







Show and Tell: Lessons learned from the 2015 MSCOCO
Image Captioning Challenge代码
Image caption任务是给定一幅图像,用一幅图像来描述图像包含的信息。其中包含两方面的内容,图像特征提取和语句序列描述,其中CNN和RNN扮演重要角色。
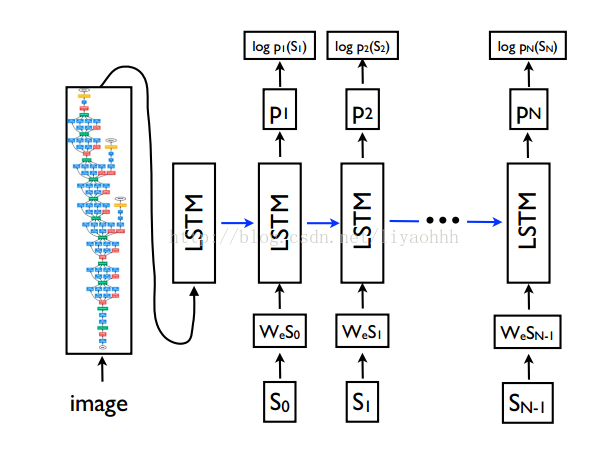
下图主要是将CNN提取的4096维度的图像特征作为LSTM的第一个输入,图像的内容描述作为其他时间序列的输入。LSTM主要是用来学习对应语句每个词语之间的依赖信息。
具体的表达式如下图所示:

如下图所示,需要把高维4096的图像特征和每个one-hot单词编码到固定维度,然后将描述信息作为LSTM的输入

具体代码如下
#-*- coding: utf-8 -*-
import math
import os
import tensorflow as tf
import numpy as np
import pandas as pd
import cPickle
from tensorflow.models.rnn import rnn_cell
import tensorflow.python.platform
from keras.preprocessing import sequence
from collections import Counter
from cnn_util import *
class Caption_Generator():
def init_weight(self, dim_in, dim_out, name=None, stddev=1.0):
return tf.Variable(tf.truncated_normal([dim_in, dim_out], stddev=stddev/math.sqrt(float(dim_in))), name=name)
def init_bias(self, dim_out, name=None):
return tf.Variable(tf.zeros([dim_out]), name=name)
def __init__(self, dim_image, dim_embed, dim_hidden, batch_size, n_lstm_steps, n_words, bias_init_vector=None):
self.dim_image = np.int(dim_image) # 图像维度
self.dim_embed = np.int(dim_embed) # dim_embed和dim_hidden的维度相同,用于编码词向量
self.dim_hidden = np.int(dim_hidden) # LSTMcell中神经元的个数
self.batch_size = np.int(batch_size)
self.n_lstm_steps = np.int(n_lstm_steps) #序列长度
self.n_words = np.int(n_words)
with tf.device("/cpu:0"):#编码词向量到固定为度
self.Wemb = tf.Variable(tf.random_uniform([n_words, dim_embed], -0.1, 0.1), name='Wemb')
self.bemb = self.init_bias(dim_embed, name='bemb')
self.lstm = rnn_cell.BasicLSTMCell(dim_hidden)#初始化LSTMCell
#self.encode_img_W = self.init_weight(dim_image, dim_hidden, name='encode_img_W')
#编码图像特征到固定为度
self.encode_img_W = tf.Variable(tf.random_uniform([dim_image, dim_hidden], -0.1, 0.1), name='encode_img_W')
self.encode_img_b = self.init_bias(dim_hidden, name='encode_img_b')
#将输出的结果恢复到词向量空间
self.embed_word_W = tf.Variable(tf.random_uniform([dim_hidden, n_words], -0.1, 0.1), name='embed_word_W')
if bias_init_vector is not None:
self.embed_word_b = tf.Variable(bias_init_vector.astype(np.float32), name='embed_word_b')
else:
self.embed_word_b = self.init_bias(n_words, name='embed_word_b')
def build_model(self):#用于train
image = tf.placeholder(tf.float32, [self.batch_size, self.dim_image])#图像维度
sentence = tf.placeholder(tf.int32, [self.batch_size, self.n_lstm_steps])#对应的图像标签(语句信息描述)
mask = tf.placeholder(tf.float32, [self.batch_size, self.n_lstm_steps])#mask(非1则0) 用于最终计算Loss
#将图像特征编码到固定的维度
image_emb = tf.matmul(image, self.encode_img_W) + self.encode_img_b # (batch_size, dim_hidden)
state = tf.zeros([self.batch_size, self.lstm.state_size])# state的初始化,state_size大小为2(c,h),初始化为0
loss = 0.0
with tf.variable_scope("RNN"):
for i in range(self.n_lstm_steps): # maxlen + 1
if i == 0:
current_emb = image_emb# t=-1时刻的LSTM的出入:图像编码特征
else:
with tf.device("/cpu:0"): #词向量编码固定维度,这里sentence[:,i-1]的i-1表示第一个词语
current_emb = tf.nn.embedding_lookup(self.Wemb, sentence[:,i-1]) + self.bemb
if i > 0 : tf.get_variable_scope().reuse_variables()
#LSTM的输出状态信息
output, state = self.lstm(current_emb, state) # (batch_size, dim_hidden)
if i > 0:
#labels表示每个batch的第i个单词
labels = tf.expand_dims(sentence[:, i], 1) # (batch_size)-->(batch_size,1)
#indices表示对于labels的索引
indices = tf.expand_dims(tf.range(0, self.batch_size, 1), 1)#(batch_size)-->batch_size,1)
#(batch_indices,labels)
concated = tf.concat(1, [indices, labels])
#将concated编码为one-hot矩阵,1表示以tf.pack([self.batch_size, self.n_words]为索引指定为1,其他设定为0
onehot_labels = tf.sparse_to_dense(
concated, tf.pack([self.batch_size, self.n_words]), 1.0, 0.0) # (batch_size, n_words)
#LSTM的输出结果
logit_words = tf.matmul(output, self.embed_word_W) + self.embed_word_b # (batch_size, n_words)
#计算Loss损失结果
cross_entropy = tf.nn.softmax_cross_entropy_with_logits(logit_words, onehot_labels)
cross_entropy = cross_entropy * mask[:,i]#计算损失
current_loss = tf.reduce_sum(cross_entropy)
loss = loss + current_loss
loss = loss / tf.reduce_sum(mask[:,1:])
return loss, image, sentence, mask
def build_generator(self, maxlen):#用于test阶段,maxlen表示输出的结果语句的最大长度
image = tf.placeholder(tf.float32, [1, self.dim_image])
image_emb = tf.matmul(image, self.encode_img_W) + self.encode_img_b
state = tf.zeros([1, self.lstm.state_size])
#last_word = image_emb
generated_words = []
with tf.variable_scope("RNN"):
#t=-1时刻出入信息为image_feature
output, state = self.lstm(image_emb, state)
#self.Wemb表示embed的词向量(n_word,embed)
last_word = tf.nn.embedding_lookup(self.Wemb, [0]) + self.bemb
for i in range(maxlen):
tf.get_variable_scope().reuse_variables()
#t=0时刻 LSTM的输出
output, state = self.lstm(last_word, state)
#将输出结果映射到原始的词向量空间
logit_words = tf.matmul(output, self.embed_word_W) + self.embed_word_b
#计算last_word和image为前提条件下,计算当前时刻有可能输出的最大概率。max_prob_word是索引
max_prob_word = tf.argmax(logit_words, 1)
with tf.device("/cpu:0"):
last_word = tf.nn.embedding_lookup(self.Wemb, max_prob_word)
last_word += self.bemb
generated_words.append(max_prob_word)
return image, generated_words














 871
871

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









