








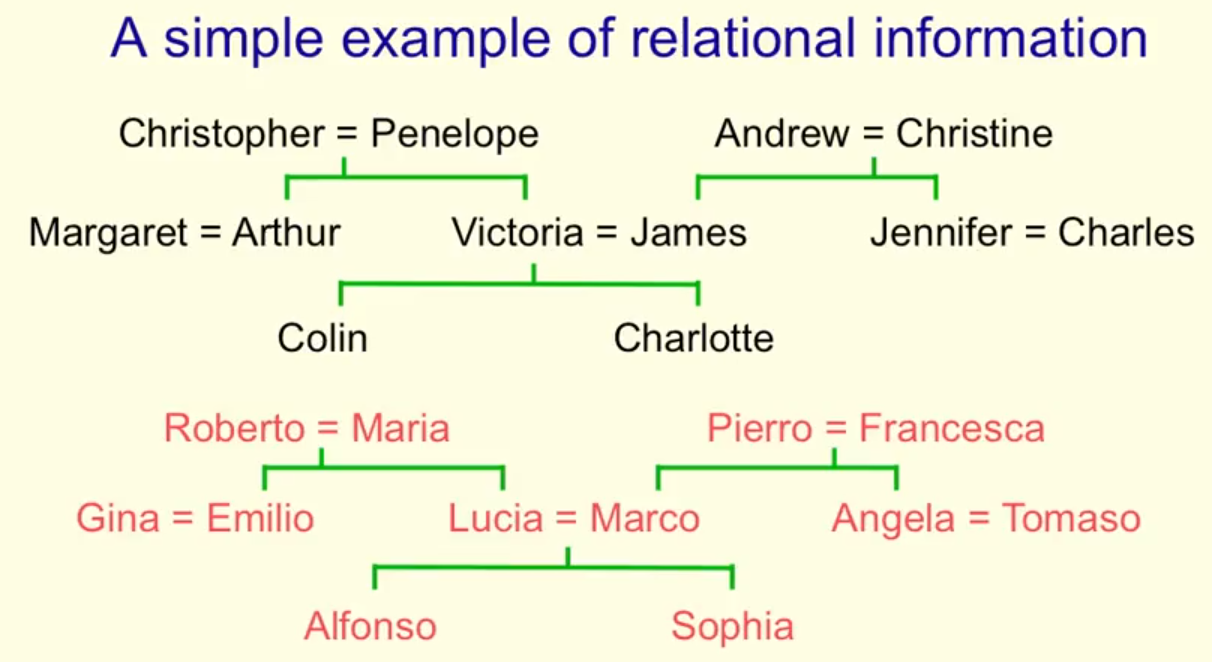
24个人表示成24维向量,除了一个,其余都是0:
Colin =(1,0,0,0,…,0),Charlotte = (0,0,1,0…,0)
为什么不用更简单的表示呢,比如计算机中的二进制(5维可表示)?
Colin =(0,0,0,0,1), Charlotte = (0,0,0,1,1)
24维表示法使得输入线性可分
24维表示法不需要先验知识
样本:一个英国家庭,一个意大利家庭
共112个元组:(C122 - 2*C42)*2 (因为Margaret&Arthur和Andrew&Christine没有关系)


