







Inception-v4, Inception-ResNet and the Impact of Residual Connections on Learning
Inception-v4, Inception-ResNet, 残差连接对模型训练的影响
文章目录
论文结构
摘要: 简介ResNet和Inception很强,将两者结合,可以获得更优的模型Inception-ResNet。
1. Introduction: 残差学习有助于深度网络的的训练,inception是很深的网络,适合把残差学习技术加进来。
2. Related Work: 介绍ResNet思路,并提出质疑,同时给出结论:没有残差结构一样可以训练深度网络。
3. Architectural Choices: Inception-V4,Inception-ResNet-V1/V2, Scaling of the Residuals。
4. Training Methodology: 训练配置
5. Experimental Results: 实验结果对比。
6. Conclusions: 总结本文提出的三个网络模型的内容:Inception-V4,Inception-ResNet-V1/V2
一、摘要核心
① 研究背景:近年深度卷积神经网络给图像识别带来巨大提升,残差连接的使用使卷积神经网络得到了巨大提升。
② 提出问题:是否可以将Inception与残差连接结合起来,提高卷积神经网络。
③ 本文成果:从实验经验得出,残差连接很大程度的加速了Inception的训练;提出了新的网络模型结构streamlined architectures。对于很宽的residual inception网络,提出激活值缩放策略,以使网络训练稳定。
二、Inception-V4
① 框架图(六大模块)
总共9+3×4+5×7+4×3+3+4+1=76层
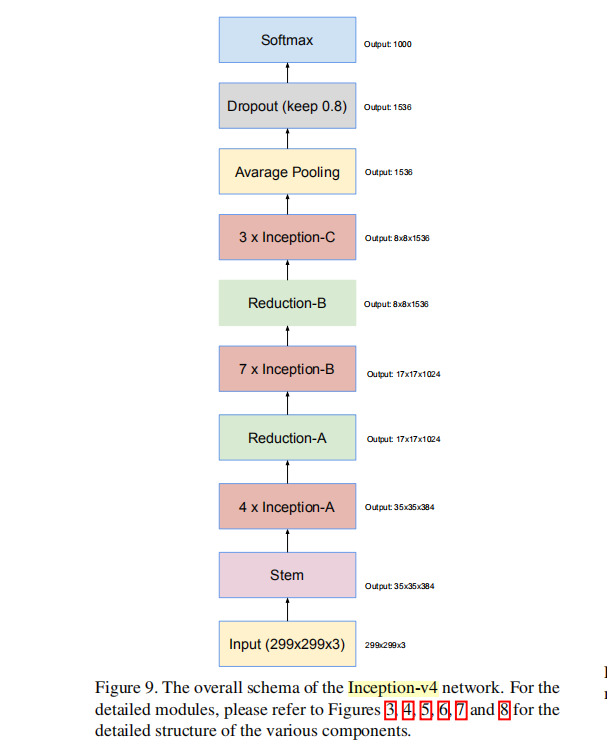
主要有六大模块:
- 主干Stem:299×299下降到35×35;下降了8倍,2³,下降了3次
- inception-A:堆叠使用4次
- reduction-A:特征图的分辨率的下降;35×35下降到17×17;还是一个多分支的结构。
- inception-B:堆叠使用7次
- reduction-B:特征图分辨率的下降,从17×17下降到8×8
- inception-C:堆叠使用3次
再经过平均池化、dropout、输出到softmax进行输出。
② 缺点
每个模块针对性的去设计,适用性非常弱。
模型总共76层
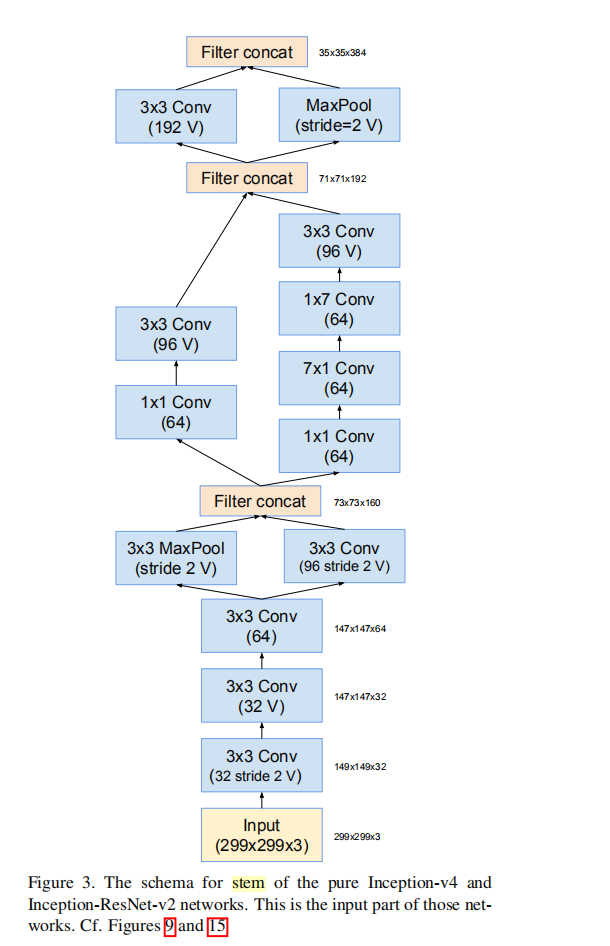
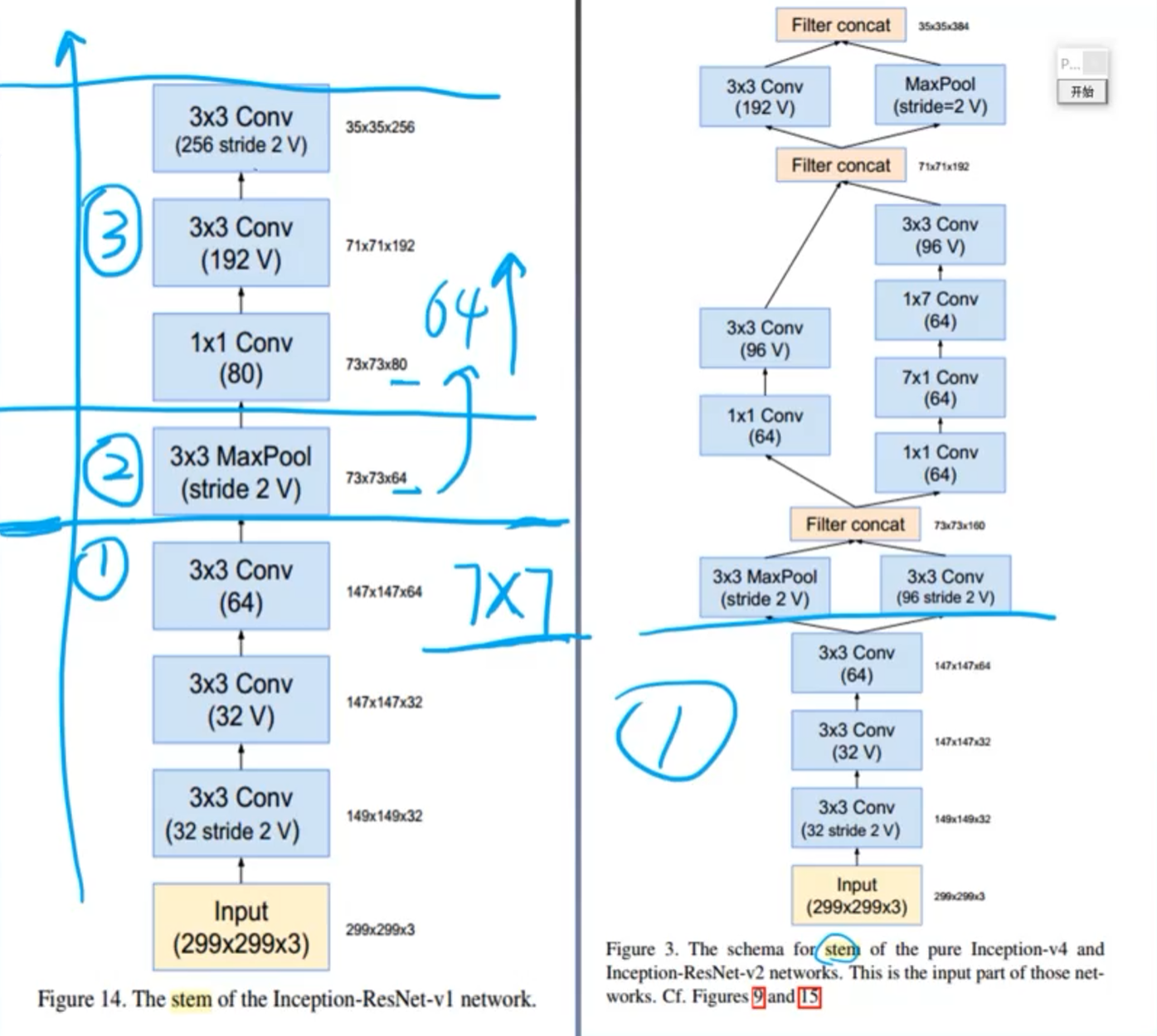
