






今天分享一下使用AI编程工具cursor,来通过MCPserver连接mysql数据库,实现通过自然语言对数据库进行操作
模型上下文协议(Model Context Protocol,MCP),是由 Anthropic推出的开源协议 ,旨在实现大语言模型与外部数据源和工具的集成,用来在大模型和数据源之间建立安全双向的连接 。
配置MCPserver。打开cursor,点击右上角设置,选择mcp,添加一个mcpserver
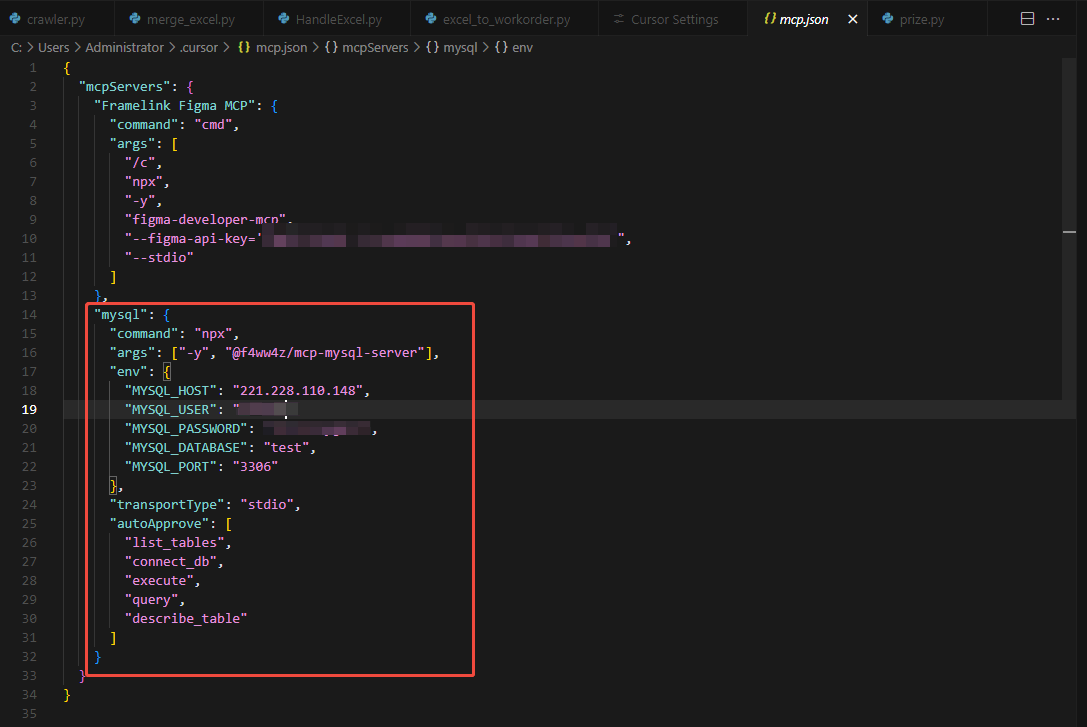
{
"mcpServers": {
"mysql": {
"command": "npx",
"args": ["-y", "@f4ww4z/mcp-mysql-server"],
"env": {
"MYSQL_HOST": "221.228.110.148",
"MYSQL_USER": "xxxx",
"MYSQL_PASSWORD": "xxxx",
"MYSQL_DATABASE": "test",
"MYSQL_PORT": "3306"
},
"transportType": "stdio",
"autoApprove": [
"list_tables",
"connect_db",
"execute",
"query",
"describe_table"
]
}
}
}保存以后我们看到如果左边出现一个绿色的点就表示连接成功了。如果出现红色的点,则需要根据异常日志逐步解决。一般可能是数据库连接地址或者账号密码错误,或者npm安装mcp-mysql-server的时候出错了。可以将异常贴到cursor去寻求解决。
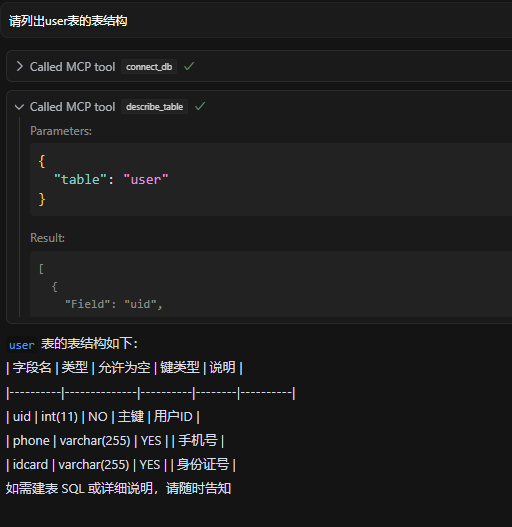
连接成功以后就可以在对话框操作数据库了。我们先尝试一下列举表结构
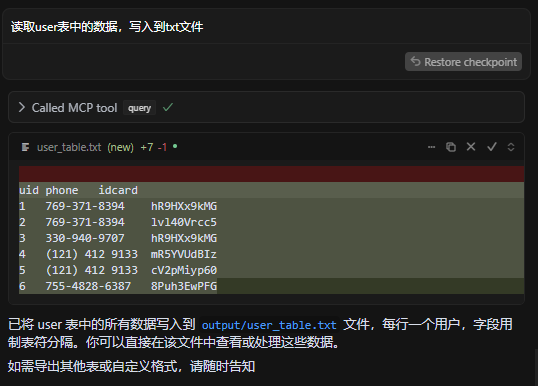
我们来读取表的数据写入到txt文件
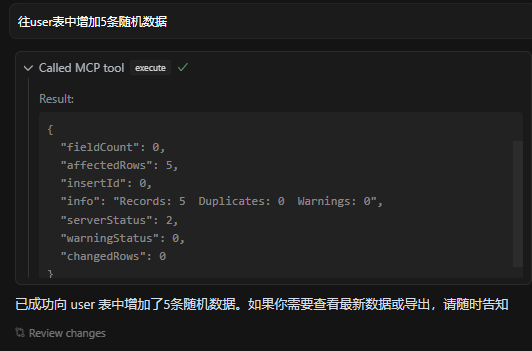
增加一些测试数据
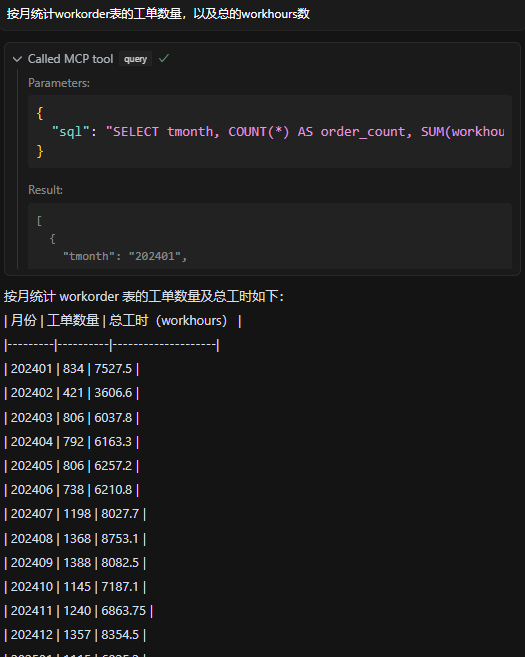
也可以做一些统计工作
以上就是通过MCPserver让自然语言来处理数据库操作,只是一些简单的示例,当然还可以通过读取数据库信息来编写相关代码,大家可以去深入研究和使用。

















 1888
1888

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