输入:person1 relationship
输入:与person1有关系relationship的person2
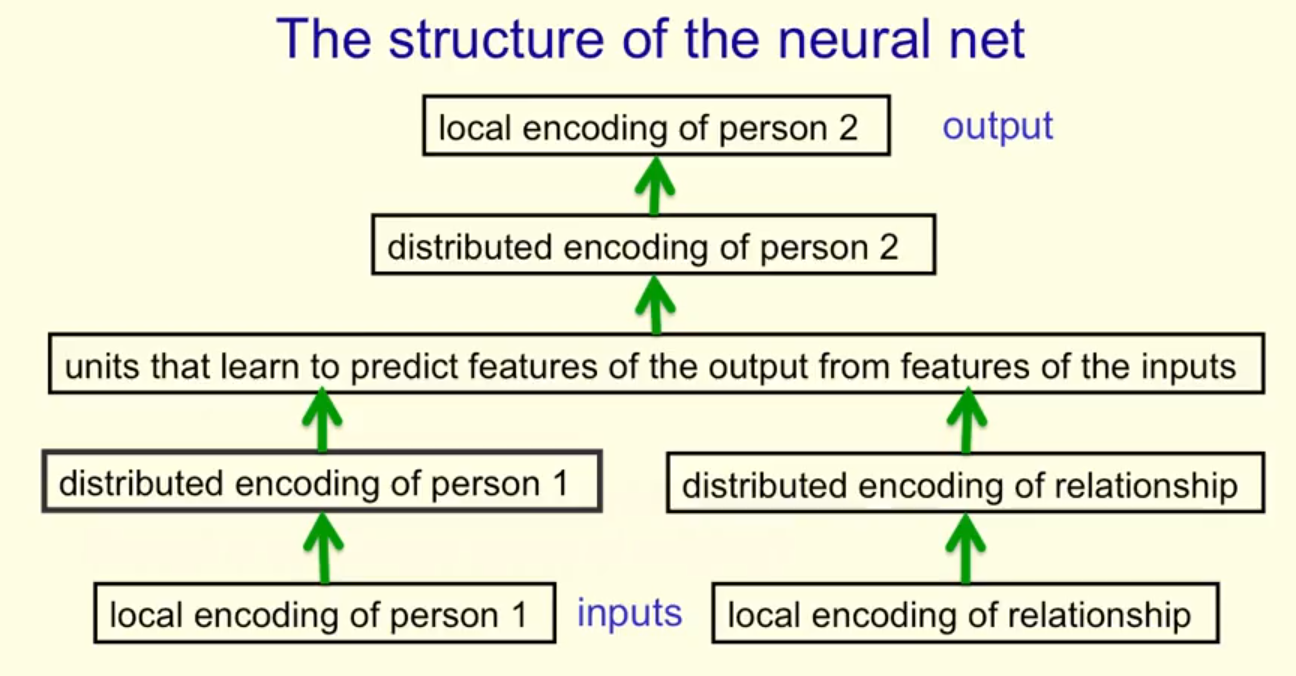

特点
【不同家庭】:图中右上角,白色方块表示了英国家庭的人,黑色方块表示了意大利家庭的人。
【一代人】:老一代人是很强的正样本,新一代人是很强的负样本,中间的一代的权重接近于0。是三个取值的特征。
【家谱】:左下角,黑色方块,暗示了这些人都属于右边的家谱成员。
Background-propagation可以学习到一些有趣的特征。
Question:
A RB 给出人A和关系R预测B,与给图片分类有什么不同?

The Softmax Output Function
使神经网络的输出总和为1
可以表示为一些互斥变量的概率分布 (discrete mutually exclusive alternatives)
平方误差估计的缺点:
- 如果希望输出的是1,实际输出0,00000001,那么几乎没有梯度可以更改权重的值,即使已经是最大错误。
- 如果我们对互斥事件计算概率,那总和应该是1,但是平方误差估计并没有体现。
强迫输出和为1——softmax

TIPS:任何分布的变量,加上一个常数C,其分布都不变,因为只是横坐标移动。
交叉熵代价函数(cross entropy cost function)
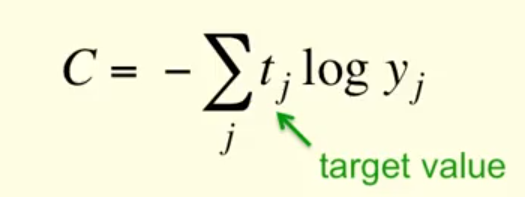
C总有很大的导数
____________________________________________________________________________________________
Speech Recognition
problem:
噪音
人们的理解 recognizespeech / wreck a nice beach
所以语音识别器必须知道下一个出现的单词可能是什么。
'trigram' method
根据一个庞大的词汇数据元组(很多2个词的组合),来预测下一个词的概率是多少

trigrammodel并不理解相似词之间的关系,所以用语义句法的特征向量来预测。
这样每个元组可以拥有更多的前词(e.g:10个)

