







Deep Residual Learning for Image Recognition
图像识别中的深度残差学习网络
论文结构
摘要: 深度网络训练难;残差网络可训练1000层网络;成就。
1. Introduction: 提出深层网络存在模型退化问题;分析问题并提出残差学习策略、
2. Related Work: 列举残差学习应用例子;单独用一段对比Highway Network。
3. Deep Residual Learning: Residual learning; identity learning;Network Architecture。
4. Experiments: 对ResNet进行实验
一、摘要核心
① 提出问题:深度卷积网络难训练。
② 本文方法:残差学习框架可以让深层网络更容易训练
③ 本文优点:ResNet易优化,并随着层数增加精度也能提升
④ 本文的工作和成果
二、训练技巧
① 残差结构
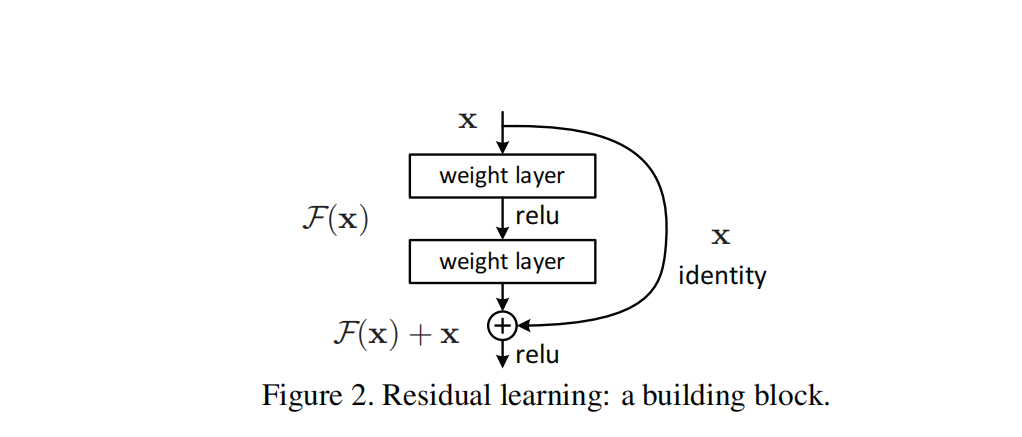
(1) 网络退化(论文中的1)
-
网络退化问题:越深精度越低,即当模型的层次加深时,错误率却提高了。
-
分析:
问题1:梯度消失和爆炸,因为当模型变复杂时,SGD的优化变得更加困难,导致了模型达不到好的学习效果。消失问题很好的用初始化和normalize layer解决(eg.BN)问题2:网络退化问题,越深精度越低 ,原因并不是过拟合而是网络退化的问题
-
深层网络可以看成是浅层网络基础上拓展一些额外层,若增加的那些层是恒等映射,则深层网络等价于浅层网络
-
提出解决深层网络的退化问题的方法:deep residual learning framework
