







1.前言
逻辑回归模型虽然名字是回归,但是实际上是一种二类(0或1)分类模型。在本文中,0代表负类,1代表正类。逻辑模型的输入为样本的特征向量 x \boldsymbol{x} x,输出为 P ( y = 1 ∣ x ) P(y=1|\boldsymbol{x}) P(y=1∣x)和 P ( y = 0 ∣ x ) P(y=0|\boldsymbol{x}) P(y=0∣x),即在输入特征向量为 x \boldsymbol{x} x条件下,样本标签属于某一类的概率。因为本文讨论的只是二类分类模型,所以有 P ( y = 1 ∣ x ) + P ( y = 0 ∣ x ) = 1 P(y=1|\boldsymbol{x})+P(y=0|\boldsymbol{x})=1 P(y=1∣x)+P(y=0∣x)=1。在实际使用过程中,一般是需要指定一个阈值,比如0.5,如果逻辑回归模型的输出 P ( y = 1 ∣ x ) ≥ 0.5 P(y=1|\boldsymbol{x}) \ge 0.5 P(y=1∣x)≥0.5,则认为此样本为正类,如果 P ( y = 1 ∣ x ) < 0.5 P(y=1|\boldsymbol{x}) < 0.5 P(y=1∣x)<0.5,则认为样本为负类。当然阈值是根据实际需求设置的,如果对正类的要求比较严格,则可以将阈值设的高一点,比如0.7。
2.逻辑回归模型
首先我们来说一下线性回归,我们知道线性回归是用一个一元方程来拟合输入
x
\boldsymbol{x}
x与输出
y
y
y之间的关系:
y
=
w
⋅
x
+
b
y=\boldsymbol{w} \cdot \boldsymbol{x}+b
y=w⋅x+b那我们能不能直接将
P
(
y
=
1
∣
x
)
P(y=1|\boldsymbol{x})
P(y=1∣x)看作
y
y
y带入上式来构成逻辑回归模型呢?即:
P
(
y
=
1
∣
x
)
=
w
⋅
x
+
b
P(y=1|\boldsymbol{x})=\boldsymbol{w} \cdot \boldsymbol{x}+b
P(y=1∣x)=w⋅x+b这样显然不合理,因为等式的左边为概率,取值应该为
0
≤
P
(
y
=
1
∣
x
)
≤
1
0 \le P(y=1|\boldsymbol{x}) \le 1
0≤P(y=1∣x)≤1,而等式右边的取值范围为
[
−
∞
,
+
∞
]
[-\infty,+\infty]
[−∞,+∞]。所以应该找一个函数,将等式右边的取值范围从
[
−
∞
,
+
∞
]
[-\infty,+\infty]
[−∞,+∞]映射到
[
0
,
1
]
[0,1]
[0,1]上,这个函数就是sigmoid函数,其数学表达式如下,其函数图像见下图:
σ
(
z
)
=
1
1
+
exp
(
−
z
)
=
exp
(
z
)
1
+
exp
(
z
)
\sigma(\boldsymbol{z})=\frac{1}{1+\text{exp}(-z)}=\frac{\text{exp}(z)}{1+\text{exp}(z)}
σ(z)=1+exp(−z)1=1+exp(z)exp(z)
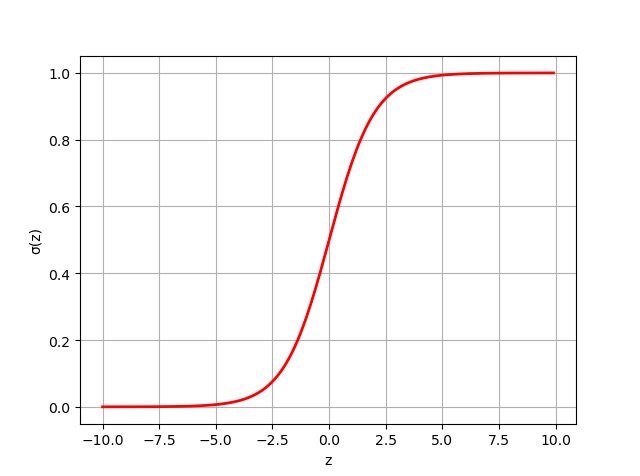
将等式的右边作为
z
z
z带入到sigmoid函数中,便得到了逻辑回归模型:
P
(
y
=
1
∣
x
)
=
exp
(
w
⋅
x
+
b
)
1
+
exp
(
w
⋅
x
+
b
)
P
(
y
=
0
∣
x
)
=
1
1
+
exp
(
w
⋅
x
+
b
)
P(y=1|\boldsymbol{x})=\frac{\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}+b)}{1+\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}+b)} \\ P(y=0|\boldsymbol{x})=\frac{1}{1+\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}+b)}
P(y=1∣x)=1+exp(w⋅x+b)exp(w⋅x+b)P(y=0∣x)=1+exp(w⋅x+b)1有了模型之后,接下来我们就要讨论如何求解模型参数
w
\boldsymbol{w}
w和
b
b
b,为了后面推导方便,我们将参数模型参数
w
\boldsymbol{w}
w和
b
b
b合并为一个向量,还是记为
w
\boldsymbol{w}
w,同时为了保持维度一致,将输入向量也进行扩充即:
w
=
(
w
(
1
)
,
w
(
2
)
,
.