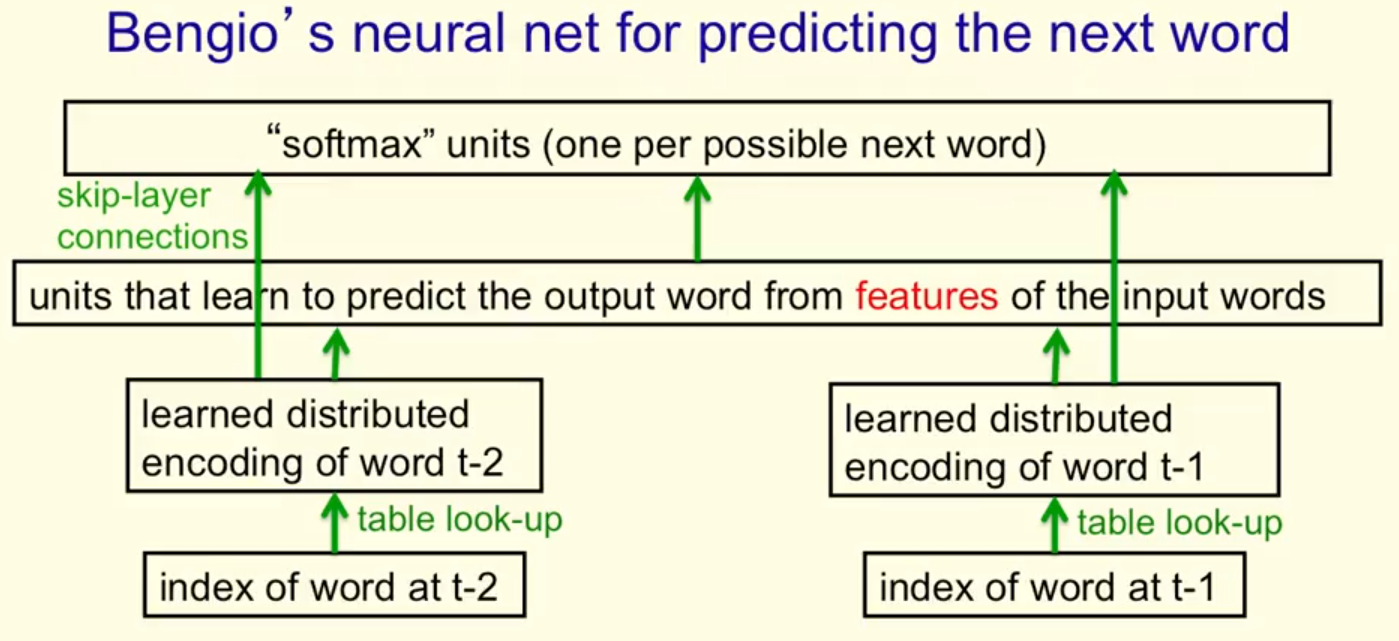
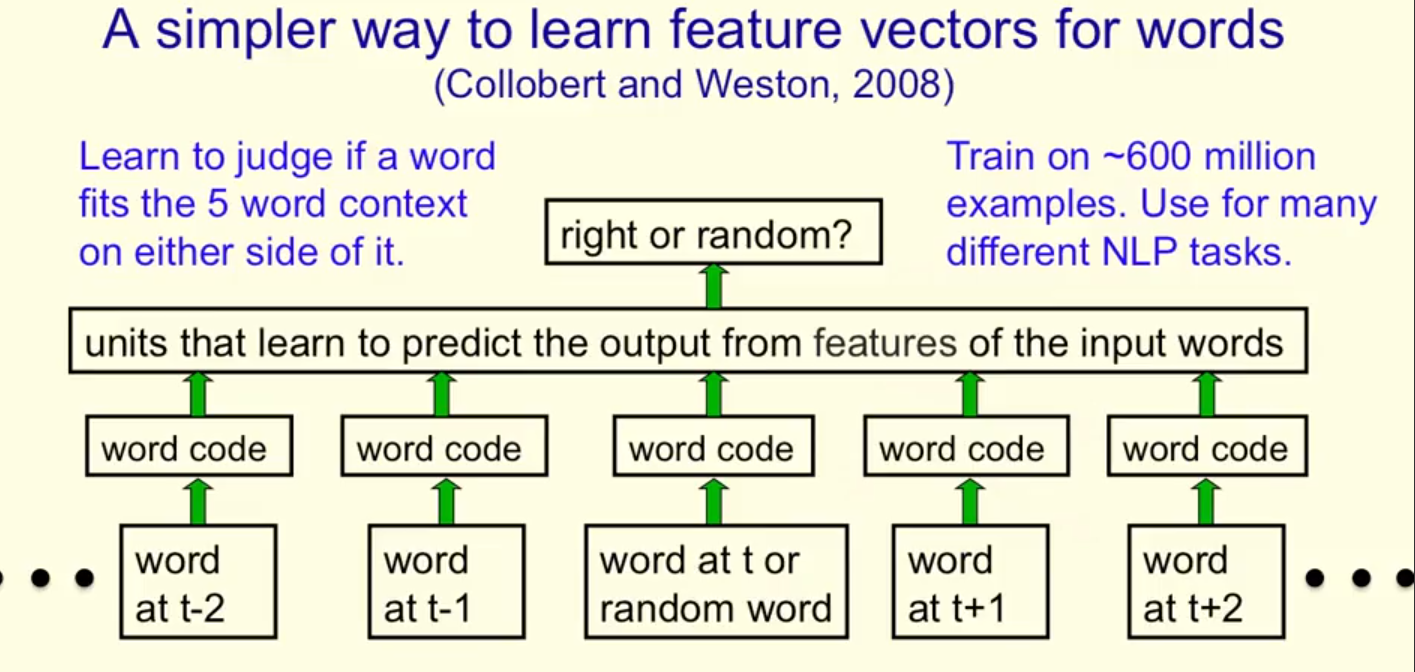
Ways to deal with the largenumber of possible outputs in neuro-probabilistic language models.
如何解决最后一层输出过多?
- Serial architecture
在上述结构的基础上,添加了候选单词,输出就是候选单词的概率