-
拟合f(x)比拟合H(x)要容易
-
假设要拟合的是恒等映射,残差结构比普通结构更容易拟合,残差结构的网络层输出0就可以实现恒等映射
(2)residual learning(论文中的3.1)
第一段:1. 让网络层拟合H(x)-x,而不是H(x)
第二段:
1.去拟合H(x)-x这个思想是从网络退化得到启发的
2.网络层拟合x比较难
3.让网络层拟合0比较容易,因此网络层拟合0,再加上x就很容易得到恒等映射
第三段:
1.网络层不可能理想化拟合0
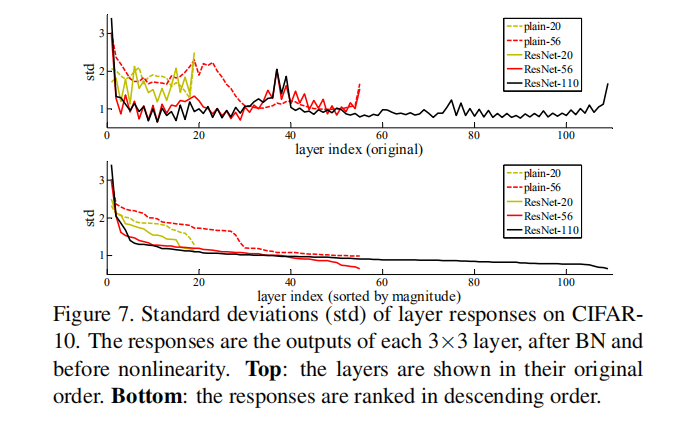
2.图7实验表明网络层虽然不能拟合0,但是其输出比较小
让额外的网络层更容易的学习到恒等映射
skip connection== shortcut connection == residual learning
(3)shortcut mapping (论文中的3.2)
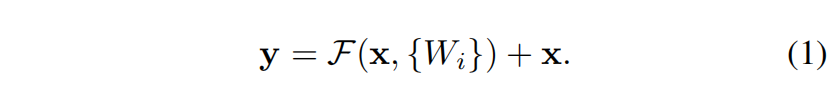
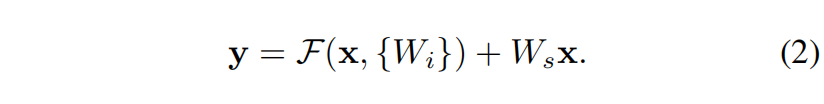
-
shortcut有利于梯度转播。恒等映射使得梯度畅通无阻的从后向前传播,这使得ResNet结构可拓展到上千层。
-
当维度不匹配时可对x进行线性变换,W_s仅用于维度匹配
-
identity与F(x)结合形式,三种shortcut策略
A:仅分辨率变化处用零补齐
B:仅分辨率变化处用线性变换,通过网络层映射(比如添加1×1卷积),使特征图达到相同维度
C:所有shortcut用线性变换(比如1×1卷积)
若F(x)=0,则H(x)=x,网络实现恒等映射。深层网络接近浅层网络的性能
② ResNet
