







要谈DEC算法,首先得从问题背景出发,DEC算法其实同k-means一样,都是一种聚类算法,属于无监督学习的一种。那我们为什么要引入这么一个算法,道理也简单,自然是我们之前的算法有其局限性。
聚类算法中的一个核心便是距离函数,可以是欧氏距离,也可以是特征之间的某种关系,但k-means等算法对距离函数的处理往往局限于原始数据空间,这也就导致,如同组会上学姐学长所说,输入维度较高时,往往无效。而DEC聚类算法则解决了这一问题,这得益于它的设计框架和独特的实现过程。
DEC通过同时学习特征空间Z中的k个聚类中心和将数据点映射到Z的DNN的参数 θ 来聚类数据。
DEC具有两个阶段:( 1)使用自动编码器进行参数初始化(AE),
(2)参数优化(即聚类),其中我们在计算辅助目标分布和最小化Kullback-Leibler(KL)散度之间进行迭代。
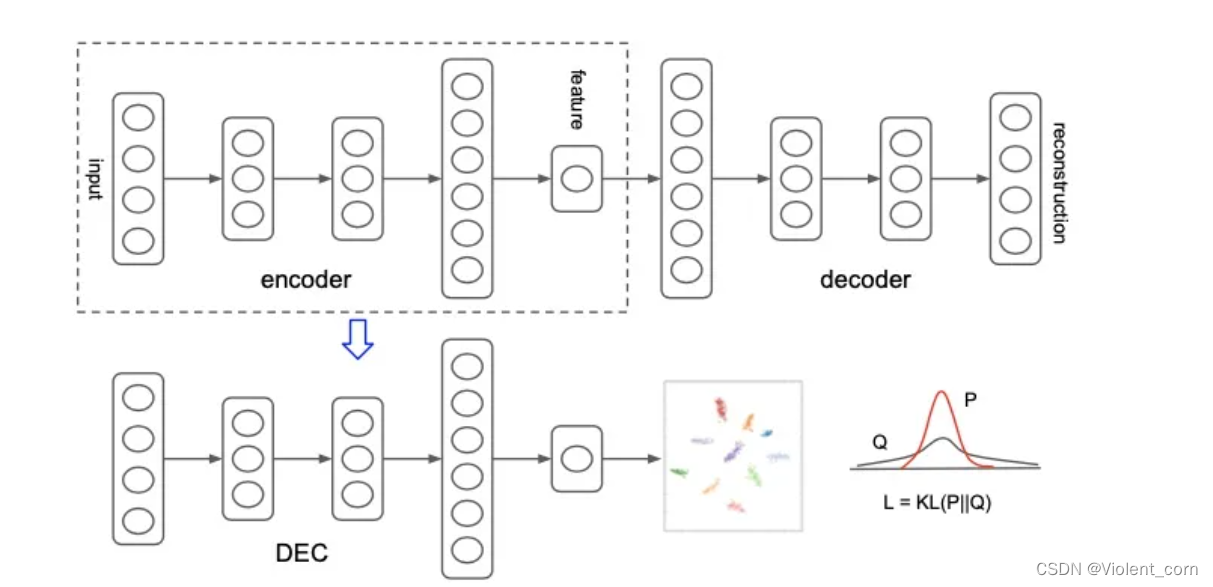
如上图:
1. 使用深度学习自编码进行参数初始化
2.选取AE模型中的Encoder部分,加入聚类层,使用KL散度进行训练聚类
即先将特征压缩,构造软分布和辅助分布,(p,q)
迭代过程如下
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 359
359

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