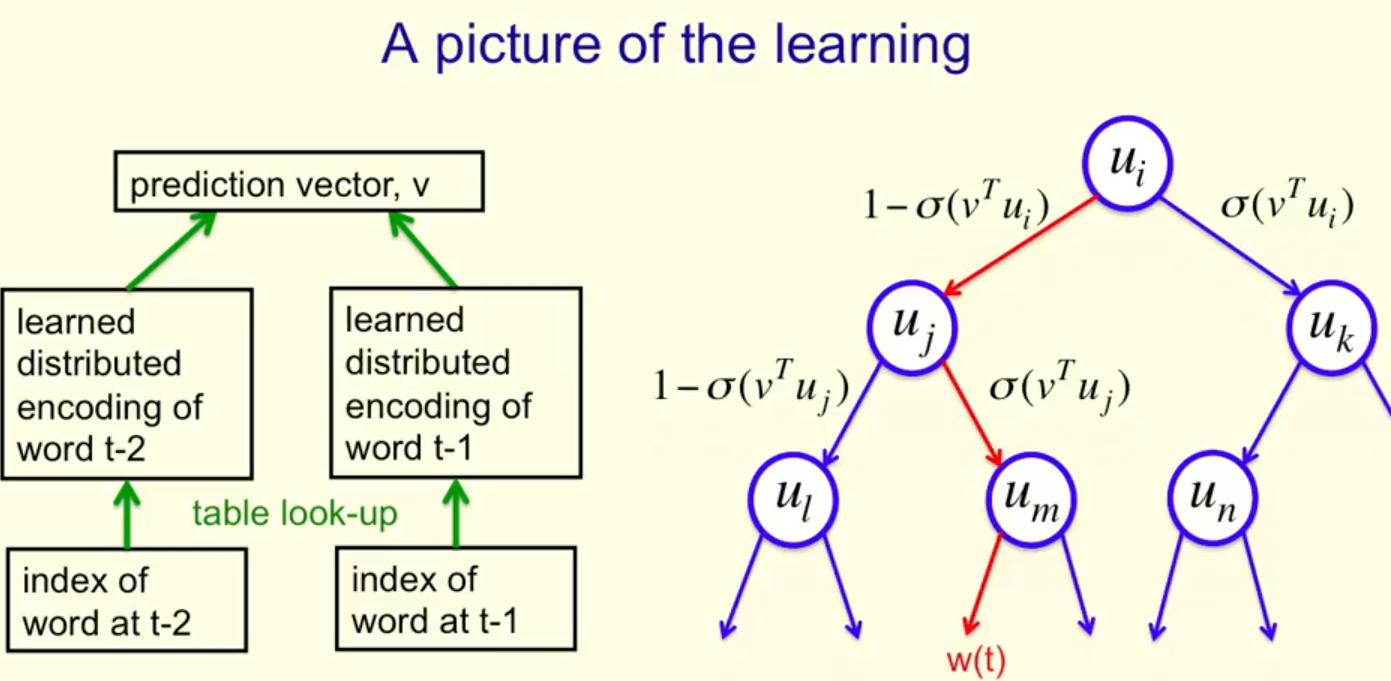
- 将单词构造成一个二叉树
将预测向量与树枝上的向量做比较,决定选择左枝还是右枝

t-SNE
用2-D展示学习到的向量
















 4966
4966

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