③ Stem(9层)
标了V表示不进行padding;
不标V表示会填充一定的像素,使特征图分辨率不发生变化。
Part 1:3个3×3卷积堆叠下降两次;
Part 2:高效特征图下降策略(借鉴InceptionV3);
Part 3:非对称分解卷积。
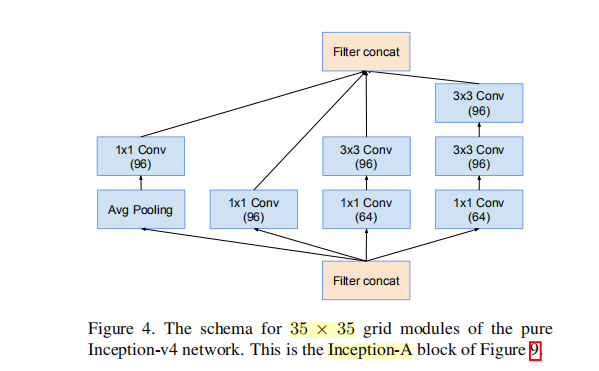
④ Inception-A(3层堆叠使用4次)
标准的inception module。
⑤ Reduction-A (3层)
采用3个分支,其中卷积核的参数k,l,m,n分别为192,224,256,384. 控制整个模型的计算量
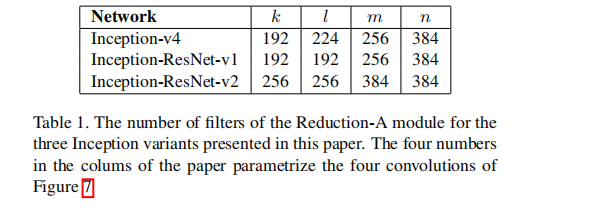
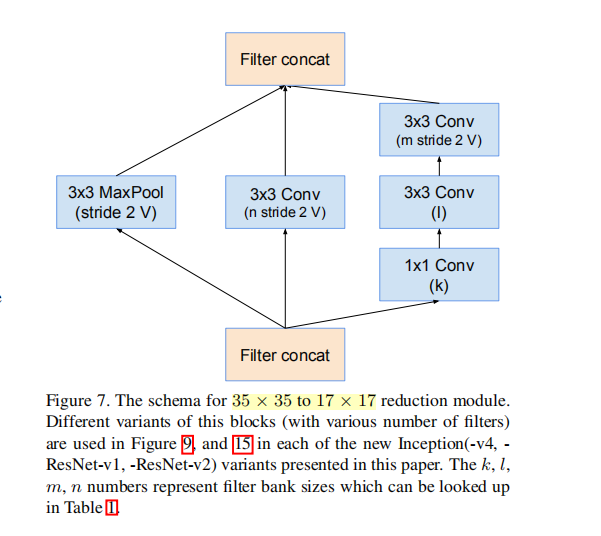
第一个分支:3×3的带重叠的池化(借鉴AlexNet)
第二个分支:3×3的卷积
第三个分支:5×5的卷积
⑥ Inception-B(5层堆叠7次)
非对称卷积操作部分,借鉴nception-V3,在12-20的特征图分辨率的时候用效果比较好,这里是17×17

⑦ Reduction-B(4层)
非对称卷积操作部分,借鉴Inception-V3

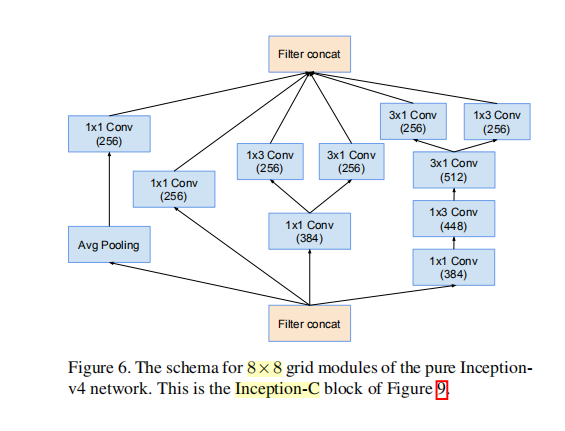
