






一、机器学习分类、回归和聚类
在机器学习中,常见的任务包括分类、回归和聚类。
分类
分类是一种监督学习的任务,它通过将数据划分到预定义的类别中来进行预测。分类算法包括决策树、支持向量机、朴素贝叶斯和神经网络。
例如:
-
垃圾邮件过滤:对电子邮件进行分类,将垃圾邮件和正常邮件区分开来。
-
图像分类:对图像进行分类,例如识别数字、动物或汽车等。
-
疾病诊断:对患者的症状和测试结果进行分析,以帮助医生进行疾病诊断。
回归
回归也是一种监督学习的任务,用于预测实型数值的输出,回归算法包括线性回归、岭回归、逻辑回归和多项式回归。
例如:
-
房价预测:使用回归算法,根据房屋的特征(如面积、位置和特点)来预测其价格。
-
股票价格预测:利用历史股票数据和回归模型,预测股票未来的价格走势。
-
销量预测:根据历史销售数据和其他因素(如促销活动和季节性)来预测产品的销售量。
聚类
聚类是一种无监督学习的任务,通过将数据分组成相似的对象来进行分析。根据样本的属性, 把给定的样本集合划分为若干个子集。聚类算法包括K均值聚类、层次聚类等。
例如:
-
客户细分:根据客户的购买行为和偏好将其分组成不同的细分市场。
-
新闻主题聚类:将新闻文章分组成不同的主题类别。
-
图像分割:利用图像处理和聚类算法,将图像分割成不同的区域或对象。
二、机器学习中的训练、测试与验证
基本概念
- 训练集:给定的标签数据集,用于训练机器学习模型。
- 测试集:用于评估机器学习模型预测能力的数据集。
- 机器学习:计算机从数据中学习,进行预测和决策的过程。
- 监督学习:在训练集中,给定了所有标签,指导模型学习。
不同方案的训练和测试
- 训练集与测试集划分:将数据集分为训练集和测试集进行模型训练和评估。
- 随机划分:多次随机划分训练集和测试集,计算错误率的均值和方差。
- 交叉验证:将数据集分为多份,轮流选择其中一份作为测试集,其余作为训练集,所有数据都被测试过一次。
- 留一法:数据集中每个样本都作为测试集,其余样本作为训练集,适用于样本较少的情况。
- 使用训练集进行测试:使用训练集进行预测,评估模型在训练数据上的能力。
拟合能力与泛化能力
- 拟合能力:模型在训练集上的表现,即从函数簇中选择最适合训练数据的函数。
- 泛化能力:模型在未见过的数据上的表现,衡量模型用于服务其他就诊者的能力。
- 过拟合:当模型在训练集上表现好,但在新数据上表现较差时,产生了过拟合现象。
- 提升泛化能力:降低拟合能力,以获得更好的泛化能力,防止过拟合。
验证集
- 数据集划分:将数据集分为训练集、验证集和测试集。
- 验证集的作用:用于验证模型效果,根据验证结果调整模型参数。
- 示例:使用70条数据作为训练集,20条作为验证集,10条作为测试集,通过验证集调整模型,最终在测试集上评估模型性能。
思维导图: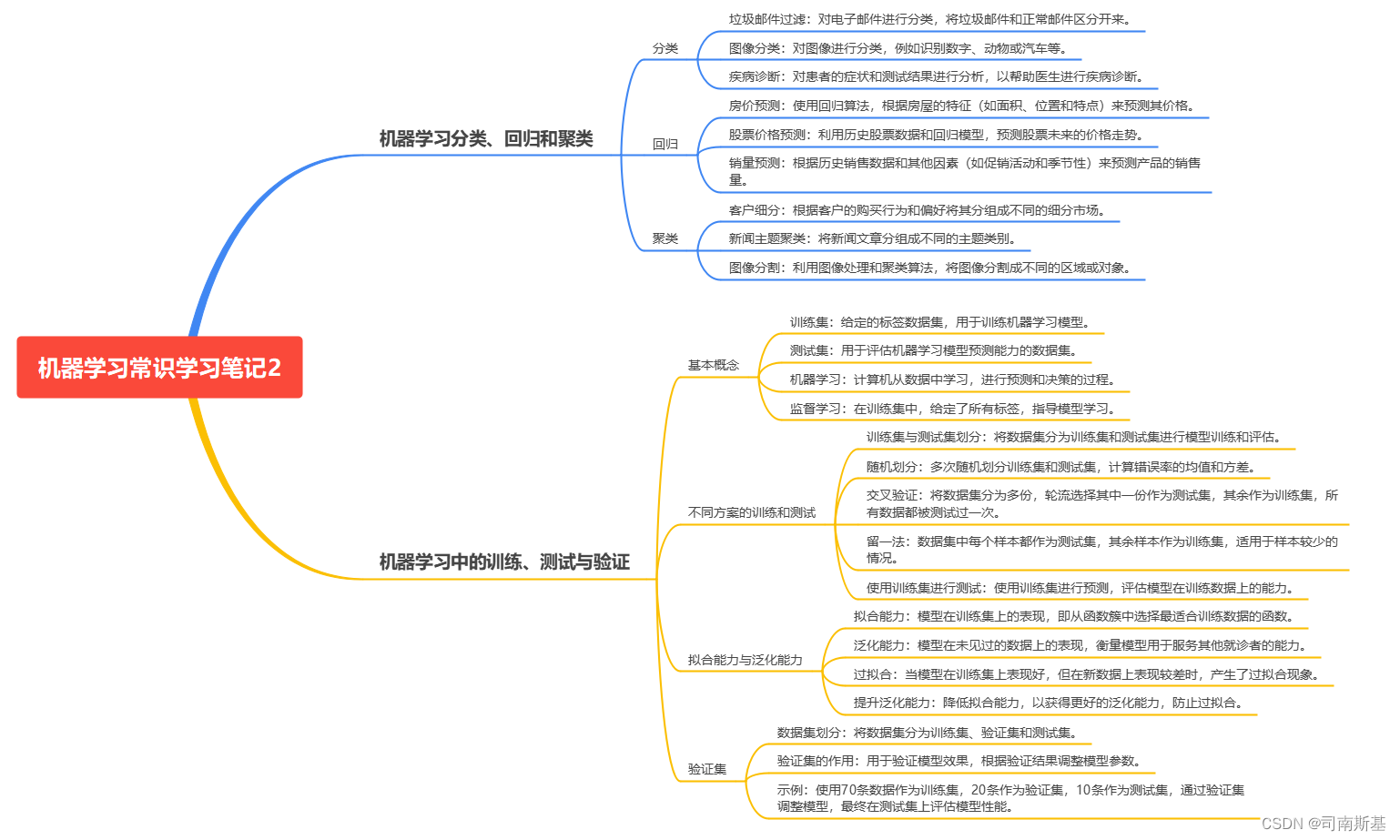














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