.
.
,
w
(
n
)
)
,
b
)
T
x
=
(
x
(
1
)
,
x
(
2
)
,
.
.
.
,
x
(
n
)
,
1
)
T
\boldsymbol{w}=(w^{(1)},w^{(2)},...,w^{(n)}),b)^T \\ \boldsymbol{x}=(x^{(1)},x^{(2)},...,x^{(n)},1)^T
w=(w(1),w(2),...,w(n)),b)Tx=(x(1),x(2),...,x(n),1)T此时,逻辑回归模型就可以写为:
P
(
y
=
1
∣
x
)
=
σ
(
x
)
=
exp
(
w
⋅
x
)
1
+
exp
(
w
⋅
x
)
P
(
y
=
0
∣
x
)
=
1
−
σ
(
x
)
=
1
1
+
exp
(
w
⋅
x
)
P(y=1|\boldsymbol{x})=\sigma(\boldsymbol{x})=\frac{\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x})}{1+\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x})} \\ P(y=0|\boldsymbol{x})=1-\sigma({\boldsymbol{x}})=\frac{1}{1+\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x})}
P(y=1∣x)=σ(x)=1+exp(w⋅x)exp(w⋅x)P(y=0∣x)=1−σ(x)=1+exp(w⋅x)1
3.损失函数
3.1 交叉熵损失函数
为了求解模型的最优参数,我们首先要找到合适的损失函数,并极小化损失函数,当损失最小时,此时的参数就是最优参数。我们首先想到的是线性回归所使用的损失函数,即均方误差:
L
(
w
)
=
1
2
∑
i
=
1
N
(
σ
(
x
i
)
−
y
i
)
2
L(\boldsymbol{w})=\frac{1}{2}\sum_{i=1}^{N}(\sigma(\boldsymbol{x}_i)-y_i)^2
L(w)=21i=1∑N(σ(xi)−yi)2但是逻辑回归处理的是分类问题,
y
i
y_i
yi不是0就是1,而不是线性回归中的连续的数,所以均方误差在这里可能是一个非凸函数,则如下图所示,图片来源于吴恩达的机器学习课程的笔记,图中的
J
(
θ
)
J(\theta)
J(θ)为损失函数。这就意味着损失函数有很多局部最小值,无法确保能通过梯度下降算法找到全局最优值。
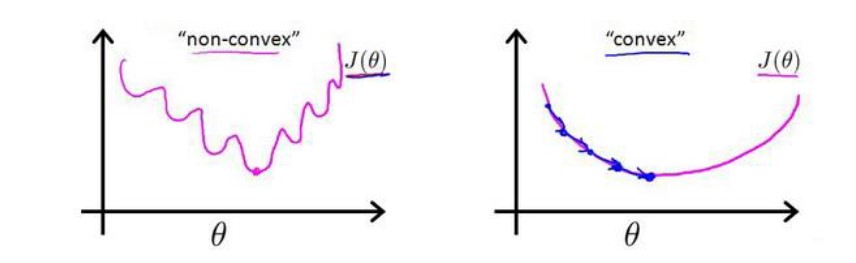
所以均方误差将不适用于逻辑回归模型。
实际上,逻辑回归使用的是交叉熵损失函数,其数学表达式如下:
L
(
w
)
=
∑
i
=
1
N
[
−
y
i
ln
(
σ
(
x
i
)
)
−
(
1
−
y
i
)
ln
(
1
−
σ
(
x
i
)
)
]
L(\boldsymbol{w})=\sum_{i=1}^{N}[-y_i\text{ln}(\sigma(\boldsymbol{x}_i))-(1-y_i)\text{ln}(1-\sigma(\boldsymbol{x}_i))]
L(w)=i=1∑N[−yiln(σ(xi))−(1−yi)ln(1−σ(xi))]交叉熵损失函数的特点就是:当样本真实标签
y
i
=
1
y_i=1
yi=1时,损失函数第二项就为0,逻辑回归模型的输出
σ
(
x
i
)
\sigma(\boldsymbol{x}_i)
σ(xi)越接近1,则损失越小,当
σ
(
x
i
)
=
1
\sigma(\boldsymbol{x}_i)=1
σ(xi)=1时,损失为0;同理,当样本真实标签
y
i
=
0
y_i=0
yi=0时,损失函数第一项就为0,逻辑回归模型的输出
σ
(
x
i
)
\sigma(\boldsymbol{x}_i)
σ(xi)越接近0,则损失越小,当
σ
(
x
i
)
=
0
\sigma(\boldsymbol{x}_i)=0
σ(xi)=0时,损失为0。交叉熵损失函数被广泛应用于分类任务中,不仅适用于二分类,而且适用于多分类。
3.2 从极大似然估计角度理解损失函数
其实也可以从极大似然估计的角度来理解逻辑回归模型的损失函数。首先,我们写出模型的似然函数:
∏
i
=
1
N
[
σ
(
x
i
)
]
y
i
[
1
−
σ