⑧ Inception-C(4层堆叠3次)
结构参考Inception-V3
三、Inception-ResNet
对比inception-ResNet v1/v2 模块
① Stem模块
V1无分支(7层)
Part 1:3个3×3的堆叠—>相当于7×7的卷积核。 开头的部分尽量用感受野较大的卷积层。
Part 2:池化,分辨率下降
Part 3:1×1提升特征图的通道。从64上升到80;两个3×3的卷积,stride = 2,下降分辨率。
V2与Inception-V4相同(9层)
② Inception-ResNet-A 模块(4层)
均处理35×35大小的特征图;
V1 卷积核数量少,V2卷积核数量多
做出不同计算量的模型对标Inception v3和v4
通过1×1卷积融合三个特征图拼接起来

③Reduction-A 模块(3层)
将35×35大小的特征图降低至17×17
Inception-V4和两个Inception-ResNet都一样
④ Inception-ResNet-B 模块(4层)
处理17×17特征图的分辨率
V1 卷积核数量少,V2卷积核数量多
先通过1×1的卷积来压缩特征通道数,用两个分支,一个分支使用非对称卷积,两个分支输出时,两个分支的特征图进行拼接之后,再输入到1×1的卷积进行计算,逐元素相加。
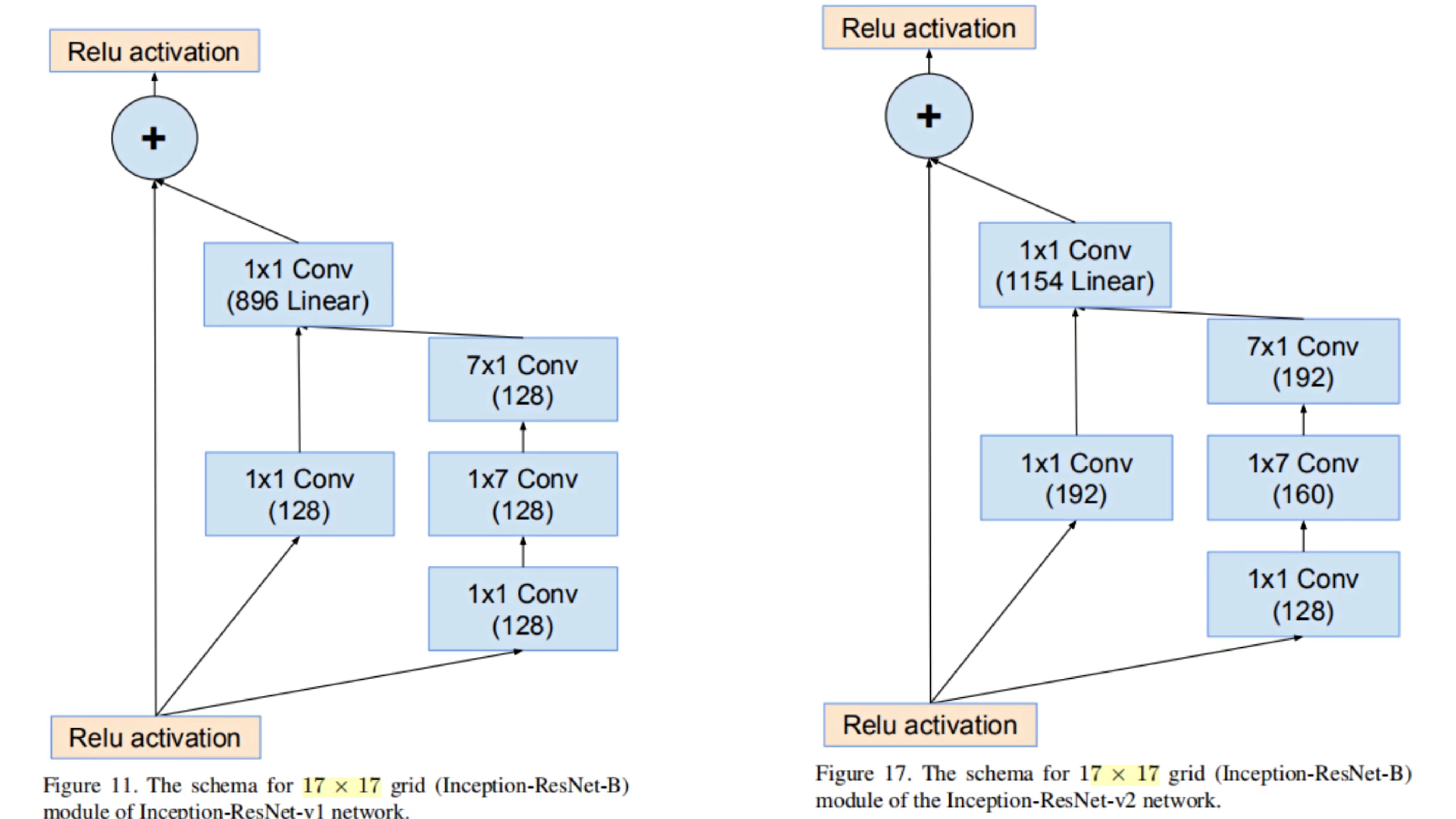
⑤ Reduction-B 模块(3层)
将17×17大小的特征图降低至7×7

⑥ Inception-ResNet-C模块(4层)
处理8×8大小的特征图
V1 卷积核数量少,V2卷积核数量多
会用比较多的1×1卷积核进行操作

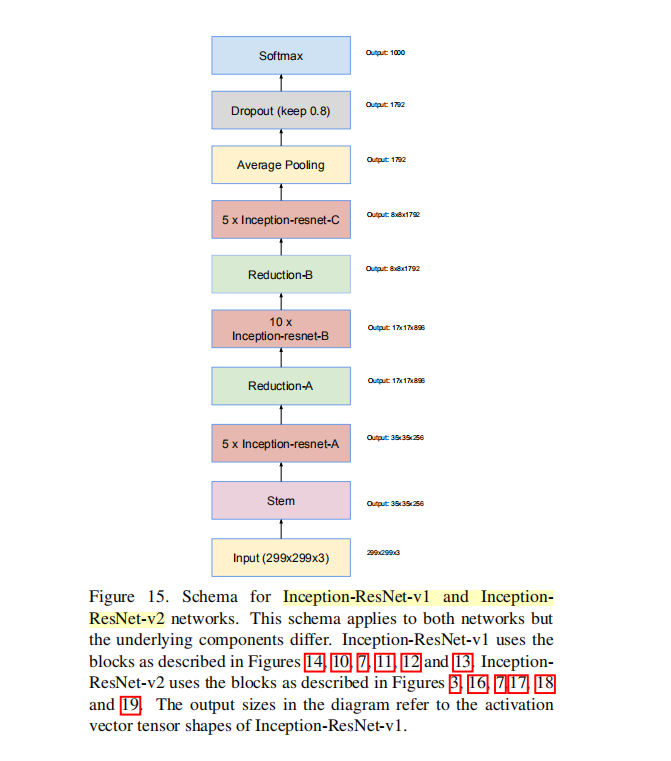
⑦ 总结Inception-ResNet v1,v2
将ResNet中的residual connection思想加到Inception中,
根据Stem和卷积核数量的不同,设计出了Inception-ResNet-v1和v2。(V1卷积核数量少,V2多,为了匹配Inception V3,V4)
Inception-ResNet -v1 共7+5×4+3+5×4+1=94层
Inception-ResNet -v2 共9+5×4+3+5×4+1=96层
五大模块一样,第一个模块不一样。
四、激活值缩放 Scaling of the Residuals(论文中的3.3)
(1)让模型训练稳定,在残差模块中对残差进行数值大小的缩放,通常乘以0.1-0.3之间的一个数。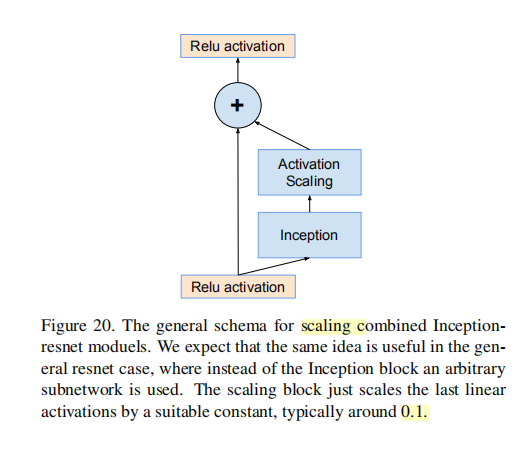
不是一定要用。用的条件:
- 卷积核超过1000时,会出现“死”神经元。
