







 本文介绍了评分卡模型开发中异常值处理的重要性,包括单变量离群值检测、局部离群值因子检测和基于k-means聚类的离群值检测方法,并展示了在R中实现这些方法的代码示例。处理异常值后,可得到适合模型开发的数据集。
本文介绍了评分卡模型开发中异常值处理的重要性,包括单变量离群值检测、局部离群值因子检测和基于k-means聚类的离群值检测方法,并展示了在R中实现这些方法的代码示例。处理异常值后,可得到适合模型开发的数据集。
用户数据缺失值处理见上篇:
http://blog.csdn.net/lll1528238733/article/details/76599626
缺失值处理完毕后,我们还需要进行异常值处理。异常值是指明显偏离大多数抽样数据的数值,比如个人客户的年龄大于100时,通常认为该值为异常值。找出样本总体中的异常值,通常采用离群值检测的方法。
离群值检测的方法有单变量离群值检测、局部离群值因子检测、基于聚类方法的离群值检测等方法。由于本文采用的样本总体GermanCredit已经进行了数据预处理,即已经做了缺失值和异常值处理,因此,我们以随机产生的样本为例来说明离群值检测的方法。
(1)第一种方法是单变量离群值检测,该方法的原理是通过求解单变量数值的第1个和第3个四分位数的值,将数值小于第1个四分位数和大于第3个四分位数的值定义为离群值。该方法可通过R包grDevices中的boxplot.stats()函数实现。
我们用随机数来演示获取异常值的方法,代码如下:
> set.seed(1100) #设置获取随机数的种子
> x<-rnorm(100) #生成100个随机数,并检测异常值
> summary(x)
Min. 1st Qu. Median Mean 3rd Qu. Max.
-2.2951 -0.4288 0.1981 0.1243 0.6693 2.3804
> boxplot.stats(x)$out #检测并输出异常值
[1] 2.380427 -2.295102
> boxplot(x)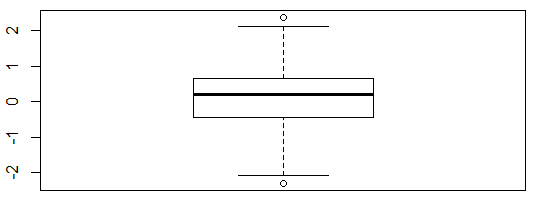
图3.1 箱图表示的异常值
上述单变量离群值检测方法也可简单地应用到多变量的数据集上。下例中,我们简单地将该方法扩展到在二维数据框中检测离群值。我们先分别在两列数据上进行离群值检测,再从检测出的离群值中抽取重叠的部分作为二位数据框的离群值点,在如3.2中用“+”表示离群值点。代码如下:
set.seed(1100)
x<-rnorm(100)
y<-rnorm(100)
df<-data.frame(x,y) #将x,y两个随机序列组成数据框
rm(x,y) #删除x,y两个变量
attach(df)
(a<-which(x %in%boxplot.stats(x)$out))
(b<-which(y %in%boxplot.stats(y)$out))
detach(df)
(outlier1<-intersect(a,b))
plot(df)
points(df[outlier1,],col="red",pch="+",cex=2.0)
#将离群值用红色的“+”表示我们可以看到不存在这样的离群值。
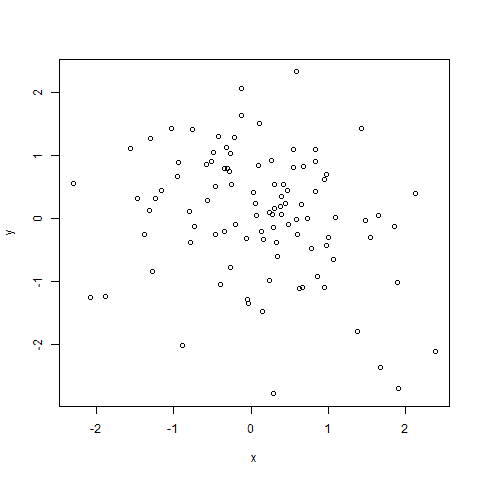
图3.2 二维数据框的离群值检测结果
当然,我们可将变量x和y的离群值都作为整个数据框的离群值,如图3.3所示,离群值用“*”表示。代码如下:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