(
x
i
)
1
−
y
i
]
\prod_{i=1}^{N}[\sigma(\boldsymbol{x}_i)]^{y_i}[1-\sigma(\boldsymbol{x}_i)^{1-y_i}]
i=1∏N[σ(xi)]yi[1−σ(xi)1−yi]则对数似然函数为:
L
(
w
)
=
∑
i
=
1
N
[
y
i
ln
(
σ
(
x
i
)
)
+
(
1
−
y
i
)
ln
(
1
−
σ
(
x
i
)
)
]
L(\boldsymbol{w})=\sum_{i=1}^{N}[y_i\text{ln}(\sigma(\boldsymbol{x}_i))+(1-y_i)\text{ln}(1-\sigma(\boldsymbol{x}_i))]
L(w)=i=1∑N[yiln(σ(xi))+(1−yi)ln(1−σ(xi))]可以发现对数似然函数就是负的交叉熵损失函数。其实二者的意思相同,只不过从损失函数的角度,我们是要极小化损失函数,而从极大似然估计的角度,我们是要使对数似然函数最大。后面的公式推导中,我们将采用极小化交叉熵损失函数求解模型参数。
4.模型参数求解
4.1 梯度下降法
为了求导方便,我们首先对损失函数进行化简:
L
(
w
)
=
−
∑
i
=
1
N
[
y
i
ln
(
σ
(
x
i
)
)
+
(
1
−
y
i
)
ln
(
1
−
σ
(
x
i
)
]
=
−
∑
i
=
1
N
[
y
i
ln
(
σ
(
x
i
)
1
−
σ
(
x
i
)
)
+
ln
(
1
−
σ
(
x
i
)
)
]
=
−
∑
i
=
1
N
[
y
i
ln
(
exp
(
w
⋅
x
)
)
+
ln
(
1
1
+
exp
(
w
⋅
x
)
)
]
=
−
∑
i
=
1
N
[
y
i
(
w
⋅
x
)
−
ln
(
1
+
exp
(
w
⋅
x
)
)
]
L(\boldsymbol{w})=-\sum_{i=1}^{N}[y_i\text{ln}(\sigma(\boldsymbol{x}_i))+(1-y_i)\text{ln}(1-\sigma(\boldsymbol{x}_i)] \\ =-\sum_{i=1}^{N}[y_i\text{ln}(\frac{\sigma(\boldsymbol{x}_i)}{1-\sigma(\boldsymbol{x}_i)})+\text{ln}(1-\sigma(\boldsymbol{x}_i))] \\ =-\sum_{i=1}^{N}[y_i\text{ln}(\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}))+\text{ln}(\frac{1}{1+\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x})})] \\ =-\sum_{i=1}^{N}[y_i(\boldsymbol{w} \cdot \boldsymbol{x})-\text{ln}(1+\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}))]
L(w)=−i=1∑N[yiln(σ(xi))+(1−yi)ln(1−σ(xi)]=−i=1∑N[yiln(1−σ(xi)σ(xi))+ln(1−σ(xi))]=−i=1∑N[yiln(exp(w⋅x))+ln(1+exp(w⋅x)1)]=−i=1∑N[yi(w⋅x)−ln(1+exp(w⋅x))]下面开始求
L
(
w
)
L(\boldsymbol{w})
L(w)对
w
\boldsymbol{w}
w的梯度:
∇
w
L
(
w
)
=
−
∑
i
=
1
N
(
y
i
x
i
−
exp
(
w
⋅
x
i
)
1
+
exp
(
w
⋅
x
i
)
x
i
)
=
−
∑
i
=
1
N
(
y
i
−
exp
(
w
⋅
x
i
)
1
+
exp
(
w
⋅
x
i
)
)
x
i
=
∑
i
=
1
N
(
exp
(
w
⋅
x
i
)
1
+
exp
(
w
⋅
x
i
)
−
y
i
)
x
i
=
∑
i
=
1
N
(
σ
(
x
i
)
−
y
i
)
x
i