- 在最后的平均池化层之前会出现输出为0的现象
这个现象用小学习率和BN都无法避免。
可以使用在求和前进行缩放,可以稳定训练。缩放系数为0.1-0.3之间。
(2)与resnet预热训练进行对比。预热训练也是为了稳定模型,先用较小的学习率进行训练,再恢复正常学习率。
五、实验结果及分析
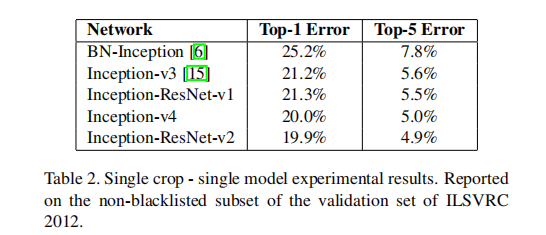
① 单模型 对比
②10-crop、144-crop以及模型融合对比各模型
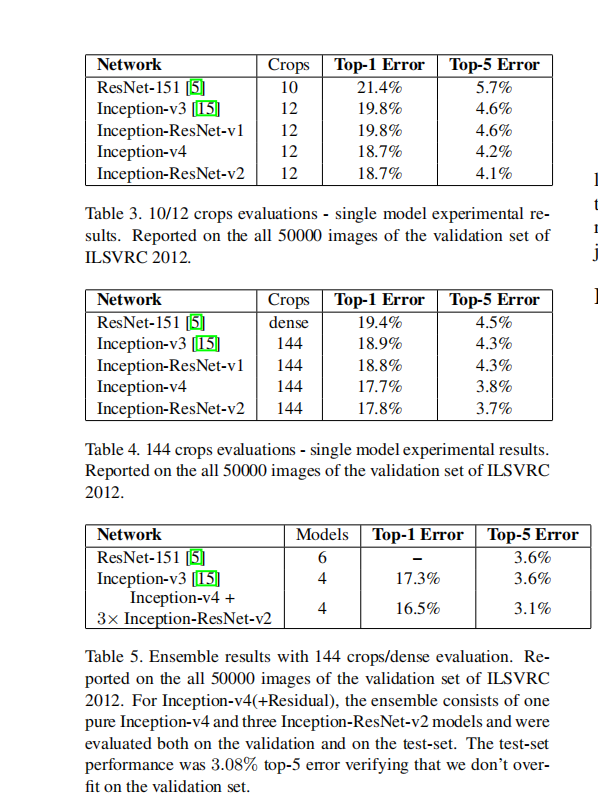
③ 结论
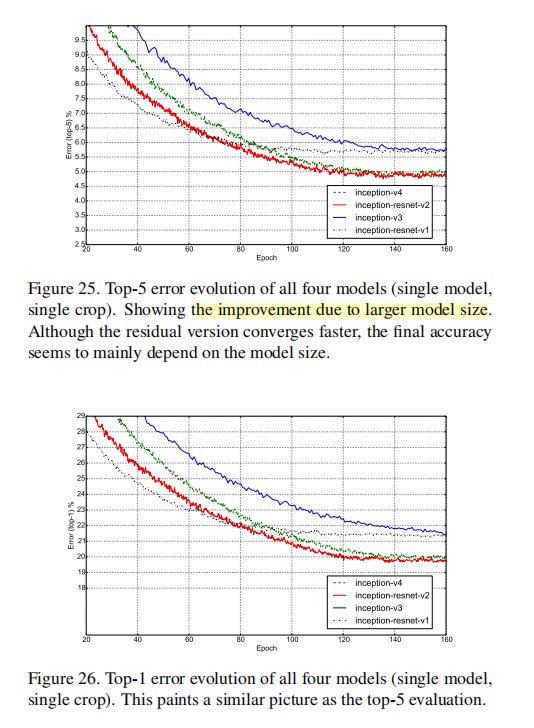
从实验中可以看出:
- Inception-ResNet-V2优于Inception-V4 优于 Inception-ResNet-V1
- 144crop优于12crop
- 模型集成中采用最优的模型进行集成 Inception-V4+3个Inception-ResNet-V2
- 本文方法优于ResNet论文方法
六、论文总结
① 关键点、创新点
- 将residual connection技术,引入到GoogLeNet系列中,提出Inception-ResNet结构网络
② 备用参考文献知识点
- 图像识别任务中,没有残差连接也可以训练深度卷积网络。