(1)ResNet结构
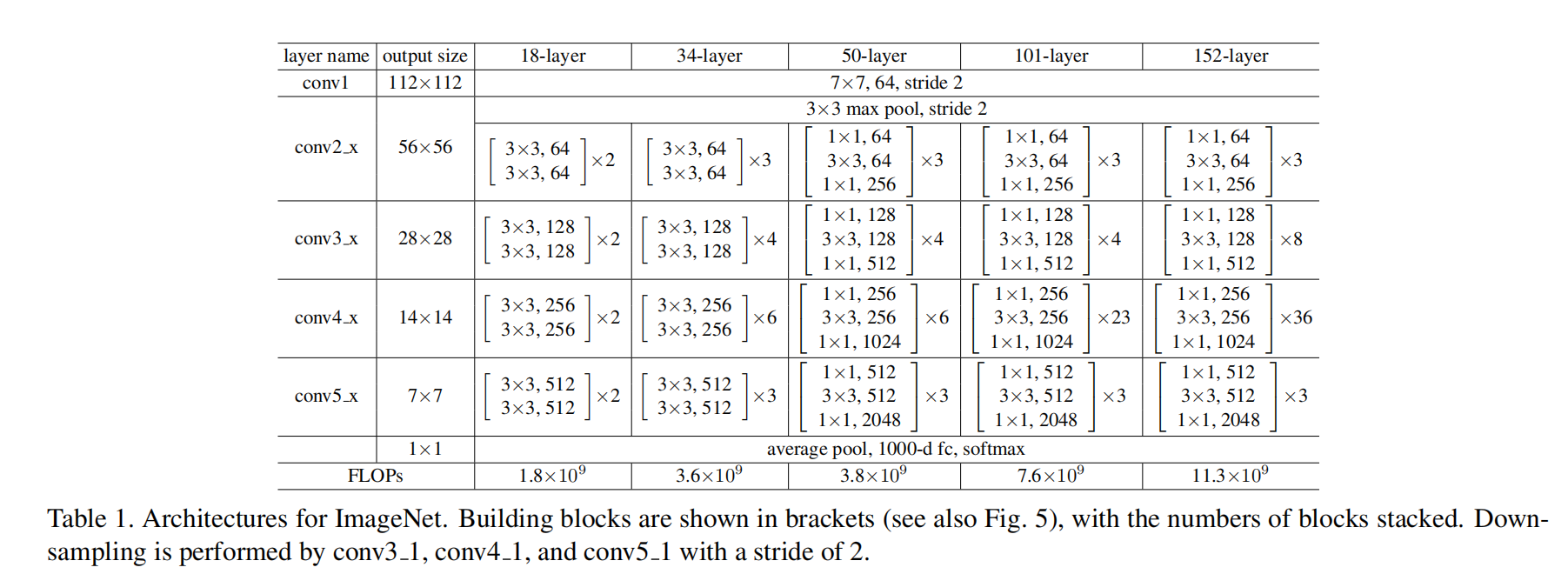
划为6个stage
- 头部迅速降低分辨率
- 4阶段残差结构堆叠
- 池化+FC输出。少了很多FC层。节省了大量参数。
(2)残差结构堆叠两种方式
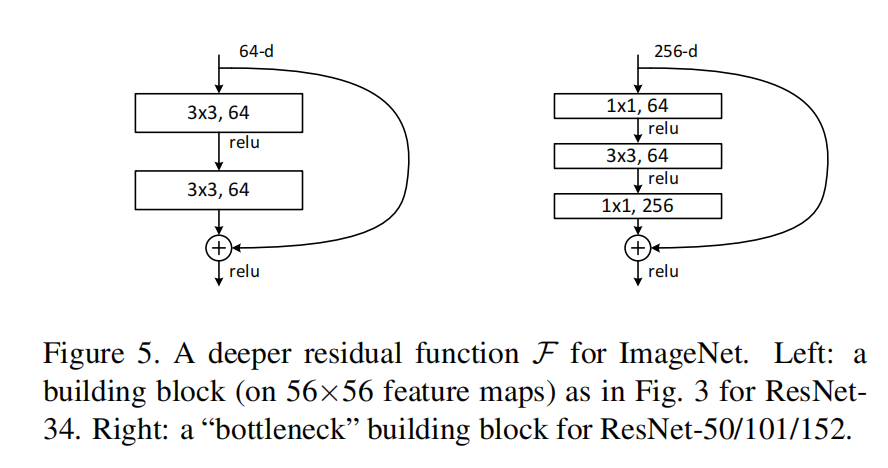
Basic:两个3×3卷积堆叠
Bottleneck: 利用1×1卷积减少计算量
Bottleneck:
第一个1×1下降1/4通道数
第二个1×1提升4倍通道数
③ 预热训练

避免一开始较大的学习率导致模型的不稳定,因而一开始训练时用较小的学习率训练一个epochs,然后恢复正常学习率。
三、实验结果及分析
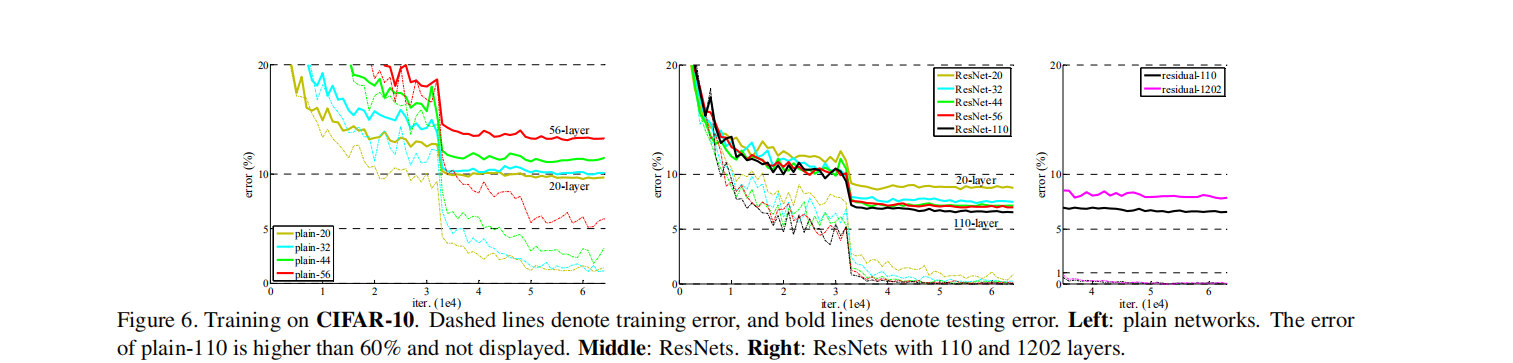
① 实验1:验证residual learning 可解决网络退化问题,可训练更深的网络。
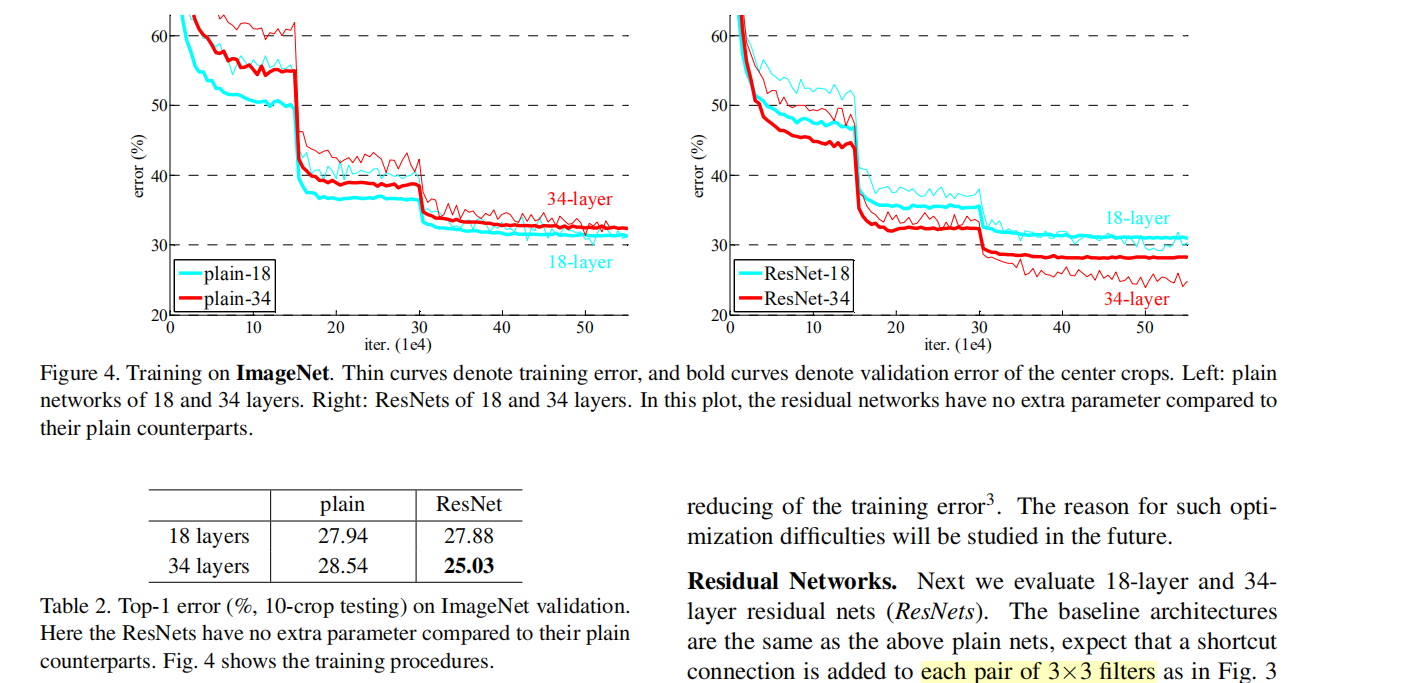
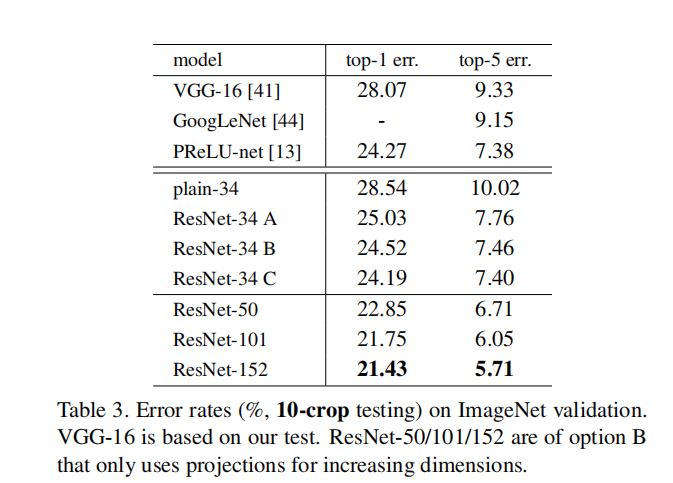
② 实验2:横纵对比,shortcut策略(ABC)及层数
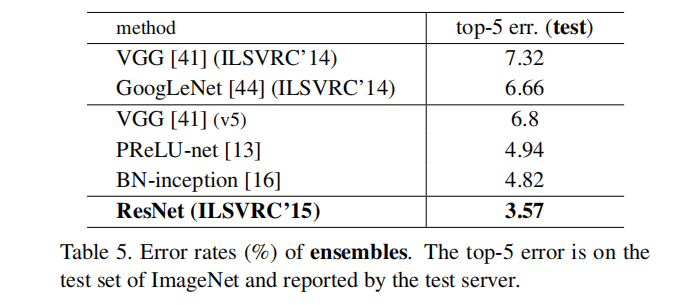
③ 实验3:成功训练1202层神经网络
④ 实验4: 残差学习输出神经元尺度
统计每个卷积+BN层输出神经元尺度,以标准差来衡量尺度。
结论:ResNet输出比plain小,表明带残差学习的结构比不带残差学习时,输出更偏向0,从而更近似于恒等映射。

四、论文总结
① 关键点、创新点
- 引入shortcut connection,让网络信息有效传播,梯度反向传播顺畅,使得数千层卷积神经网络都可以收敛。
- skip connection== shortcut connection == residual learning
② 备用参考文献知识点
-
bottleneck中两个1×1卷积,分别用于减少通道数和增加/保存通道数
The three layers are 1×1, 3×3, and 1×1 convolutions, where the 1×1 layers
are responsible for reducing and then increasing (restoring) (论文4.1) -
cifar-10数据集上的ResNet-110,第一个epochs采用较小学习率,来加速模型收敛。
We further explore n = 18 that leads to a 110-layer ResNet. In this case, we find that the initial learning rate of 0.1 is slightly too large to start converging5. So we use 0.01 to warm up the training until the training error is below 80% (about 400 iterations), and then go back to 0.1 and continue training. (论文4.2的第六段)















 4743
4743











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









