






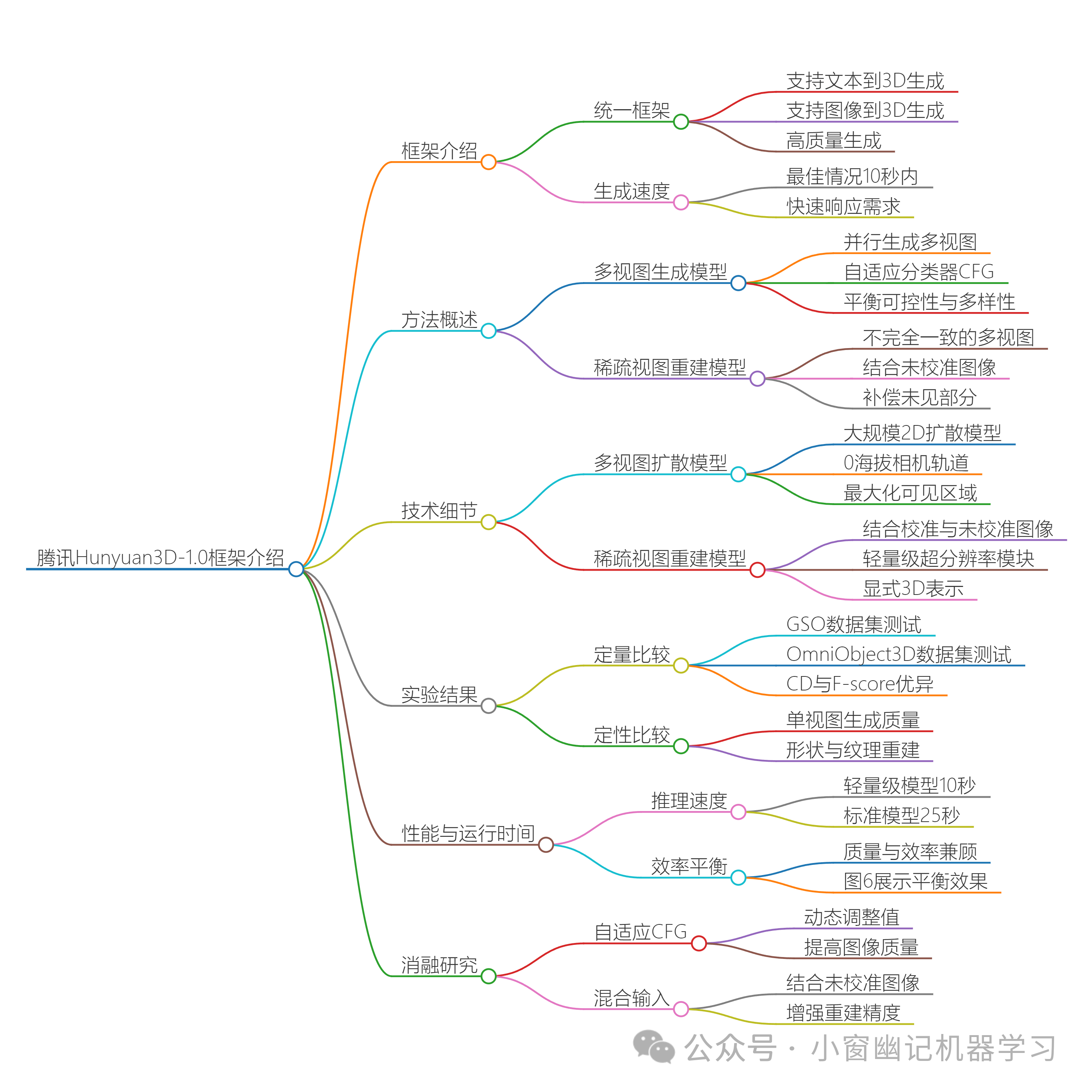
以下简单介绍腾讯的Hunyuan3D-1.0框架,该框架统一了文本到3D和图像到3D生成的流程,能够在短时间内生成高质量的3D资产。以下是文章的主要内容:
1.框架介绍
统一框架:Hunyuan3D-1.0是一个统一的框架,支持高质量的文本和图像条件下的3D生成。生成速度:该框架在最佳情况下能够在10秒内完成3D生成。
2.方法概述
多视图生成模型:通过并行生成多视图图像来增强3D信息的理解,使用自适应分类器自由指导(CFG)来平衡不同视图的可控性和多样性。稀疏视图重建模型:利用不完全一致的多视图图像恢复底层3D形状,结合未校准的条件图像作为辅助输入以补偿生成图像中未见部分。
3.技术细节
多视图扩散模型:使用大规模的2D扩散模型生成多视图图像,设置0海拔相机轨道以最大化生成视图之间的可见区域。稀疏视图重建模型:结合校准和未校准的输入图像,使用轻量级超分辨率模块和显式3D表示来实现高质量的3D重建。
4.实验结果
定量比较:在GSO和OmniObject3D数据集上进行定量比较,Hunyuan3D-1.0在CD(Chamfer Distance)和F-score指标上表现优异,尤其是标准版本。定性比较:在单视图生成方面,Hunyuan3D-1.0在形状和纹理的重建质量上优于现有方法。 5.性能与运行时间
推理速度:轻量级模型在NVIDIA A100 GPU上从单个图像生成3D网格大约需要10秒,标准模型大约需要25秒。效率平衡:Hunyuan3D-1.0在质量和效率之间实现了最佳平衡,如图6所示。
6.消融研究
自适应CFG:动态调整CFG在不同视图和时间步长的值,显著提高了图像质量。混合输入:通过结合未校准的条件图像显著增强了未见部分的重建精度。
通过这些创新设计,Hunyuan3D-1.0在3D生成任务中实现了最先进的性能,并验证了其鲁棒性和效率。
生成脑图结果:

















 230
230

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









