,非常利于BEV感知研发的开展。同时leadboard也给大家听了同台打擂的机会。在算法方面:通用视觉领域已经突飞猛进,Transformer、ViT、CLIP等均有优异的表现。
贡献
- 回溯了今年BEV感知研发的进展,包括宏观的架构及方法的细节讨论;
- 综合分析了各个方面,包括depth estimation、View transformation、sensor fusion、domain adaptation等;
- 除理论基础外,还提供了提升BEV感知的实践指导手册;
评价标准
BEV感知方法介绍
BEV Camera

纯视觉3D感知最初的任务是如何从PV视角预测Object的位置,因为基于PV的检测任务已经成熟,所以核心任务就成了如何在2D检测能力基础上增加3D场景的认知能力。之后为了处理在3D空间Oject的Size保持一致,而在image中会随着距离远近而变化的问题,研究者引入了BEV的表达形式加以解决;通常采用了深度预测及先验信息假设(地面、触地点)等手段来弥补image的3D信息缺失。近期BEV感知进展已经极大的推动了3D感知问题的发展,主要原因包括:
- 高质量数据集的出现,比如Nuscence multi-camera的配置非常适合在BEV空间下进行multi-view特征的聚合;
- 纯视觉BEV任务借鉴了很多LiDAR在检测头和LOSS函数设计方面的优秀实践;
- 单目视觉的PV视角任务经历了蓬勃发展,这些进展在BEV任务中的落地也推动了BEV任务的性能表现;
BEV Lidar


- preBEV
- postBEV
点云是在连续3D空间采集到的数据,而在3D连续空间计算点与点见的相对位置关系存在着算力和感受野受限等关键问题。近期研究利用离散的grid数据来表示原始点云数据;然后使用卷积操作在grid表达上进行卷积操作,然而原始点云被表达为grid的形式难以避免信息的丢失。SOTA的pre-BEV方法借住高分辨率的Voxel size能够尽可能保留原始点云中的信息,从而在3D检测任务中取得了不俗的表现。高分辨率Voxel size也伴随着高算力和高存储的问题。直接将原始点云转到BEV空间避免了3D空间的卷积操作,但是丢失了大量高维信息,最高效的方式是将原始点云通过统计的方式表达为featrue map,获得不是最优但是可以接受的性能表现。pillar-base方法很好的平衡了效果和算力,在商用落地上优势明显。因此在效果和效率的trade-off上是lidar bev感知的核心问题。
BEV Fusion




如上图,各模态在独自的模态上进行特征提取的工作,然后各自模态下的feature map转换到BEV空间下进行融合,这块可以参考 BEVFusion ;还有一种实现路径是将视觉PV信息先提升到Voxel下的feature map,然后和激光的Voxel下feature map进行融合,这类的方法可以参考 UVTR 。进一步可以考虑自车的运动信息实现时域维度的融合,更好的速度预测及遮挡场景下的检测效果。在Temporal上的融合可以参见 BEVDet4D 和 BEVFormer 。
图像是PV坐标系,而点云是3D坐标系,因此对齐两种模态的数据是关键环节之一。虽然点云数据通过相机投影模型很容易转换到图像PV坐标系下,但是点云的稀疏性使得紧靠点云单独提取有价值的feature变得困难;反过来由于图像PV数据缺少深度信息,将PV观测转到3D空间也是一个病态的问题。针对这一问题,已有的研究,包括IPM、LSS等,正在构建将图像PV数据转换为BEV空间的方法,使得多模态、时间、空间的融合成为了可能。
融合视觉和激光各自传感器优势,显著提升了3D感知任务的优势。融合框架同时保留了传感器件的独立性,不在依赖于单一器件,因此整个感知系统的鲁棒性也得到了增强。对于时域的融合,BEV空间的feature map具有尺度一致性,可以通过自车的运动补偿实现时域融合。因此考虑到鲁棒性和尺度准确性,BEV成为了一个感知结果表达的理想空间。
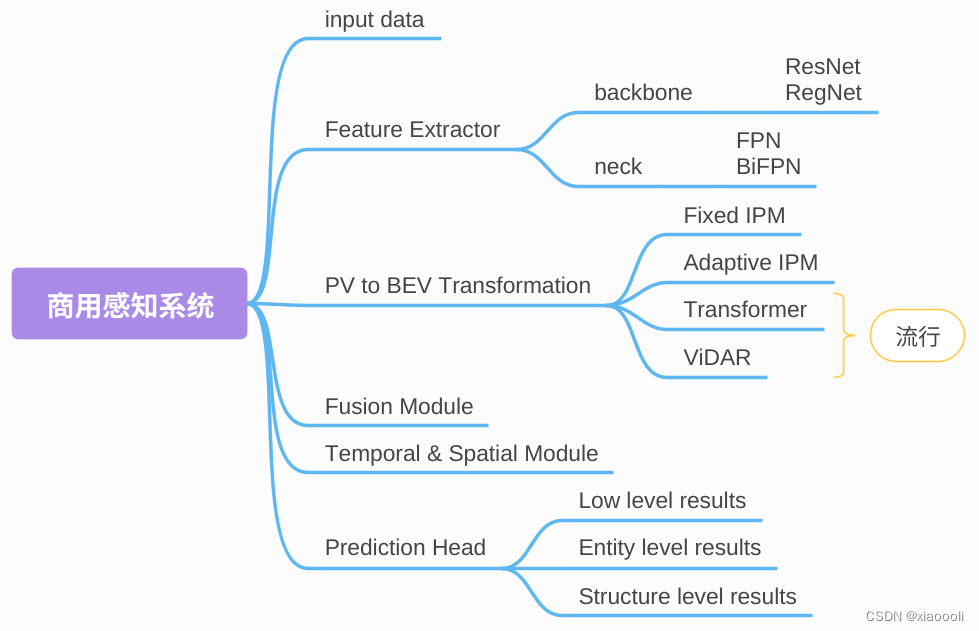
BEV感知商用落地

商用的感知系统最初常用a图方式,即pv先出感知结果,然后转换到bev空间下与激光的结果进行后融合操作;显著已经发展为了b图的形式,即pv出featuremap,然后转换到bev空间下进行featuremap融合,进而执行检测任务,也就是所谓的前融合。
经验谈
Data Augmentation
- 视觉:color jitter, flip(包含了image的和bev两种空间下的翻转), resize, rotation, crop, and Grid Mask;
- 激光:random rotation, scaling, flipping, and point translation、Painting( Point-Painting )、temporal;
BEV Encoder
参考以下两种视觉和激光的典型BEV方法:
- BEVFormer++
- Voxel-SPVCNN
LOSS
对于视觉来说,可以综合运用目标检测的2D和3D的loss设计来训练模型;此外还可以使用深度监督信息( BEVDepth ),以提升3D检测的精度。通常2D的目标检测和单目深度估计会直接使用SOTA的预训练模型。对于激光来说,会联合使用 cross-entropy loss 、 Geo loss 和 Lovász loss 来提升检测效果;
总结
综合以上,未来BEV感知的主要研究方向包括:
- 如何设计一个精确的深度估计器;
- 如何融合来自多模态多视角的传感器数据的feature map;
- 如何实现模型对传感器安装位置无感,实现onetrack的部署能力;
- 如何将foundation model的成功经验(大模型、多任务)复制到bev感知领域上;














 4566
4566











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