\nabla_{\boldsymbol{w}}L(\boldsymbol{w})=-\sum_{i=1}^{N}(y_i\boldsymbol{x}_i-\frac{\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}_i)}{1+{\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}_i)}}\boldsymbol{x}_i) \\ =-\sum_{i=1}^{N}(y_i-\frac{\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}_i)}{1+{\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}_i)}})\boldsymbol{x}_i \\ =\sum_{i=1}^{N}(\frac{\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}_i)}{1+{\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}_i)}}-y_i)\boldsymbol{x}_i \\ =\sum_{i=1}^{N}(\sigma(\boldsymbol{x}_i)-y_i)\boldsymbol{x}_i
∇wL(w)=−i=1∑N(yixi−1+exp(w⋅xi)exp(w⋅xi)xi)=−i=1∑N(yi−1+exp(w⋅xi)exp(w⋅xi))xi=i=1∑N(1+exp(w⋅xi)exp(w⋅xi)−yi)xi=i=1∑N(σ(xi)−yi)xi有了梯度之后就可以利用梯度下降来更新模型参数了,即:
w
=
w
−
η
∇
w
L
(
w
)
\boldsymbol{w}=\boldsymbol{w}-\eta\nabla_{\boldsymbol{w}}L(\boldsymbol{w})
w=w−η∇wL(w)其中,
η
\eta
η表示学习率。梯度下降的代码如下:
#训练,梯度下降
def train(self, train_data, train_label):
print("start to train")
for iter in range(self.max_iter):
#用for循环一行一行的实现梯度下降
for i in range(len(train_data)):
x = np.array([train_data[i]])
y = train_label[i]
wx = np.dot(x, self.w)
self.w -= self.learning_rate*(np.exp(wx)/ ( 1 + np.exp(wx))) - y) * x.T
#直接用矩阵实现
#计算 w*x
# wx = np.dot(train_data, self.w)
# #计算梯度
# gradient = np.dot(train_data.T, (self.sigmoid(wx) - train_label))
# #更新权值
# self.w -= self.learning_rate*gradient
print("training completed")
print("w is {}".format(self.w))
4.2 牛顿法
牛顿法的原理可以参考李航《统计学习方法》的附录B部分,这里就不详述了。利用牛顿法更新模型参数的公式如下:
w
=
w
−
H
−
1
∇
w
L
(
w
)
\boldsymbol{w}=\boldsymbol{w}-H^{-1}\nabla_{\boldsymbol{w}}L(\boldsymbol{w})
w=w−H−1∇wL(w)其中H使Hessian矩阵,Hessian矩阵即一阶梯度
∇
w
L
(
w
)
\nabla_{\boldsymbol{w}}L(\boldsymbol{w})
∇wL(w)对
w
T
\boldsymbol{w}^T
wT的梯度,其求解公式如下:
H
=
∇
w
T
(
∇
w
L
(
w
)
)
=
∇
w
T
(
∑
i
=
1
N
(
σ
(
x
i
)
−
y
i
)
x
i
)
=
∇
w
T
(
∑
i
=
1
N
(
exp
(
w
⋅
x
i
)
1
+
exp
(
w
⋅
x
i
)
)
x
i
)
=
∑
i
=
1
N
x
i
T
(
exp
(
w
⋅
x
i
)
(
1
+
exp
(
w
⋅
x
i
)
)
−
exp
(
w
⋅
x
i
)
2
[
1
+
exp
(
w
⋅
x
i
)
]
2
)
x
