







spark源码学习(五):stage的划分和task的创建
上一篇blog简单的阐述了和Resultstage和ActiveJob创建相关的源码,在这里我们接着上次没说完的submitStage,getMissingParentStages,submitMissingTasks两个函数开始.后面的这两个函数是在第一个函数里面调用的。
submitStage的代码在上一篇已经贴出来啦,首先来看看那个getMissingParentStages是什么:
private def getMissingParentStages(stage: Stage): List[Stage] = {
val missing = new HashSet[Stage]//保存没有被访问过的Stage
val visited = new HashSet[RDD[_]]//保存已经访问过的RDD
//手动的维护栈就是为了防止内存泄漏
val waitingForVisit = new Stack[RDD[_]]
def visit(rdd: RDD[_]) {
if (!visited(rdd)) {
visited += rdd if (getCacheLocs(rdd).contains(Nil)) {//会缓存RDD到内存去,会加快访问速度
for (dep <- rdd.dependencies) {
dep match {
case shufDep: ShuffleDependency[_, _, _] =>
val mapStage = getShuffleMapStage(shufDep, stage.jobId)
if (!mapStage.isAvailable) {
missing += mapStage
}
case narrowDep: NarrowDependency[_] =>
waitingForVisit.push(narrowDep.rdd)
}
}
}
}
}
waitingForVisit.push(stage.rdd)
while (waitingForVisit.nonEmpty) {
visit(waitingForVisit.pop())//递归的调用visit函数
}
missing.toList
}
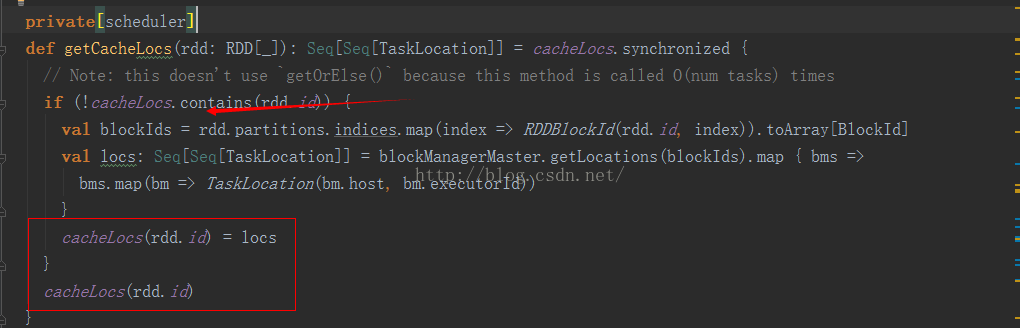
为了更加明白上面的那个函数,我们来看看这个变量cacheLocs吧,源码中的注释还挺详细的:
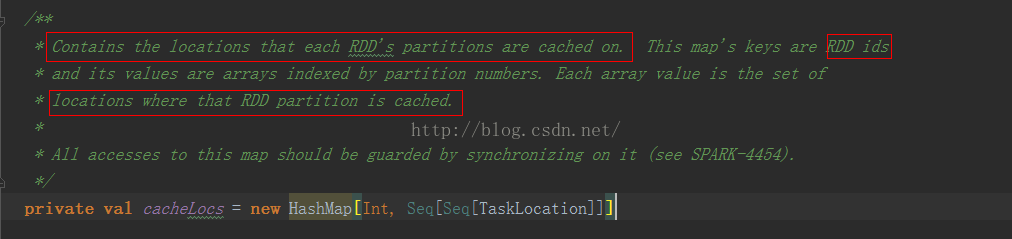
说的很明白,id就是所对应RDD的id,而values对应的是已经缓存之后每个rdd的partitions分别存放的位置。
(1)函数后面的contains(Nil)也就是为了容错处理吧,因为完整的队列后面都是以Nil结尾的嘛。在得到RDD的父依赖之后,依据依赖类型的不同对应不同的操作。如果是shuffle依赖就会得到一个新的stage叫做shuffleMapStage,如下:
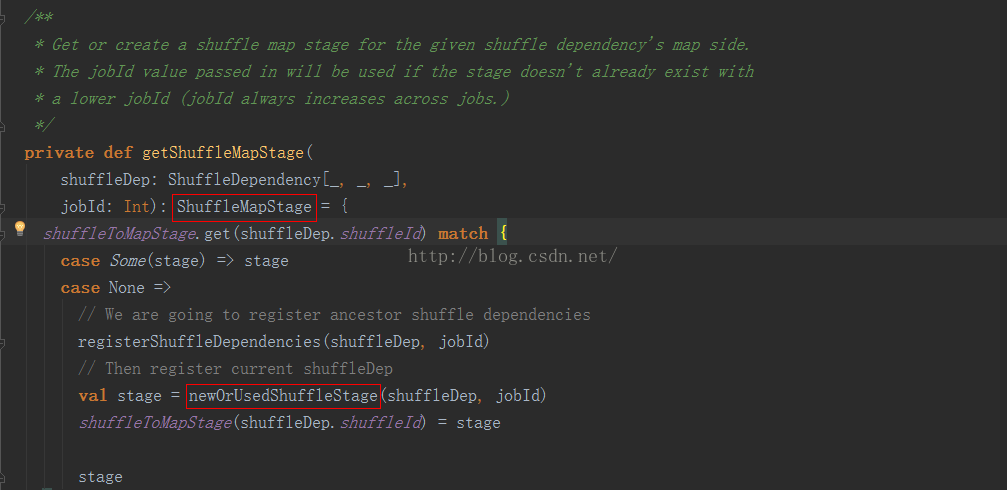
最核心的 newOrUsedShuffleStage就是用来创建一个新的shuffleMapStage的,具体的就不去深究啦。
(2)如果是窄依赖的话,就把当前的RDD放到waitingForVist的栈中,之后每次都会pop得到栈顶的RDD在进行同样的模式匹配工作,知道访问到最前面的那个RDD为止(当前stage的最前面的那个RDD)。我们会发现和stage相关的代码都是相同的code架构,对吧
说到这里,上面的getMissingParentStages就介绍完毕,下面继续来看看submitMissingTasks:这是重头戏
/** Called when stage's parents are available and we can now do its task. */
private def submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")")