七、GoogLeNet系列论文回顾
四个GoogLeNet的比较:
v1: Inception模块,1×1卷积,多尺度卷积。22层
Inception模块:多尺度的卷积核对特佂图进行特征提取,再按照通道维度进行拼接。
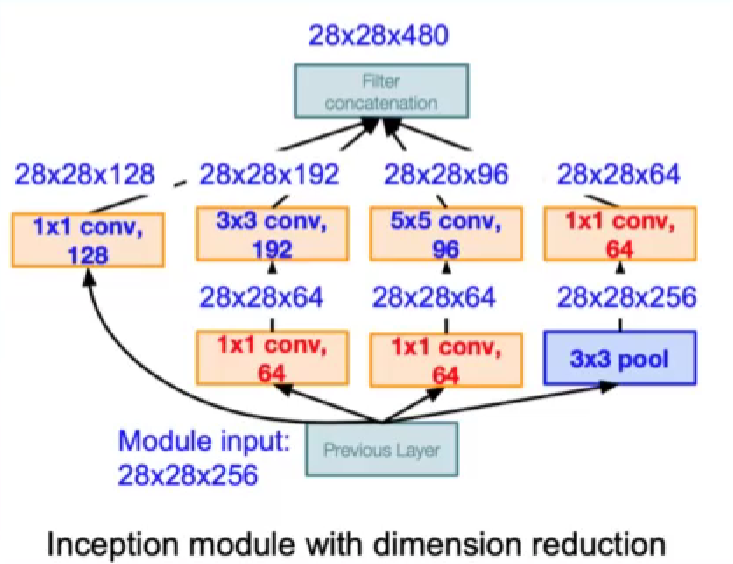
1×1卷积:压缩特征图的厚度
v2: 针对ICS问题,提出了BN技术。加速了模型训练的时间。31层,让标准化层成为深度神经网络的标配。
改进:
激活函数前加入BN;
5×5卷积替换为2个3×3卷积;(参数量变少)
第一个Inception模块前增加一个Inception结构;
尺寸变化采用stride = 2的卷积;
增加9层到31层
v3: 四个模型设计准则;两种卷积分解方式;特征图下降策略。
改进:
在v2的基础上,加上RMSProp、Label Smoothing、采用非对称卷积提取17×17特征图、采用带BN的辅助分类层。
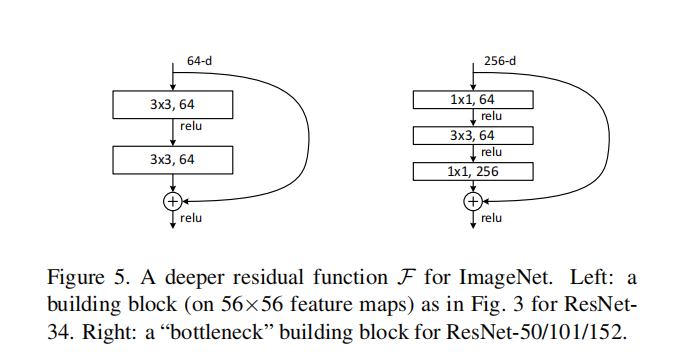
ResNet: 引入残差学习,成功训练超千层卷积神经网络。














 1083
1083











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









