






Learning Without Forgetting
Abstract
这篇文章仍然从最简单的分类任务入手,LWF是结合知识蒸馏(Knowledge Distilling)避免灾难性遗忘的经典持续学习方法。本质上是通过旧网络指导的输出对在新任务训练的网络参数进行平衡,从而得到在新旧任务网络上都表现较好的性能。
Introduction

-
从头开始训练
-
微调:在旧任务的网络基础上以较小的学习率学习新任务 另一种意义上的initialization?
-
联合训练:使用所有任务的数据一起训练
-
特征提取:将旧任务的参数固定作为特征提取器,添加新的层训练新任务
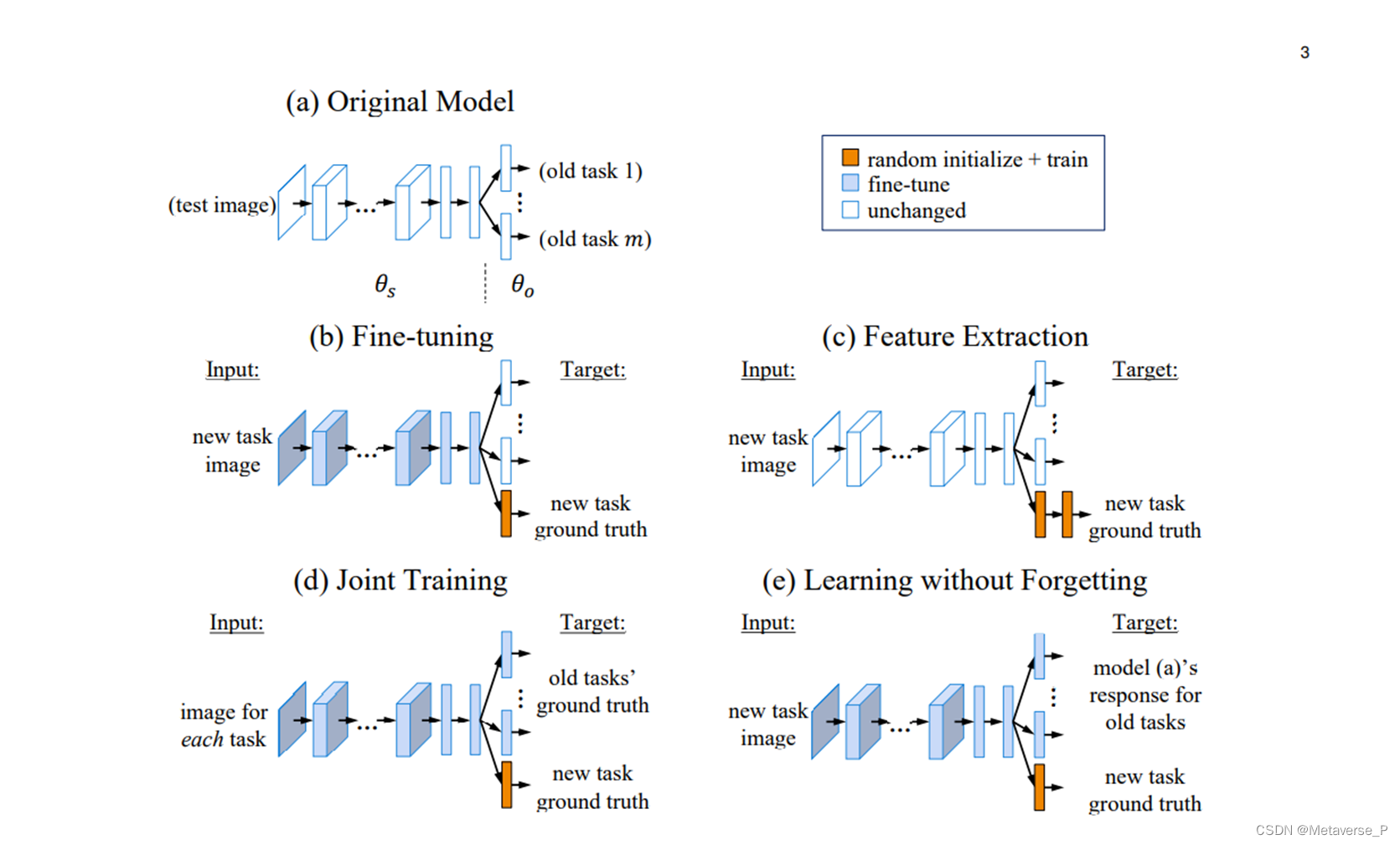
上述方法均有缺点:特征提取通常在新任务上表现不佳,因为共享参数不能表示一些新任务独有的特征表示。微调也因为没有旧任务样本的指导而在旧任务上表现变差
Conclusion
本文提出一种名为 Learning without Forgetting (LwF)的方法,仅仅使用新任务的样本来训练网络,就可以得到在新任务和旧任务都不错的效果。本文的方法类似于联合训练,但不同的是LwF 不需要旧任务的数据和标签















 7297
7297











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