// Get our pending tasks and remember them in our pendingTasks entry
stage.pendingTasks.clear()
// First figure out the indexes of partition ids to compute.
val partitionsToCompute: Seq[Int] = {
stage match {
case stage: ShuffleMapStage =>
(0 until stage.numPartitions).filter(id => stage.outputLocs(id).isEmpty)
case stage: ResultStage =>
val job = stage.resultOfJob.get
(0 until job.numPartitions).filter(id => !job.finished(id))
}
}
....省略
val properties = jobIdToActiveJob.get(stage.jobId).map(_.properties).orNull
runningStages += stage
var taskBinary: Broadcast[Array[Byte]] = null
try {//不同的依赖不同的序列化机制
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef).array()
case stage: ResultStage =>
closureSerializer.serialize((stage.rdd, stage.resultOfJob.get.func): AnyRef).array()
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {.....}
val tasks: Seq[Task[_]] = try {
stage match {//代码核心,不同的依赖不同的任务创建
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
val locs = getPreferredLocs(stage.rdd, id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, taskBinary, part, locs)
}
case stage: ResultStage =>
val job = stage.resultOfJob.get
partitionsToCompute.map { id =>
val p: Int = job.partitions(id)
val part = stage.rdd.partitions(p)
val locs = getPreferredLocs(stage.rdd, p)
new ResultTask(stage.id, taskBinary, part, locs, id)
}
}
} catch {...} 这个时候才会发现任务才是任务的创建,也就是说只有在全部的stage提交之后,才会去提交task的时候创建与之相对应的task,我们可以看到,task是在每个RDD所对应的partition上面去创建的是吧。(●'◡'●)至于shuffleMapTask和resultTask的创建,在这里就不说啦,以后有空再看看。到这里仅仅是涉及task相关的创建,关键是task如何提交和运行的呢?哈哈代码还没完。

这里就是就可以看到,就是taskScheduler把我们上面创建的tasks封装到一个taskSet中,然后再经过submitTask把任务提交给集群就可啦。具体的我们下次再看啦。















 1389
1389

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