i
=
∑
i
=
1
N
x
i
T
σ
(
x
i
)
(
1
−
σ
(
x
i
)
)
x
i
H=\nabla_{\boldsymbol{w}^T}(\nabla_{\boldsymbol{w}}L(\boldsymbol{w})) \\ =\nabla_{\boldsymbol{w}^T}(\sum_{i=1}^{N}(\sigma(\boldsymbol{x}_i)-y_i)\boldsymbol{x}_i) \\ =\nabla_{\boldsymbol{w}^T}(\sum_{i=1}^{N}(\frac{\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}_i)}{1+{\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}_i)}})\boldsymbol{x}_i) \\ =\sum_{i=1}^{N}\boldsymbol{x}_i^T(\frac{\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}_i)(1+\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}_i))-\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}_i)^2}{[1+\text{exp}(\boldsymbol{w} \cdot \boldsymbol{x}_i)]^2})\boldsymbol{x}_i \\ =\sum_{i=1}^{N}\boldsymbol{x}_i^T\sigma(\boldsymbol{x}_i)(1-\sigma(\boldsymbol{x}_i))\boldsymbol{x}_i
H=∇wT(∇wL(w))=∇wT(i=1∑N(σ(xi)−yi)xi)=∇wT(i=1∑N(1+exp(w⋅xi)exp(w⋅xi))xi)=i=1∑NxiT([1+exp(w⋅xi)]2exp(w⋅xi)(1+exp(w⋅xi))−exp(w⋅xi)2)xi=i=1∑NxiTσ(xi)(1−σ(xi))xi上述求导过程中用到了列向量对行向量的导数,在《矩阵理论》课程里有讲到。
求得Hessian矩阵后便可以对模型参数进行更新了,代码如下:
#训练,牛顿法
def train(self, train_data, train_label):
print("start to train")
for iter in range(self.max_iter):
#一行一行的求解
for i in range(len(train_data)):
# 因为取出的x是个1维数组,无法进行转置,所以将其扩充为2维
x = np.array([train_data[i]])
y = train_label[i]
wx = np.dot(x, self.w)
#计算一阶导数
gradient = np.dot(x.T, (self.sigmoid(wx) - y))
#计算Hessian矩阵
Hessian = np.dot(x.T, self.sigmoid(wx)).dot((1 - self.sigmoid(wx))).dot(x)
#权值更新
self.w -= self.learning_rate * np.linalg.pinv(Hessian).dot(gradient)
print("training completed")
print("w is {}".format(self.w))
5.参考资料
1.李航《统计学习方法》
2.https://www.cnblogs.com/veraLin/p/10003400.html
3.https://www.sohu.com/a/270954377_777125
4.https://github.com/fengdu78/lihang-code
推荐阅读:
SMO算法求解支持向量机的理论推导与代码实现
机器学习算法——支持向量机(3)
机器学习算法——支持向量机(2)
机器学习算法——支持向量机(1)
也欢迎大家关注我的公众号:MyLearningNote

















 6039
6039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











